2025 年,我们可能会看到第一批 AI Agent 加入劳动力大军,并对公司的生产力产生实质性的影响。
——OpenAI CEO Sam Altman
2025 年,每个公司都将拥有 AI 软件工程师 Agent,它们会编写大量代码。
——Meta CEO Mark Zuckerberg
未来,每家公司的 IT 部门都将成为 AI Agent 的 HR 部门。
—— 英伟达 CEO 黄仁勋
2025 新年伊始,在很多趋势都还不明朗的情况下,几位 AI 业界的重要人物几乎在同一时间做出了类似的判断 ——2025 年将是 AI Agent 之年。
没想到,MiniMax 很快就有了动作:开源了最新的基础语言模型 MiniMax-Text-01 和视觉多模态模型 MiniMax-VL-01。

新模型的最大亮点是,在业内首次大规模实现了新的线性注意力机制,这使得输入的上下文窗口大大变长:一次可处理 400 万 token,是其他模型的 20-32 倍。
他们相信,这些模型能够给接下来一年潜在 Agent 相关应用的爆发做出贡献。
为什么这项工作对于 Agent 如此重要?
随着 Agent 进入应用场景,无论是单个 Agent 工作时产生的记忆,还是多个 Agent 协作所产生的 context,都会对模型的长上下文窗口提出更多需求。

- 开源地址:https://github.com/MiniMax-AI
- Hugging Face:https://huggingface.co/MiniMaxAI
