
本文第一作者为四川大学博士研究生刘泓麟,邮箱为[email protected],通讯作者为四川大学李云帆博士后与四川大学彭玺教授。
一张图片包含的信息是多维的。例如下面的图 1,我们至少可以得到三个层面的信息:主体是大象,数量有两头,环境是热带稀树草原(savanna)。然而,如果由传统的表征学习方法来处理这张图片,比方说就将其送入一个在 ImageNet 上训练好的 ResNet 或者 Vision Transformer,往往得到的表征只会体现其主体信息,也就是会简单地将该图片归为大象这一类别。这显然是不合理的。
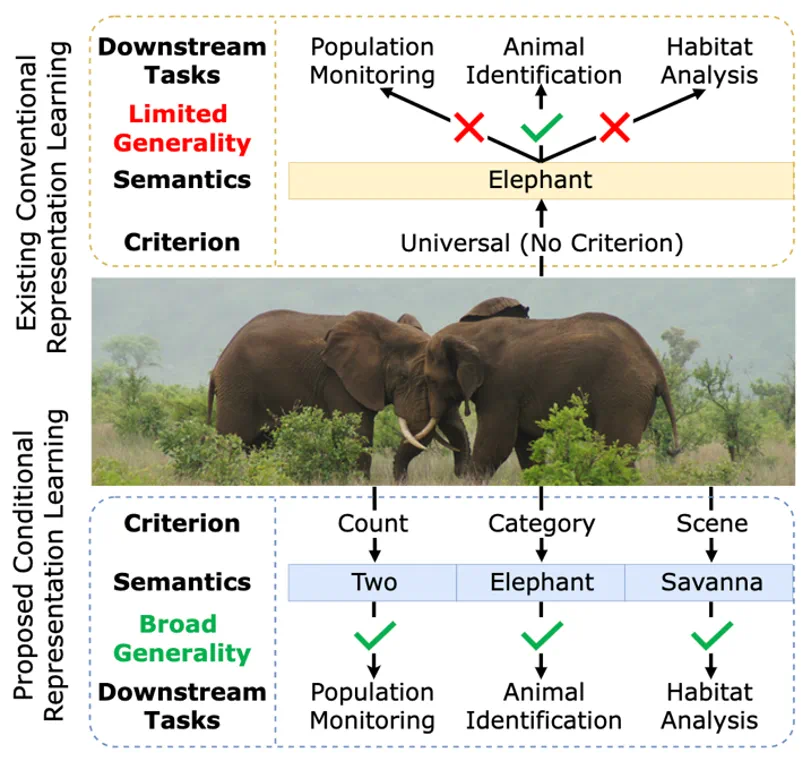
图 1:传统表征学习(上)与条件表征学习(下)的比较。传统的表征学习方法只能学习到一种通用的表征,忽略了其他有意义的信息;文章提出的条件表征学习能够基于指定准则,得到该准则下表现力更强的条件表征,适应多种下游任务。
此外,在各大电商平台,用户通常根据不同的标准(例如颜色、材质或场合)搜索商品。例如,用户今天可能搜索 “红色连衣裙”,明天搜索 “正装”,后天搜索某个全新的关键词。这对于拥有庞大规模商品的平台来说,手动打标签是不现实的,而传统的表征学习也仅仅只能获取到 “连衣裙” 这个层面的信息。
