为什么大多数 Prompting 方法会失效
根据 Anthropic 的 Context Engineering 研究,在 2025 年,真正重要的不是“prompt engineering”,而是“context engineering”。问题不再是“如何打造完美的 prompt”,而是“哪种 context 组合能引发期望的行为”。
我会带你走一遍当前研究(Anthropic、OpenAI、Google、Wharton)对 AI agent prompting 的结论——以及如何在 n8n 工作流中具体落地。
你将学到:
- System Message vs User Prompt(以及为什么错误的分离会让 token 成本翻倍)
- 2025 年真正有效的五大核心技巧(有研究背书)
- 高级模式(Chain-of-Thought、RAG、Structured Outputs、Tool Use)
- 为什么应该与模型一起生成 prompt,而不是手工堆砌
- 模型相关注意事项(只讲实际相关的)
- 生产级模式(测试、错误处理、token 优化)
复制模板的陷阱
我经常见到:有人在 Reddit 上找到一个“完美”的 prompt 模板,复制到 AI Agent Node 里,然后期待它“魔法生效”。
剧透:不会。
复制模板失败的原因:
- Context mismatch:模板是为完全不同的用例、数据、工具写的
- Model differences:模板对 Claude 3 有效,而你用的是 GPT-4o-mini
- Over-complexity:模板有 500 行,因为作者想覆盖所有边界情况
- Under-specification:模板过于通用,对任何事都不够好
Anthropic 的 Prompt Engineering 指南强调“找到合适的高度”(right altitude)——对指导足够具体,但又为推理留有空间。模板对你的特定场景来说,几乎总是在错误的高度。
第二个问题:Prompt 过于复杂
“越多越好”的思路会带来巨大问题:
- Ignored instructions:当 context 超过 800+ 行,模型会开始忽略指令——Context Engineering 研究显示 LLM 有“有限注意力预算”
- Increased latency:更多 tokens = 更慢响应
- Higher costs:每个额外 token 都要花钱
- Maintenance nightmare:800 行 prompt 几乎无法调试或优化
解决方案:与模型一起生成 prompt
真正的游戏规则改变者是:让模型为你写 prompt。
不要花数小时打磨 prompt,而是给模型:
- 你的目标(agent 要做什么)
- 示例(输入/输出对)
- 约束(不该做什么)
模型会生成为你场景优化的 prompt。你测试、与模型迭代、再细化。
为什么有效:模型最了解自己的“偏好”。它知道哪种表述、结构、示例最有效。
稍后我会展示具体做法。
基础:n8n 中的 System Message 与 User Prompt
n8n 的 AI Agent prompting 中最基础也最常见的错误:混淆 System Message 和 User Prompt。
在 AI Agent Node 中,有两个不同的 prompt 区域:
System Message(Options → System Message):
- 定义 agent 的持久“DNA”
- 每次请求都会发送
- 几乎不变/不应该频繁更改
- 包含:role、tools、workflow、constraints
User Prompt(主输入):
- 只针对“本次请求”的具体任务