- 技术报告:https://filecdn.minimax.chat/_Arxiv_MiniMax_01_Report.pdf
- 网页端:https://www.hailuo.ai
- API:https://www.minimaxi.com/platform
一系列创新造就比肩顶尖模型的开源模型
MiniMax-Text-01 究竟是如何炼成的?事实上,他们为此进行了一系列创新。从新型线性注意力到改进版混合专家架构,再到并行策略和通信技术的优化,MiniMax 解决了大模型在面对超长上下文时的多项效果与效率痛点。
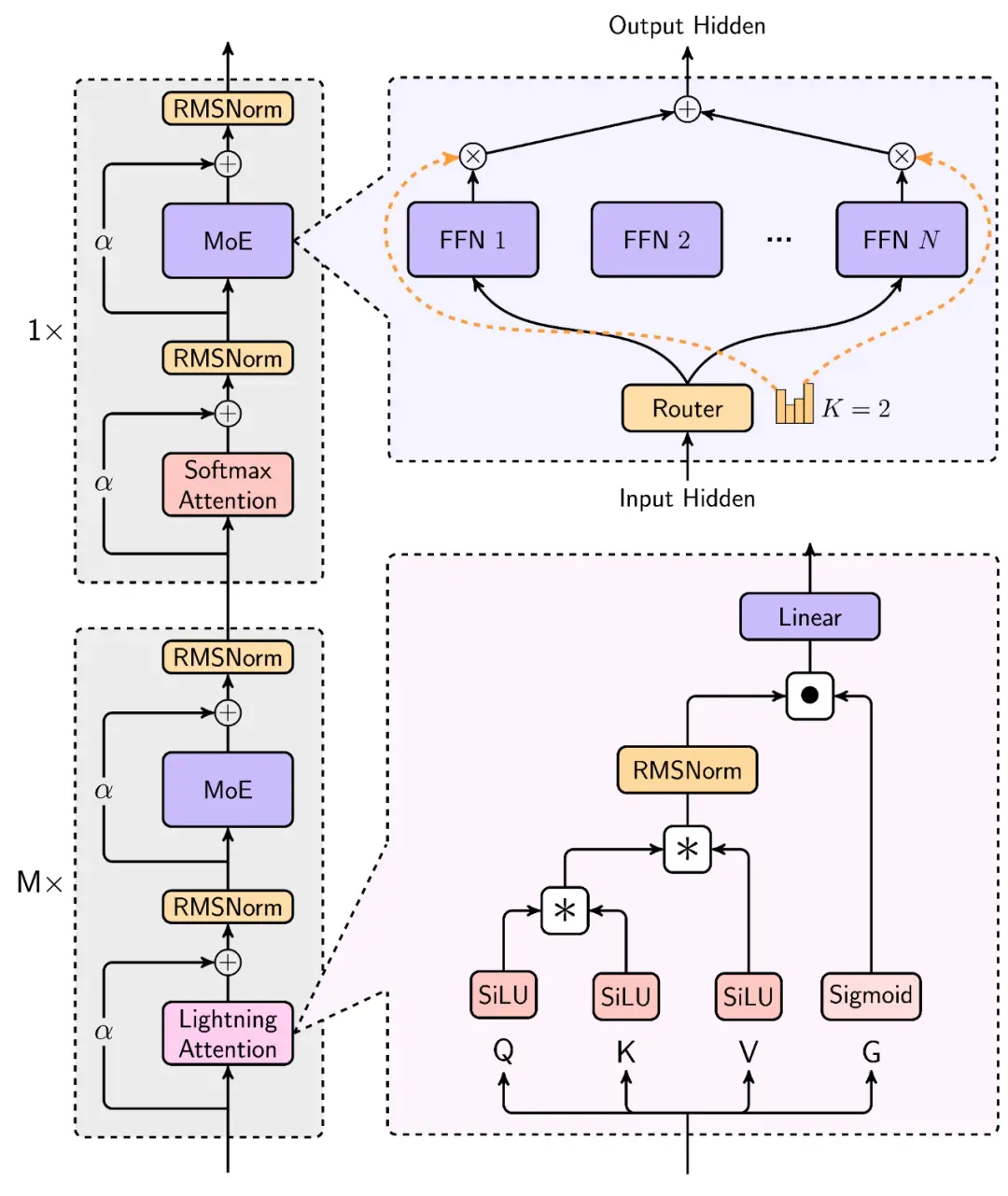
MiniMax-Text-01 的架构
1. Lightning Attention
目前领先的 LLM 大都基于 Transformer,而 Transformer 核心的自注意力机制是其计算成本的重要来源。为了优化,研究社区可以说是绞尽脑汁,提出了稀疏注意力、低秩分解和线性注意力等许多技术。MiniMax 的 Lightning Attention 便是一种线性注意力。
通过使用线性注意力,原生 Transformer 的计算复杂度可从二次复杂度大幅下降到线性复杂度,如下图所示。
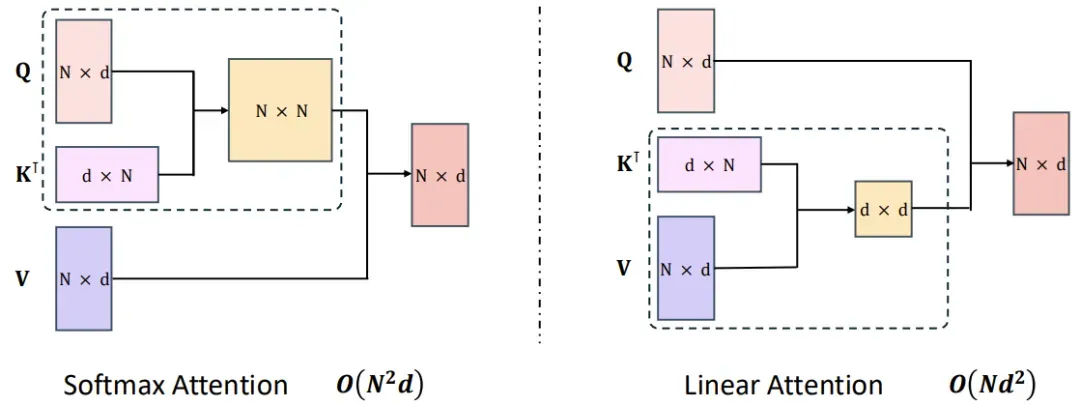
MiniMax 的相关技术报告中写道,这主要是得益于一种右边积核技巧(right product kernel trick)。以 2022 年论文《The Devil in Linear Transformer》中的 TransNormer 为例,下图左侧的 NormAttention 机制可转换成使用「右侧矩阵乘法」的线性变体。