要获取图片中除了 “大象”、“连衣裙” 之外的信息,一个很容易想到的方法就是进行针对性的有监督训练:基于不同的准则比如环境,进行额外的标注,再从头训练或者基于已有表征训练一个额外的线性层。但是基于这种方式,显然是 “治标不治本” 的。因为一旦有了新的需求,便又需要进行针对性的数据收集、标注和训练,需要付出大量的时间和人力成本。
很幸运的,我们处在多模态大模型的时代,这个在以前可能会很困难的问题在今天是有很多解法的。我们可以直接通过询问 LLaVA,它便会告诉我们图片在指定准则下的信息。但这种方式也还不够高效,至少在 2025 年的今天,多模态大模型的使用成本还是需要考虑的。如果需要处理 ImageNet 之类的大规模数据集或者电商平台繁杂的商品,得到其在指定准则下的信息,这个开销就比较大了。所以对大多数人来说,现如今要获取图片的多维信息,还是需要找到一个更加高效的方法。

论文标题:Conditional Representation Learning for Customized Tasks
论文链接:https://arxiv.org/abs/2510.04564
代码链接:https://github.com/XLearning-SCU/2025-NeurIPS-CRL
方法
我们知道,对于三维直角坐标系,一组基,比如 [(1, 0, 0), (0, 1, 0), (0, 0, 1)],其线性组合即可构建出该坐标系中的任何向量。类似的,对于颜色体系,只需要 “红”、“绿”、“蓝” 三原色即可调出所有的颜色。
