AI 工程联盟 MLCommons 当地时间 1 月 30 日宣布 the Unsupervised People's Speech 数据集,这一数据集包含超过 100 万小时的音频内容,有望为 AI 在音频领域的下一步发展奠定基础。

Unsupervised People's Speech 数据集的资源来自 Archive.org,由 MLCommons 和 HuggingFace 联合创建,未进行数据推理和预处理。
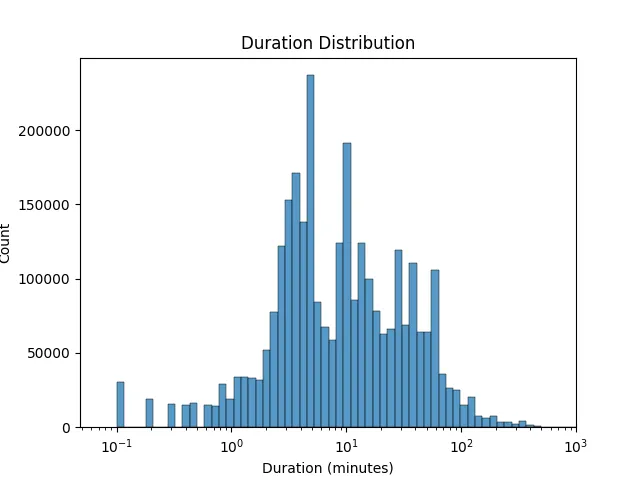
这一数据集整体规模超 48 TB。虽然 Unsupervised People's Speech 的内容以美式英语为主,但仍涵盖数十种语言;其中大多数音频的长度在 1 到 10 分钟之间,仅有 14 个超过了 100 小时。