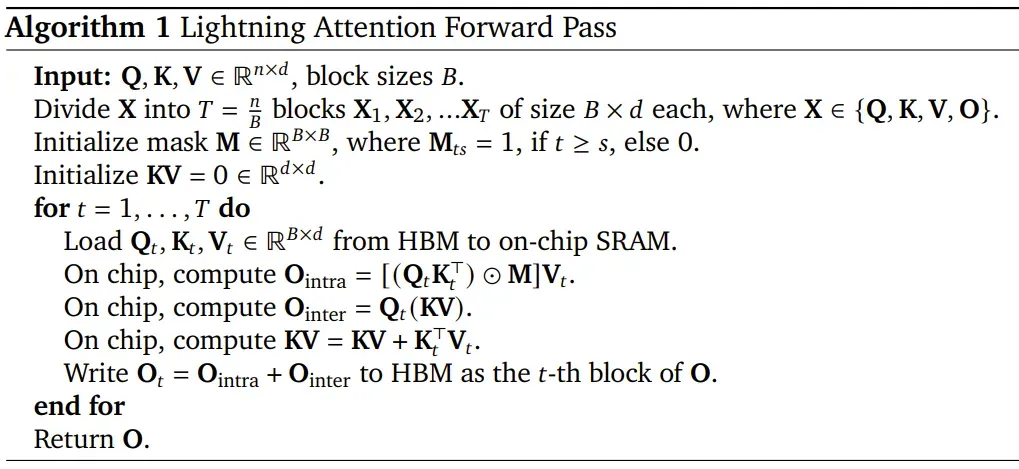
而 Lightning Attention 便是基于 TransNormer 实现的一个 I/O 感知型优化版本。
以下是 Lightning Attention 前向通过的算法描述。
基于 Lightning Attention,MiniMax 还提出了一种 Hybrid-lightning,即每隔 8 层将 Lightning Attention 替换成 softmax 注意力,从而既解决了 softmax 注意力的效率问题,也提升了 Lightning Attention 的 scaling 能力。
效果如何?下表给出了根据层数 l、模型维度 d、批量大小 b 和序列长度 n 计算注意力架构参数量与 FLOPs 的公式。

可以明显看出,模型规模越大,Lightning Attention 与 Hybrid-lightning 相对于 softmax 注意力的优势就越明显。
2. 混合专家(MoE)
MoE 相对于密集模型的效率优势已经得到了大量研究证明。MiniMax 团队同样也进行了一番比较实验。他们比较了一个 7B 参数的密集模型以及 2B 激活参数和 20B 总参数的 MoE 模型。结果如下图所示。
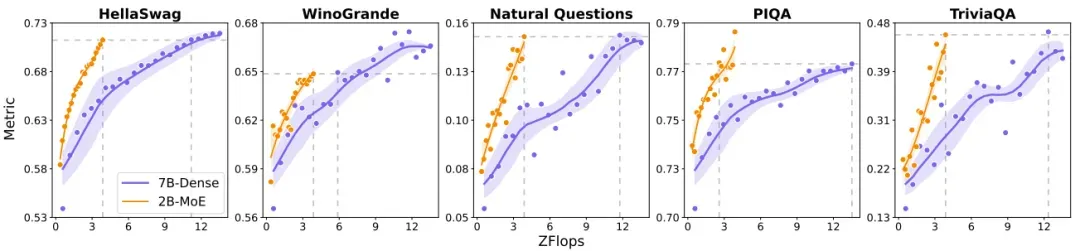