受此启发,我们想到,是否对于任意一个给定的准则,也存在着一个对应的 “概念空间” 及其基?如果能在这个空间中找到一组基,那么我们只需要将原始表征投影到该空间上,理论上就能获得在该准则下更具表现力和判别性的特征。
找到给定准则对应的基,这听起来有些困难。但没关系,我们不需要很准确地找到,只需要接近它就好。
基于这个想法,论文提出了一种即插即用的条件表征学习方法。如图 2 所示,给定准则(例如 “颜色”),CRL 首先让大语言模型 LLM 生成该准则相关的描述文本(例如 “红色”,“蓝色” 和 “绿色” 等)。随后,CRL 将由 VLM 得到的通用图片表征,投影到由描述文本张成的空间中,得到该准则下的条件表征。该表征在指定的准则下表达更充分,并且具有更优的可解释性,能有效适应下游定制化任务。
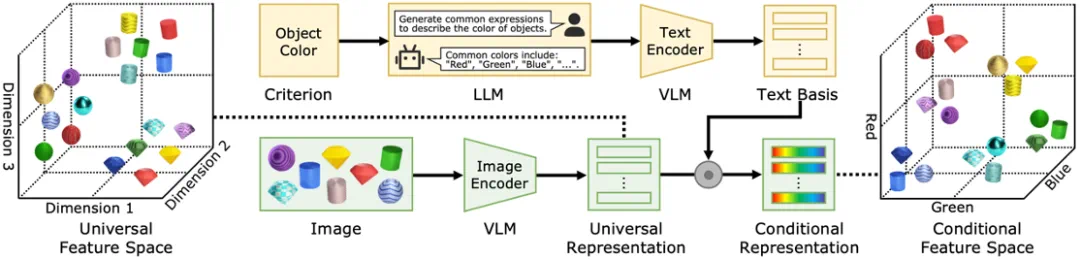
图 2:所提出的条件表征学习(CRL)的总体框架。图中以通用表征空间(准则为隐式的 “形状”)转换到 “颜色” 准则空间为例。
直白地说,只需要将对齐的图片和文本表征,做个矩阵乘法就好了,甚至不需要训练。复现难度约等于:

实验
分类和检索任务是衡量表征学习性能的两个经典下游任务。论文在两个分类任务(少样本分类、聚类)和两个检索任务(相似度检索、服装检索)上进行了充分的实验验证,部分实验结果如下:
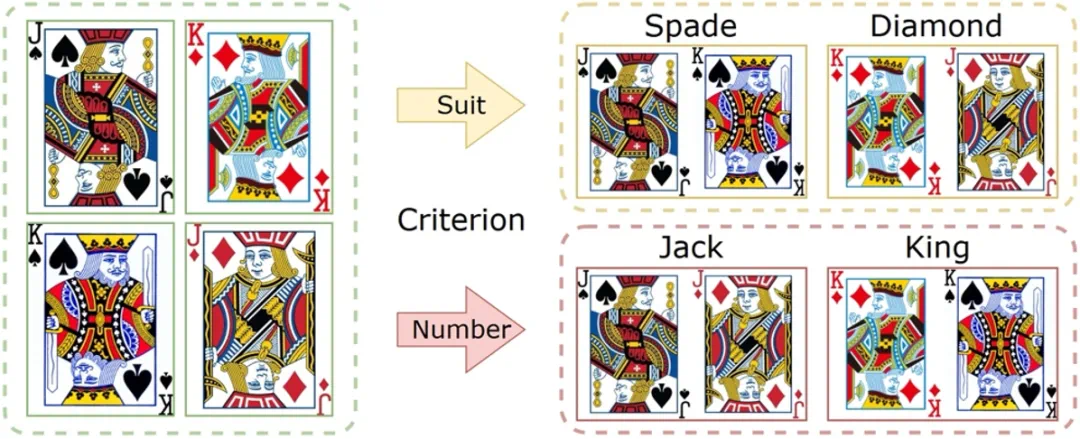
图 3:分类任务
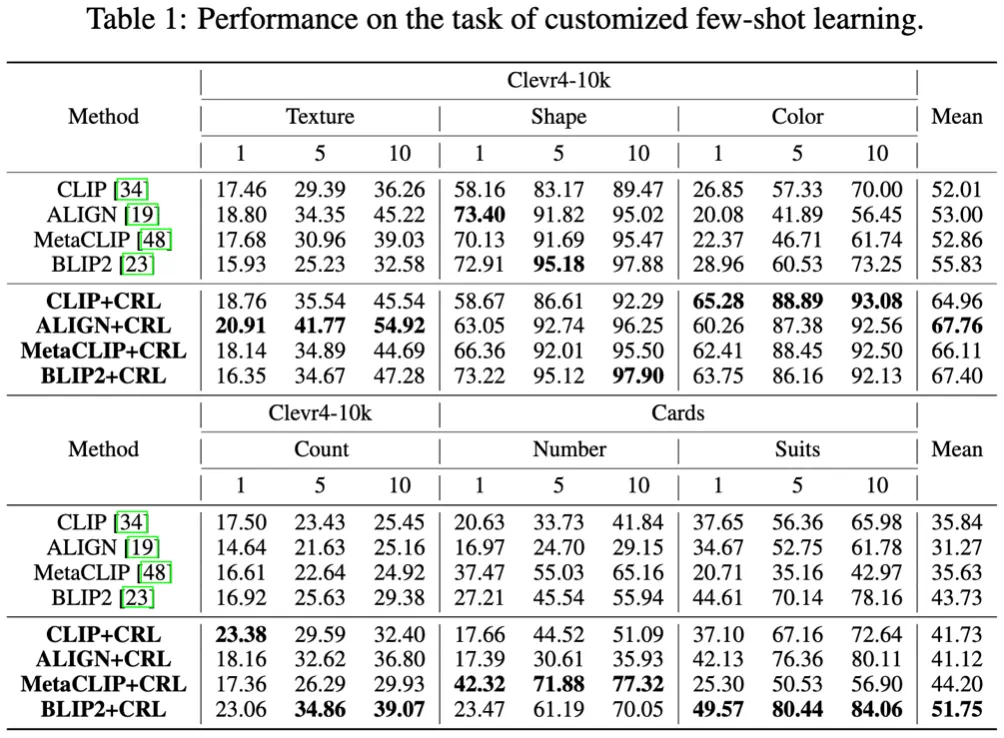
表 1:所提出的 CRL 在少样本分类任务上的性能。
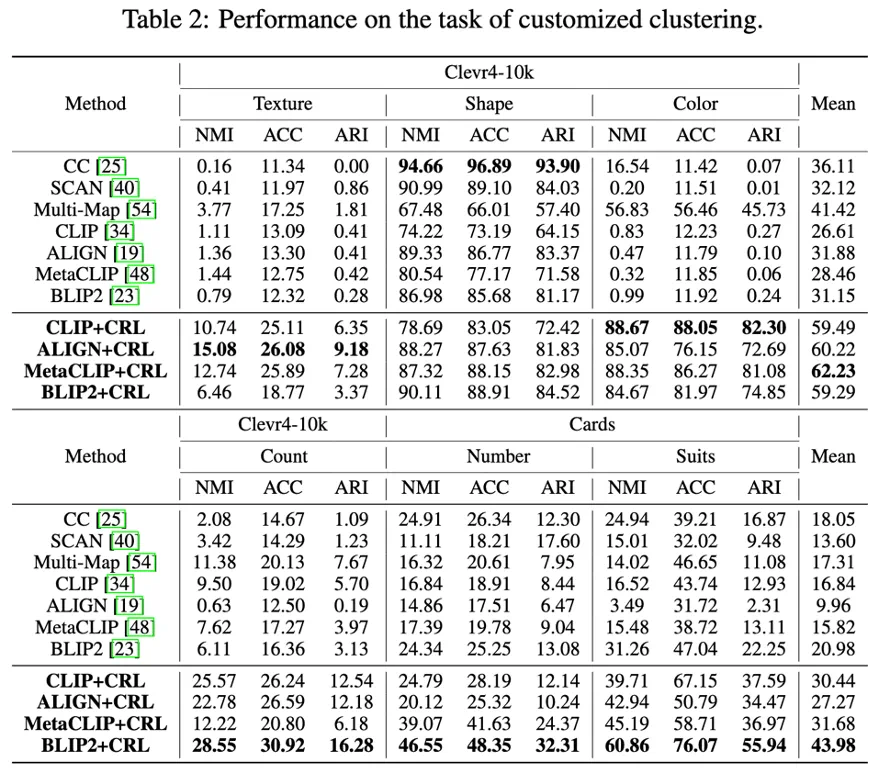
表 2:所提出的 CRL 在聚类任务上的性能。


图 4:相似度检索任务。上为 “Focus on an object”(Focus),下为 “Change an Object”(Change)。
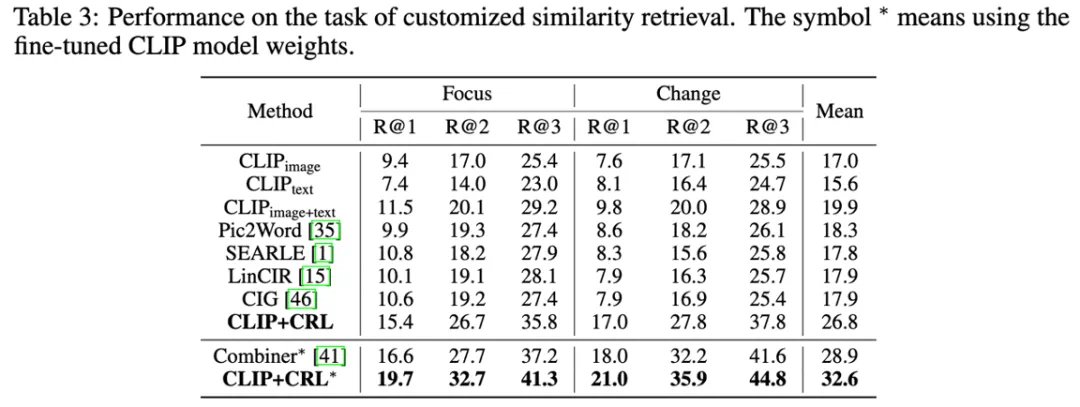
表 3:所提出的 CRL 在相似度检索任务上的性能。

图 5:服装检索任务。
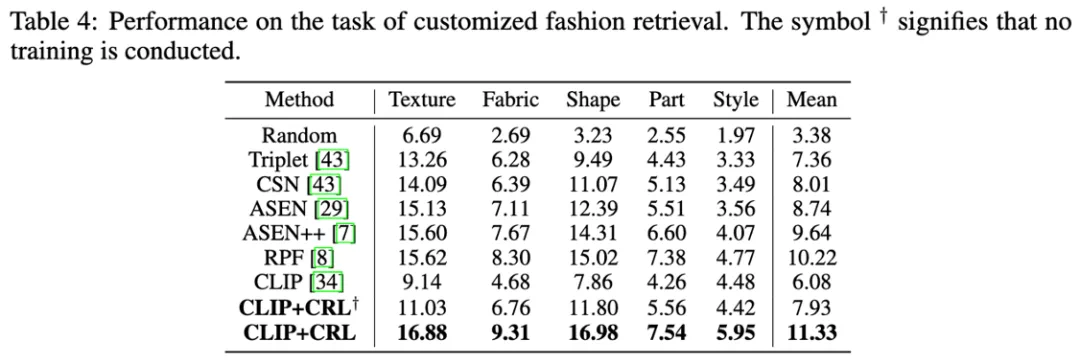
表 4:所提出的 CRL 在服装检索任务上的性能。
从上述结果中可以看出, CRL 可以作为一个即插即用的模块,与现有多模态方法相结合,在不同准则下,其得到的条件表征在下游任务中都取得了比原表征更加优异的表现,性能甚至超过了对应领域的专用方法。更多实验可参见论文。
总结
与传统的表征学习只得到单一的通用表征不同,本文提出了条件表征学习,通过获取指定准则下的文本基,并将图像表征投影到该文本基张成的空间中,即可得到该准则下表现力更强的条件表征,以更好地适应各种下游任务。