- 来自 Chat Trigger、Webhooks 或前置节点
- 每次请求都变化
- 只应包含本次的具体任务
 图片
图片
为什么重要:Token 经济学与 Prompt Caching
两者都会随每次 API 调用发送。但正确分离对成本和性能都至关重要:
错误做法(把一切都塞进 User Prompt):
复制若每天 1,000 次请求、每次 400 tokens: = 400,000 个冗余 tokens = 以 Claude Sonnet($3/M)计:$1.20/天 = 每月 $36 的纯冗余 context
正确做法:
System Message(只定义一次):
复制User Prompt 仅为:{{$json.message}}
= 每次 50 tokens 而非 400 = 节省:每天 350K tokens = 每月约 $31.50(以 Claude Sonnet 计)
Prompt Caching:为什么 System Message 应尽量保持静态
Anthropic 和 OpenAI 提供 Prompt Caching——System Message 会被缓存,不必每次都重新处理。可将延迟降低 50–80%,对已缓存的 tokens 成本最高可降至 10%。
但:一旦你更改 System Message,缓存就会失效。因此:
- 设计 System Message 为静态:基础角色、工具、工作流逻辑
- 用 User Prompt 承载可变信息:动态数据、具体任务
- 仅在出现重大变更时更新 System Message:新增工具、工作流逻辑改变
缓存影响示例:
无缓存: 请求 1:500 tokens 的 System Message = $0.0015 请求 2:500 tokens 的 System Message = $0.0015 请求 1000:500 tokens 的 System Message = $0.0015 总计:1,000 次请求 $1.50
有缓存(System Message 保持稳定): 请求 1:500 tokens 的 System Message = $0.0015(写入缓存) 请求 2:500 tokens 缓存命中 = $0.00015(便宜 90%) 请求 1000:500 tokens 缓存命中 = $0.00015 总计:~$0.15/1000 次请求 = 90% 节省
Dynamic System Messages:强大但要谨慎
你可以用 n8n Expressions 让 System Message 动态化——但要注意缓存:
复制适用场景:多租户系统——一个工作流,多个客户配置。
工作流:Webhook(Customer ID) → DB Lookup → AI Agent(动态 System Message) → Response
缓存权衡:动态 System Message 会破坏缓存——仅在必要时使用。
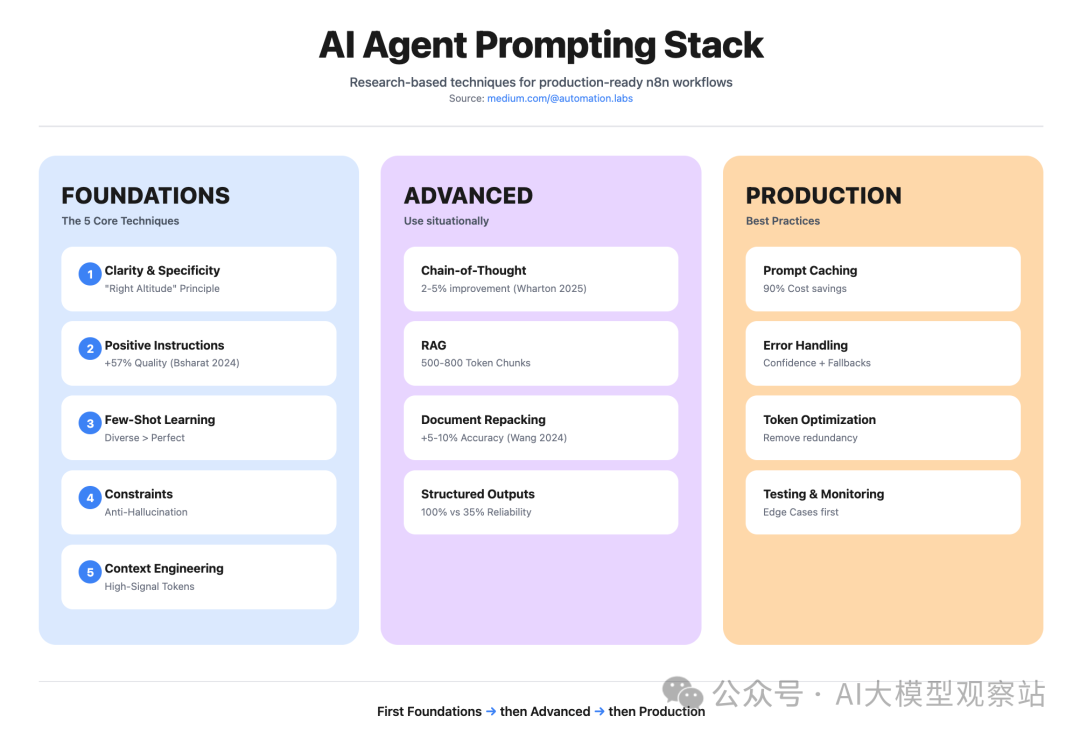
五大核心技巧:2024–2025 年研究给出的答案
来自 Anthropic、OpenAI、Google 在 2024–2025 的研究显示:有一些对所有模型都有效的基本技巧。以下五条最重要:
 图片
图片
技巧 1:清晰与具体(“Altitude” 原则)
Anthropic 的 Prompt Engineering 指南称之为“找到合适的高度”(right altitude)——既足够具体以提供指导,又为推理保留灵活性。
“同事测试”:如果一个聪明的同事看不懂这条指令,AI 也不会懂。
反例:
复制“intelligently” 是什么?有哪些类别?输出格式是怎样?