可以看到,在多种基准上,当计算负载一样时,MoE 模型的表现要大幅优于密集模型。
MiniMax 还引入了一个新的 allgather 通信步骤,可解决扩大 MoE 模型的规模时可能会遇到路由崩溃(routing collapse)问题。
3. 计算优化
与许多大模型训练项目一样,MiniMax 先通过小规模实验上述技术改进的有效性以及 Scaling Law,然后再开始着手大规模训练。MiniMax 为此采用了 1500 到 2500 台 H800 GPU—— 并且在训练过程中,具体使用 GPU 数量会动态变化。而大规模训练都有自己的特有挑战,MiniMax 开发了一系列针对性的优化技术。
首先,对于 MoE 架构,最主要的优化目标是降低其通信负载。尤其是对于采用 all-to-all(a2a)通信的 MoE 模型。MiniMax 的解决方案是一种基于 token 分组的重叠方案。
其次,对于长上下文训练,一大主要挑战是难以将真实的训练样本标准化到统一长度。传统的方式是进行填充,但这种方法非常浪费计算。MiniMax 的解决思路是进行数据格式化,其中不同样本会沿序列的维度首尾相连。他们将这种技术命名为 data-packing。这种格式可尽可能地降低计算过程中的计算浪费。
最后,为了将 Lightning Attention 投入实践,MiniMax 采用了四项优化策略:分批核融合、分离式的预填充与解码执行、多级填充、跨步分批矩阵乘法扩展。
MiniMax-Text-01上下文巨长,能力也够强
