在追求大模型“高智商”的同时,AI 的持续执行能力正成为衡量其进化水平的新维度。根据人工智能研究机构METR发布的最新基准测试,Anthropic 旗下的顶级模型Claude Opus4.5在处理超长时间任务方面展现出了统治级实力。
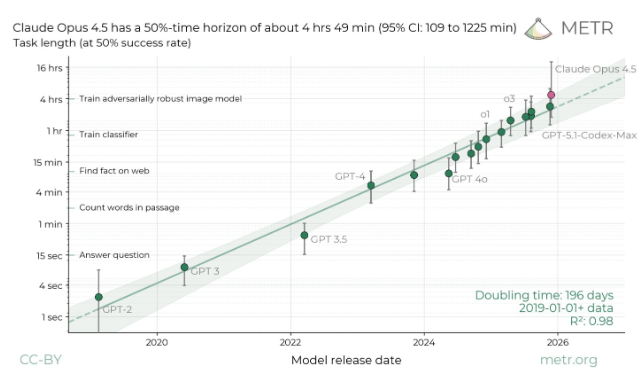
测试结果显示,Claude Opus4.5在维持50% 成功率的前提下,能够持续处理长达约 4小时49分钟 的复杂任务,这一表现刷新了行业历史记录。所谓的“时间分辨率”指标,揭示了模型在不同难度挑战下的耐力边界:在面对简单任务(80% 成功率)时,它仅需27分钟即可完成;而一旦进入高难度、高耗时的深水区,Opus4.5的优势便被无限放大。
AIbase 注意到,虽然测试数据中出现了模型理论上可连续工作超过20小时的数值,但METR坦言这可能受限于样本量较小而产生的误差。尽管如此,这一突破依然标志着 AI 正在从“短指令回复者”向“长程项目执行者”转型。
然而,也有专家对该测试的局限性提出了质疑。目前 METR 仅涵盖了14个样本,且有观点认为这种基准测试可能被模型针对性地“刷分”。但不可否认的是,Claude Opus4.5的出现,确实为需要高强度、长时程逻辑支撑的 AGI 任务提供了新的可能性。