正例:
复制为何有效:
- 消除歧义(明确只有四类)
- 提供决策标准(非主观)
- 明确输出格式(无需猜测)
- 可度量(有 confidence 分数)
技巧 2:正向指令(质量提升 57%)
Bsharat 等(2024)研究显示,正向指令明显优于负向指令。将“不要做 X”改为“请做 Y”,平均带来 57% 的质量提升。
负向指令为何失效:
- 模型先要理解你“不想要”的
- 再推断你“想要”的
- 这个两步推理经常失败
负向反例:
复制正向改写:
复制实际影响:
在生产环境的邮件分类 agent 中,负向指令(“不要误判紧急请求”)造成 31% 的漏判。正向改写(“凡含时间限制的请求一律标记为 urgent”)将漏判降至 8%。
技巧 3:Few-Shot Learning(示范胜于告知)
Few-shot 示例非常有效——但大多数人用错了。
研究共识:
- 大多数任务 2–5 个示例最优(更多帮助不大)
- 示例要“多样化”(avoid 相似堆砌)
- 应包含 edge cases
- Label bias 重要:Zhao 等(2021)显示示例顺序会影响结果
糟糕的 few-shot(过于相似):
复制全是同一种问题。模型学不到边界处理。
良好的 few-shot(多样且含 edge cases):
复制复制复制复制为何有效:
- 覆盖不同场景(标准、紧急、混合、不清楚)
- 示范如何处理边界(低置信度 → 追问澄清)
- 展示一致的输出格式
- 让模型学习决策模式,而非仅做类别匹配
技巧 4:Constraints & Grounding(对抗幻觉)
AI agents 的大问题之一:hallucination(幻觉)。找不到答案时它们会编造。
解决方案:显式约束,将 agent “落地”。
糟糕做法(无约束):
复制后果:找不到信息时 agent 会胡编。
良好做法(显式约束):
复制为何有效:
- 清晰边界(ONLY 文档中的信息)
- 明确兜底行为(不确定时怎么做)
- 升级标准(何时转人类)
- 不留“自由发挥”的空间
生产影响:
在每月处理 2000+ 询问的客服 agent 中,加入约束将幻觉率从 23% 降至 3%。升级的人工工单质量显著提升,因为工单会包含具体的文档缺口信息。
技巧 5:Context Engineering(最小高信号 token 集)
Anthropic 的研究很明确:不是“更多 context”,而是“正确的 context”。
原则:Smallest High-Signal Token Set
- 你的 context 中每一个 token 都应提供价值
- 冗余信息会稀释关键信号
- 更多 context ≠ 更好表现(往往适得其反)
糟糕的 context(冗长、重复):
复制350 个 token 的空话,几乎没有可执行指导。
良好的 context(密度高、具体):
复制110 个 token,信号密度很高。每行都有可执行信息。
Token 审计:
对 prompt 中每个句子问一句:“删掉它,agent 会变差吗?”如果不会,就删。
高级模式:何时用(何时别用)
核心技巧适用于所有场景。下面这些高级模式非常强,但要“对症下药”。
模式 1:Chain-of-Thought(CoT)——用于复杂多步推理
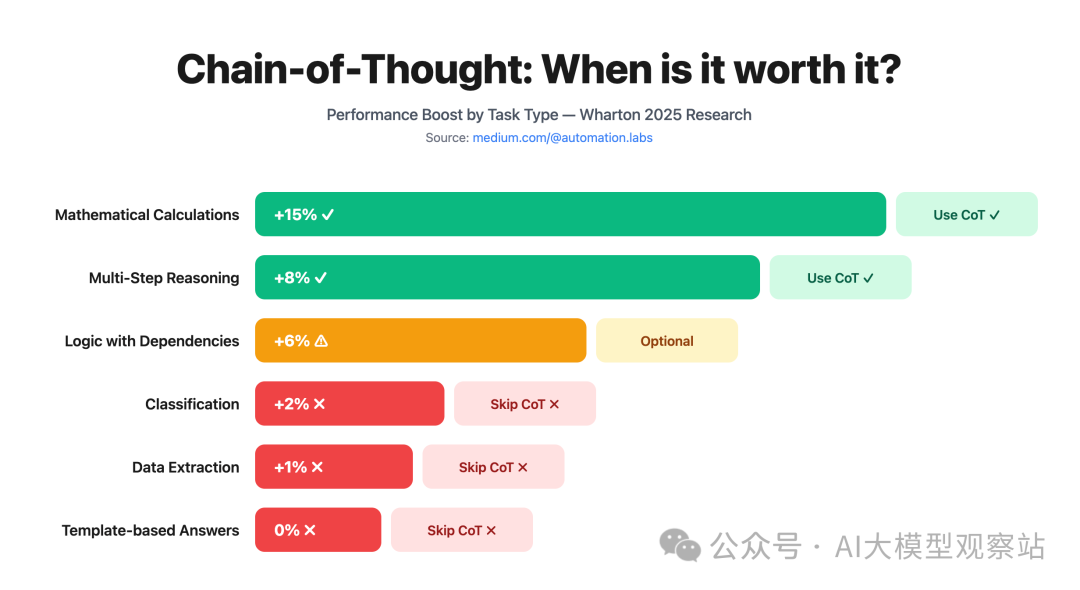
沃顿商学院 2025 年 6 月的研究给出了迄今最全面的分析:CoT 对复杂推理有帮助,但对简单任务效果参差。
何时使用 CoT:
- 需要多步逻辑推理
- 数学计算
- 有依赖关系的复杂决策树
- 中间步骤重要的任务
不该用 CoT 的场景:
- 简单分类(增加负担无益)
- 模式匹配型任务
- 对速度极其敏感(CoT 会增加延迟)
 图片
图片
在 n8n 中的实现:
复制性能影响:
- 准确度提升:复杂推理任务提升 2–5%
- 延迟增加:20–40%(模型输出更多 tokens)
- 成本增加:与输出 token 增长成正比
结论:只有当准确度提升能抵消成本和延迟的权衡时,才使用 CoT。
模式 2:RAG(Retrieval-Augmented Generation)——用于外部知识
当你的 agent 需要:
- 动态/频繁更新的内容(产品目录、文档)
- 体量巨大、放不进 context 的知识库
- 客户特定数据(订单记录、账户详情)
- 训练语料之外的专有信息
RAG 就是必需的。
n8n 中的 RAG 基本流程:
复制关键 RAG 要点(基于 kapa.ai 的分析):
- Chunk size:每块 500–800 tokens(大多任务的最佳区间)
- Overlap:块间重叠 50–100 tokens(避免边界信息丢失)
- Number of chunks:返回 3–5 个最相关块
- Reranking:向量召回后做语义重排以提升相关性
- Metadata:包含来源、时间戳、置信度
RAG Prompt 示例:
复制模式 3:Document Repacking——顺序比你想的更重要
Wang 等(2024)研究发现:context 的“顺序”影响显著。
发现要点:
- Primacy bias:模型更注意开头的信息
- Recency bias:也更注意结尾的信息
- Middle neglect:中间的信息更容易被忽略
- 性能影响:通过最优排序可提升 5–10% 准确度
最优排序策略:
- 最相关/最重要的信息放最前
- 次要的支持信息放中间
- 约束与提醒放最后(利用近因效应)
示例(RAG context):
复制模式 4:Structured Outputs——为数据抽取提供 100% 可靠性
OpenAI 的 Structured Outputs(GPT-4o)及其他模型的类似能力,解决了一个大问题:获得一致、可解析的输出。
传统 prompting 的问题:
复制模型可能会输出:
- 合法 JSON
- 带多余字段的 JSON
- 缺字段的 JSON
- 格式错误的 JSON
- 先文字解释再给 JSON
你得为这些情况全部做兜底。
Structured Outputs 的方案:
定义 JSON schema,配合 Structured Output Parser 节点拦截异常即可。
示例 schema:
复制好处:
- 不再有解析错误
- 保证 schema 合规
- 下游处理更简单
- Enum 约束(只允许有效值)
何时使用:
- 非结构化文本的数据抽取
- 固定类别的分类
- 需要特定格式的 API 集成
- 任何对输出格式一致性要求高的任务
元技能:与模型一起生成 prompt
我构建 AI agents 的方式就此改变:别再手写 prompt,让模型来生成。
流程:
- 定义需求(agent 要做什么)
- 提供示例(能代表期望行为的输入/输出对)
- 指定约束(绝不该做什么)
- 让模型生成“优化后的”prompt
- 测试并迭代(基于实际表现微调)
Meta-prompt 示例:
复制模型会生成一个:
- 结构与措辞最优
- 融合有效技巧
- 在具体与灵活间取得平衡
- 针对你用例的 prompt
为何有效:
- 模型了解自己的“偏好”
- 它会采用最优结构和表述
- 你能省下大量试错时间
模型相关注意事项:哪些真的重要
大多数“模型特定技巧”并不靠谱。但有些差异确实重要:
Claude(Anthropic):
- 优势:复杂推理、长 context(200K tokens)
- 劣势:有时过度谨慎,会拒绝无害请求
- 最佳实践:明确写清 constraints,再让其自由推理
- Prompt caching:对 >1024 tokens 的 System Messages 启用
GPT-4o(OpenAI):
- 优势:Structured Outputs(100% schema 合规)、速度快
- 劣势:context 较短(128K),较少“深思熟虑”
- 最佳实践:数据抽取使用 Structured Outputs,配合精确指令
- Prompt caching:对 System Messages 自动启用
GPT-4o-mini:
- 优势:便宜($0.15/M vs $3/M),适合简单任务
- 劣势:复杂指令鲁棒性较弱
- 最佳实践:使用具体、结构化的 prompts,配 few-shot 示例
Gemini(Google):
- 优势:多模态(图像、视频)、超长 context(2M tokens)