基于以上一系列创新,MiniMax 最终得到了一个拥有 32 个专家共 4560 亿参数的 LLM,每个 token 都会激活其中 459 亿个参数。MiniMax 将其命名为 MiniMax-Text-01。在执行推理时,它的上下文长度最高可达 400 万 token,并且其表现出了非常卓越的长上下文能力。
1. MiniMax-Text-01 基准成绩优秀
在常见的学术测试集上,MiniMax-Text-01 基本上能媲美甚至超越 GPT-4o、Claude 3.5 Sonnet 等闭源模型以及 Qwen2.5、DeepSeek v3、Llama 3.1 等 SOTA 开源模型。下面直接上成绩。
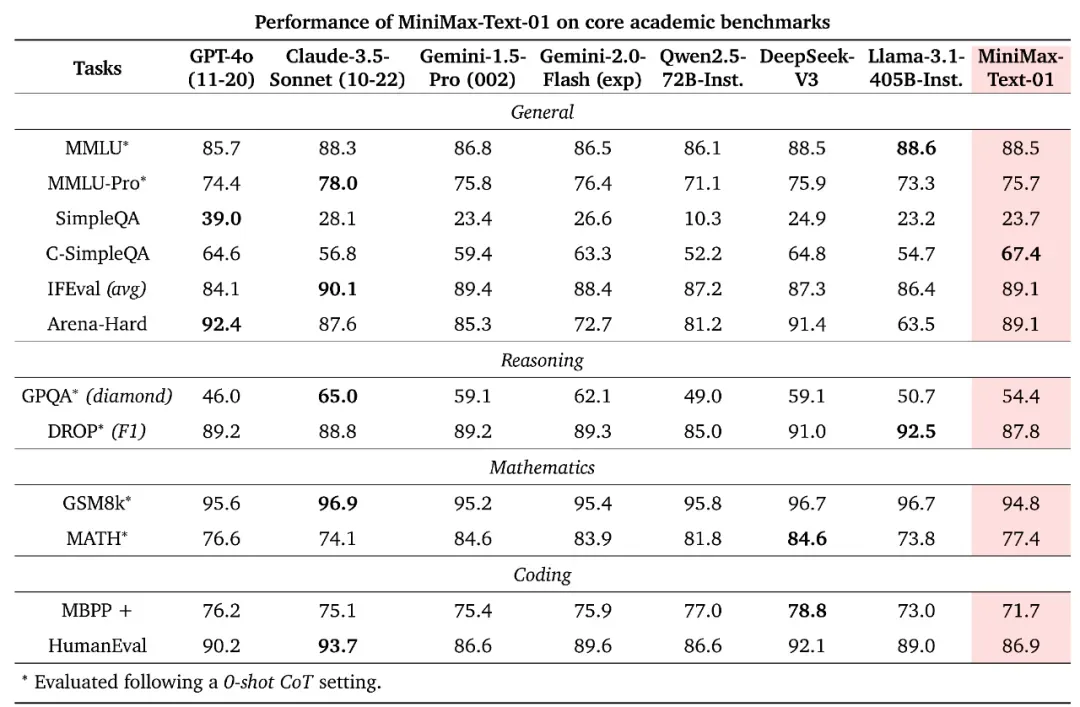
可以看到,在 HumanEval 上,MiniMax-Text-01 与 Instruct Qwen2.5-72B 相比表现出色。此外,MiniMax-Text-01 在 GPQA Diamond 这样具有挑战性问答的数据集上取得了 54.4 的成绩,超过了大多数开源指令微调的 LLM 以及最新版本的 GPT-4o。
MiniMax-Text-01 在 MMLU、IFEval 和 Arena-Hard 等测试中也取得了前三名的成绩,展示了其在给定限制条件下,应用全面知识来充分满足用户查询、与人类偏好保持一致的卓越能力。可以想象,基于最新的模型能力,也给开发者开发 Agent 应用提供了更好的基础。
2. 领先的上下文能力
那 MiniMax-Text-01 引以为傲的长上下文能力呢?其优势就更为明显了。
在长上下文理解任务上,MiniMax 测试了 Ruler 和 LongBench v2 这两个常见基准。首先在 Ruler 上,可以看到,当上下文长度在 64k 或更短时,MiniMax-Text-01 与其它 SOTA 模型不相上下,而当上下文长度超过 128k 时,MiniMax-Text-01 的优势就明显显现出来了。
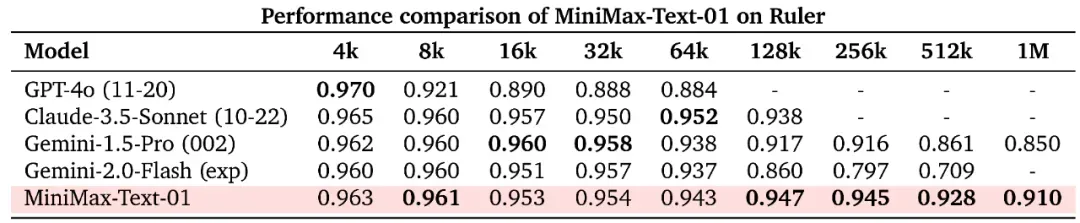
在 Ruler 上,MiniMax-Text-01 与其它模型的性能比较
同样,MiniMax-Text-01 在 LongBench v2 的长上下文推理任务上的表现也非常突出。
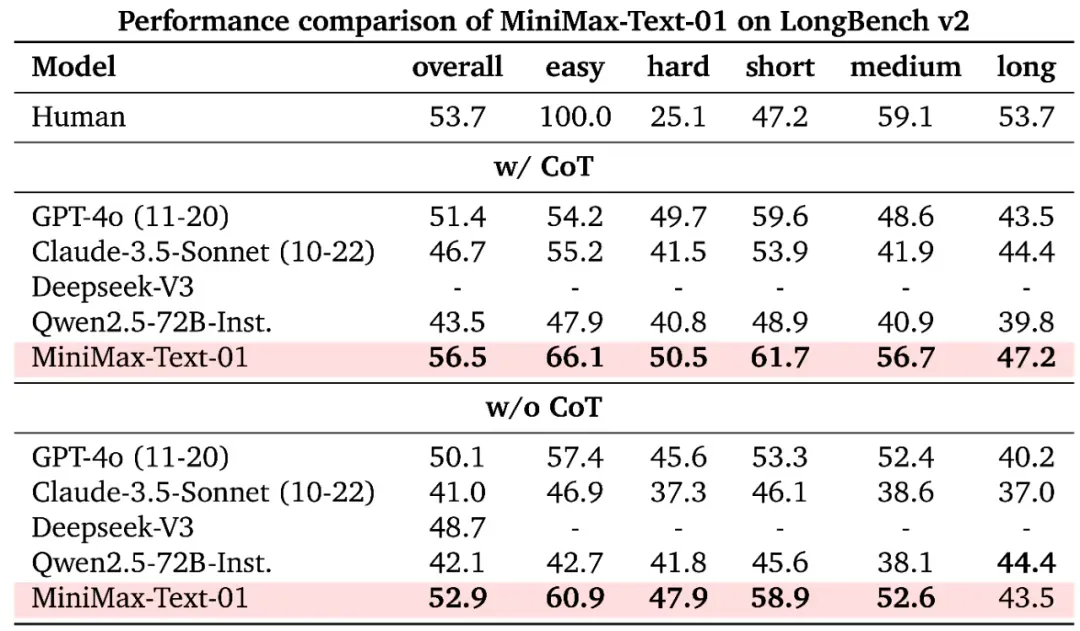
在 LongBench v2 上,MiniMax-Text-01 与其它模型的性能比较
另外,MiniMax-Text-01 的长上下文学习能力(终身学习的一个核心研究领域)也是 SOTA 水平。MiniMax 在 MTOB 基准上验证了这一点。
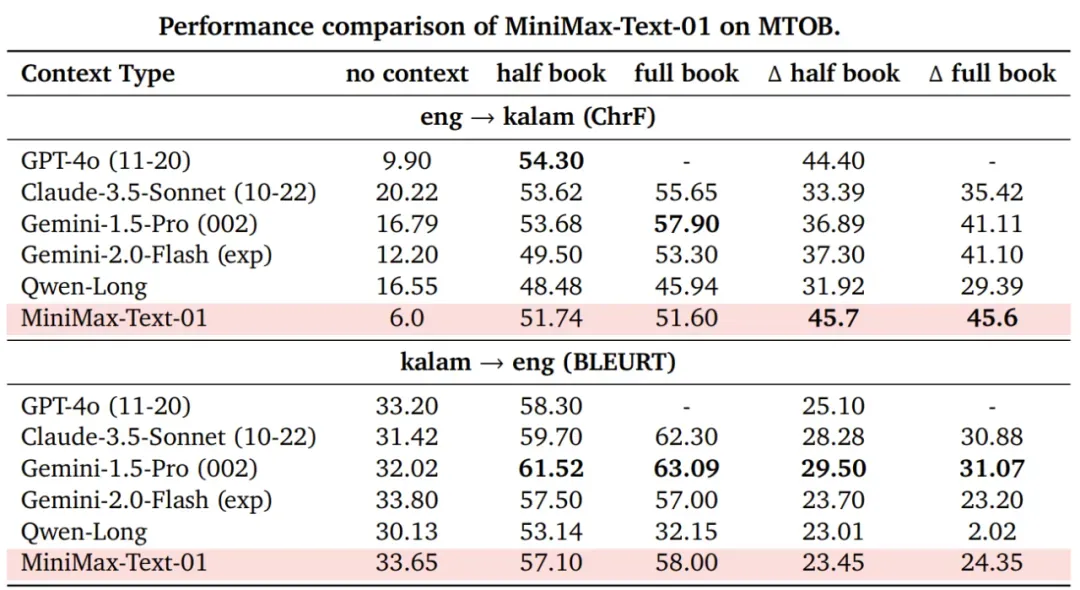
在 MTOB 上,MiniMax-Text-01 与其它模型的性能比较
3. 长文本能力Showcase
MiniMax-Text-01 得到了很不错的基准分数,但实际表现如何呢?下面展示了一些示例。
首先,来写首歌吧!
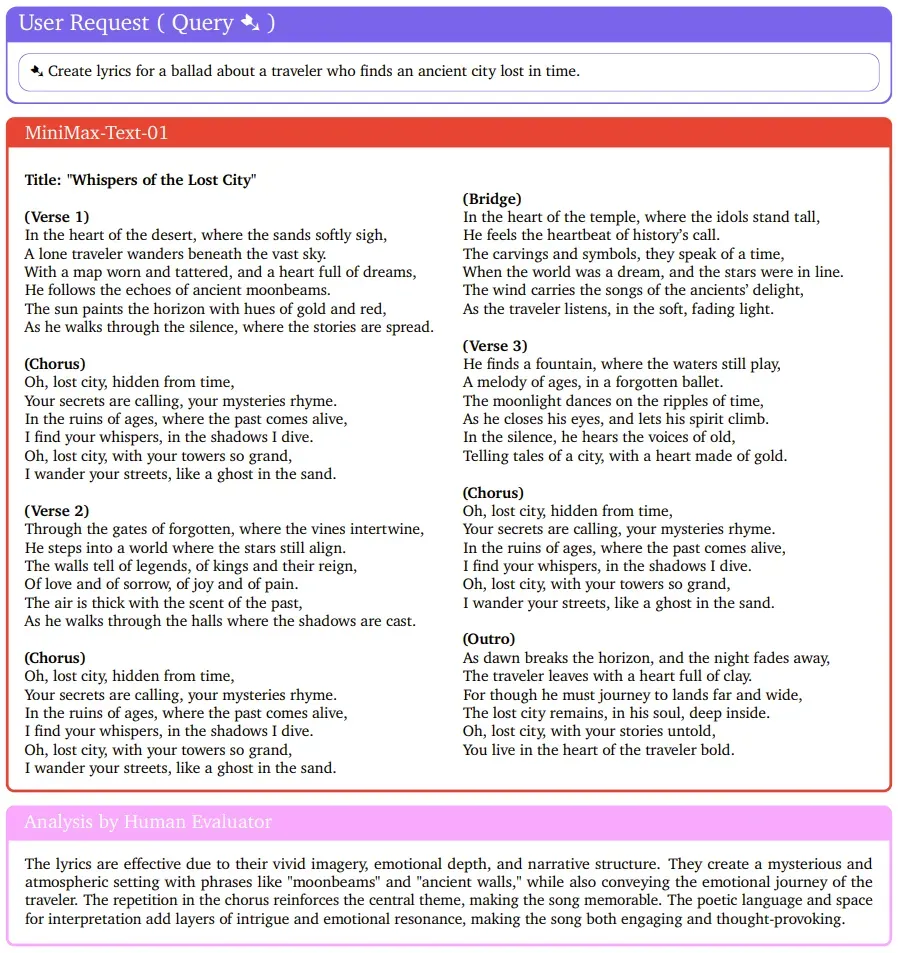