- 劣势:tool-use 支持较弱,有时不稳定
- 最佳实践:用于多模态场景,避免复杂工具编排
选型经验法则:
- 复杂推理 + 长文档 → Claude Sonnet
- 数据抽取 + Structured Outputs → GPT-4o
- 简单分类 + 预算敏感 → GPT-4o-mini
- 多模态(图/视频)→ Gemini
生产级模式:测试、错误处理、优化
好 prompt 远远不够——你需要生产级工作流。
- 测试策略
用真实的 edge cases 测,别只测“快乐路径”:
复制- 错误处理
AI agents 可能失败——要有兜底:
复制带 confidence 的 System Message 约定:
复制- Token 优化
高并发下,每个 token 都很宝贵:
- 移除冗余:例如 “Please”、“Thanks”、“I think”
- 合理缩写:“Maximum”→“Max”,“Information”→“Info”
- 使用符号:“→” 代替 “then”,“✓” 代替 “correct”
- 用 JSON 替代散文:结构化数据优于长句
- 监控与日志
跟踪关键指标:
- Latency:agent 响应耗时
- Token usage:每次请求的输入 + 输出 tokens
- Error rate:失败频率
- Confidence distribution:置信度分布
在 n8n 中:用 Webhook → Google Sheets 进行轻量记录:
复制上线检查清单
上线前:
Prompt 质量:
- System Message 与 User Prompt 是否正确分离?
- System Message 是否稳定以利用 prompt caching?
- 是否使用正向指令(而非“避免 X”)?
- 是否有含 edge cases 的 few-shot 示例?
- 约束是否清晰?
- 输出格式是否明确?
测试:
- 是否用 10+ 个真实测试用例?
- 边界情况(短输入、错别字、混合意图)是否覆盖?
- 错误处理是否有效?
- 不确定时是否有 fallback 策略?
性能:
- Token 是否优化(无冗余)?
- 是否启用 prompt caching?
- 延迟是否可接受(< 3s)?
- 单次请求成本是否核算?
监控:
- 是否记录 token 使用?
- 是否实现错误跟踪?
- 是否启用置信度评分?
- 是否有关键指标仪表板?
迭代:
- 是否有 A/B 测试策略来改进 prompt?
- 是否建立基于真实用户数据的反馈回路?
- 是否规划定期复盘?
总结:2025 年真正有效的是什么
五大通用核心技巧:
- Clarity & Specificity:合适的“高度”——具体且保留推理空间
- Positive Instructions:质量提升 57%(Bsharat 等,2024)
- Few-Shot Learning:多样示例 + 边界情况
- Constraints & Grounding:以清晰边界对抗幻觉
- Context Engineering:最小高信号 token 集
情境性高级模式:
- Chain-of-Thought:仅用于复杂多步推理(提升 2–5%)
- RAG:应对外部/更新知识(chunk 500–800 tokens)
- Document Repacking:通过排序提升 5–10% 准确度
- Structured Outputs:数据抽取 100% 可靠(GPT-4o)
元结论:
- 复制模板会失败——与模型一起生成 prompts
- 保持 System Message 稳定以发挥 prompt caching(可省 90% 成本)
- Token 经济学比“完美措辞”更重要
- 用 edge cases 做测试比“再加几个 few-shot”更关键
 图片
图片
你的下一步:挑一个现有的 n8n AI Agent 工作流,套用以上五大核心技巧。对比前后 token 使用。通常你会看到成本大幅下降,同时输出质量不降反升。
这就是“勉强可用”的 prompting 与“可规模化、可上生产”的 prompting 的区别。