人类评估者也给出了非常正面的评价:诗意的语言和演绎空间为歌曲增添了层层的趣味和情感共鸣,使歌曲既引人入胜又发人深省。
下面重点来看看 MiniMax-Text-01 的长上下文能力。对于新几内亚的一门小众语言 Kalamang,先将指令、语法书、单词表、与英语的对照例句放入 MiniMax-Text-01 的上下文,然后让其执行翻译。可以看到,MiniMax-Text-01 给出的答案基本与标准答案一致。

至于长对话记忆任务,MiniMax-Text-01 可说是表现完美。

4. 视觉-语言模型
基于 MiniMax-Text-01,MiniMax 还开发了一个多模态版本:MiniMax-VL-01。思路很简单,就是在文本模型的基础上整合一个图像编码器和一个图像适配器。简而言之,就是要将图像变成 LLM 能够理解的 token 形式。
因此,其整体架构符合比较常见的 ViT-MLP-LLM 范式:MiniMax-VL-01 作为基础模型,再使用一个 303M 参数的 ViT 作为视觉编码器,并使用了一个随机初始化的两层式 MLP projector 来执行图像适应。
当然,为了确保 MiniMax-VL-01 的视觉理解能力足够好,还需要在文本模型的基础上使用图像-语言数据进行持续训练。为此,MiniMax 设计了一个专有数据集,并实现了一个多阶段训练策略。
最终,得到的 MiniMax-VL-01 模型在各个基准上取得了如下表现。
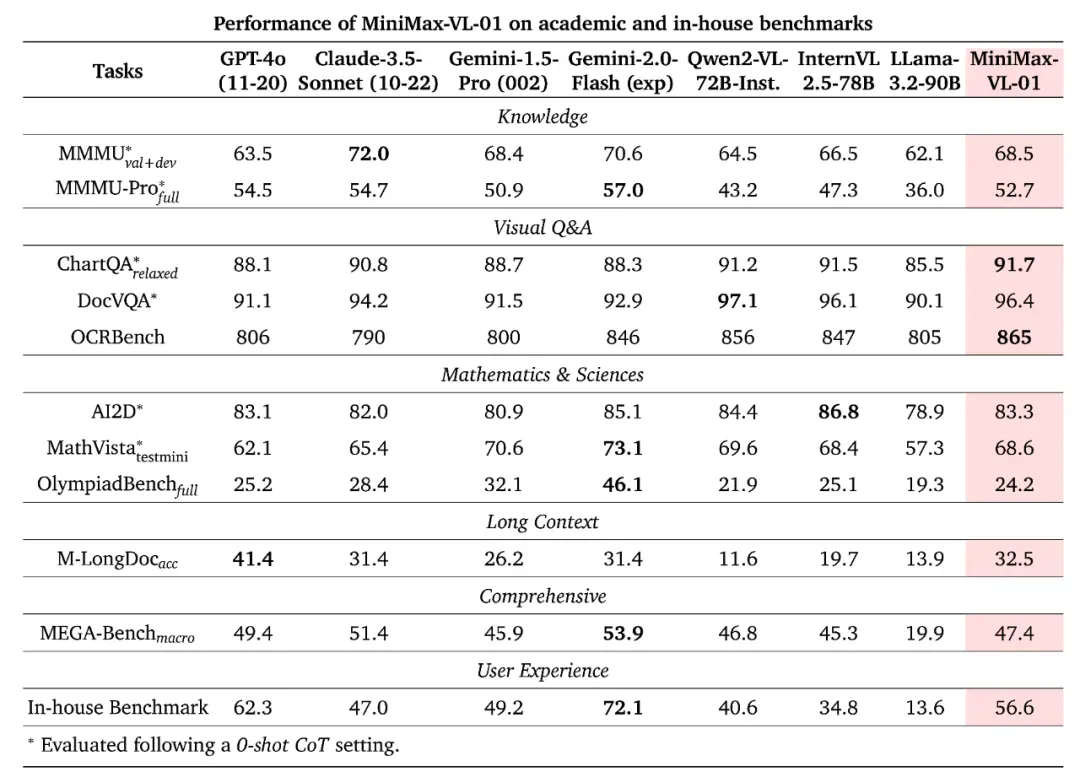
可以看到,MiniMax-VL-01 整体表现强劲,整体能与其它 SOTA 模型媲美,并可在某些指标上达到最佳。
下面展示了一个分析导航地图的示例,MiniMax-VL-01 的表现可得一个赞。
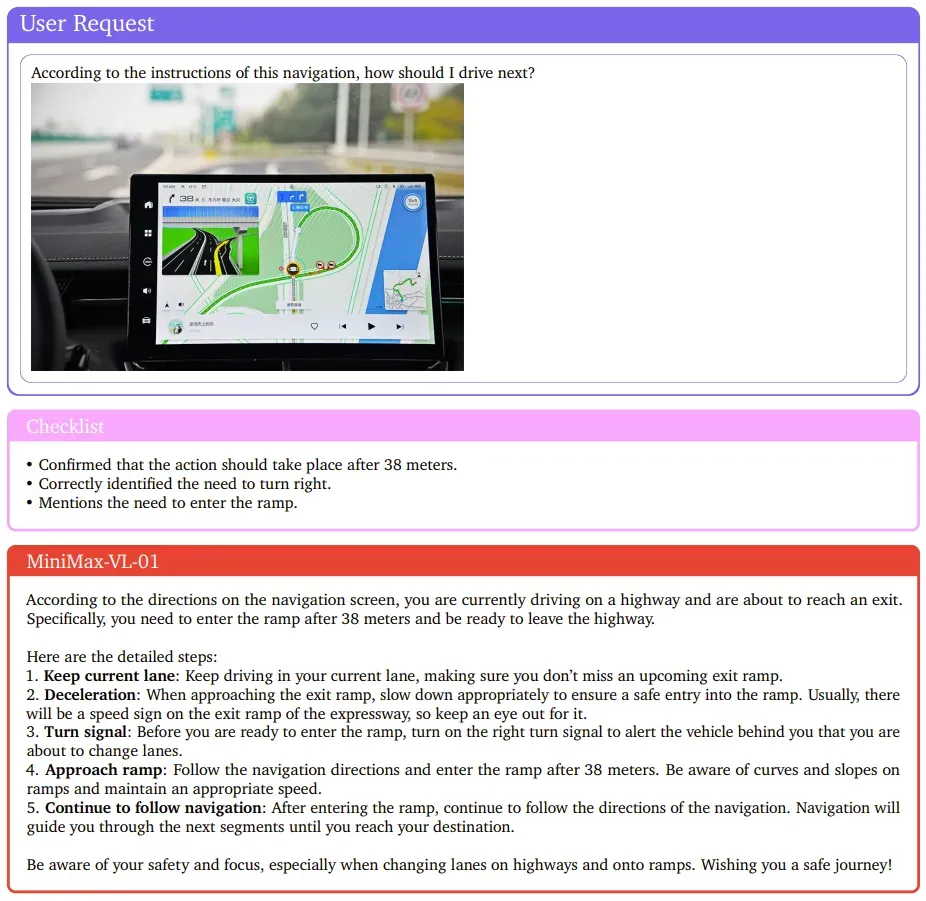
探索无限的上下文窗口让 Agent 走进物理世界
有人认为 [1],context 会是贯穿 AI 产品发展的一条暗线,context 是否充分同步会直接影响智能应用的用户体验,这包括用户的个性化信息、环境变化信息等各种背景上下文信息。
而为了保证 context 充分同步,足够大的上下文窗口就成了大模型必须克服的技术难题。目前,MiniMax 已经在这条路上迈出了重要的一步。
不过,400 万 token 的上下文窗口明显不是终点。他们在技术报告中写道:「我们正在研究更高效的架构,以完全消除 softmax 注意力,这可能使模型能够支持无限的上下文窗口,而不会带来计算开销。」
除此之外,MiniMax 还在 LLM 的基础上训练的视觉语言模型,同样拥有超长的上下文窗口,这也是由 Agent 所面临的任务所决定的。毕竟,在现实生活中,多模态任务远比纯文本任务更常见。
「我们认为下一代人工智能是无限接近通过图灵测试的智能体,交互自然,触手可及,无处不在。」MiniMax 创始人在去年的一次活动中提到。
或许,「无处不在」也意味着,随着多模态 token 的加入,Agent 也将逐步进入物理世界。为此,AI 社区需要更多的技术储备。


