MiniMax Audio推出的Speech-02系列语音模型席卷全球,强势登顶Artificial Analysis Speech Arena和Hugging Face TTS Arena两大权威榜单,力压ElevenLabs、OpenAI等国际顶尖竞争对手。这款模型以超高语音逼真度和多语言支持惊艳业界,成为AI语音技术的全新标杆。AIbase综合最新动态,深入解析Speech-02的技术亮点及其对行业的深远影响。
双榜夺冠:客观与主观兼优
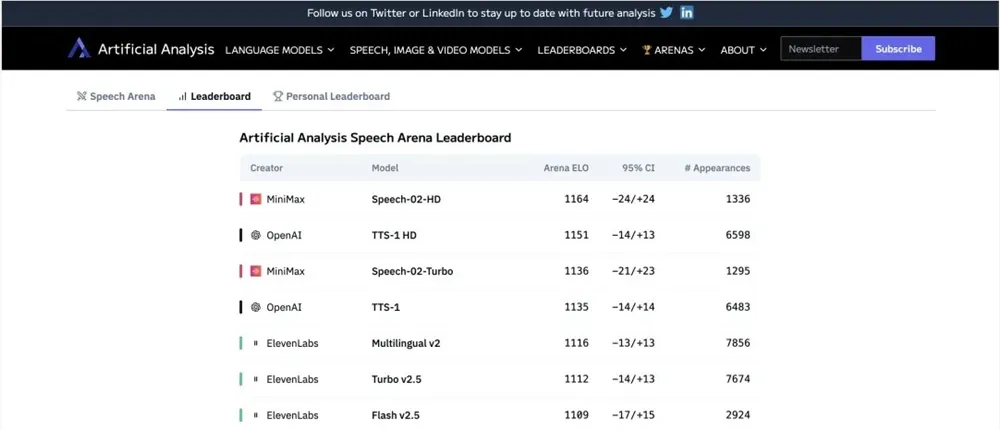
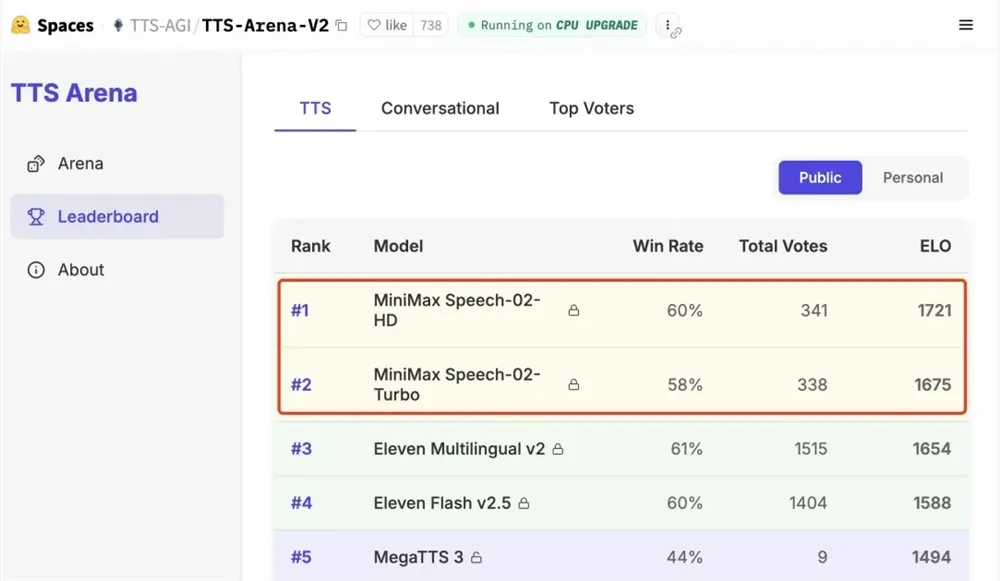
Speech-02系列包括Speech-02-HD和Speech-02-Turbo两款模型,分别针对高保真和实时应用场景优化。在Artificial Analysis Speech Arena的ELO评分中,Speech-02-HD以卓越的语音质量位列全球第一,Speech-02-Turbo紧随其后排名第三。Hugging Face TTS Arena的盲测结果同样显示,Speech-02在用户主观听感上超越了ElevenLabs和OpenAI的最新模型,赢得社区一致好评。
AIbase分析,语音作为兼具客观与主观属性的模态,其评估需结合量化指标和盲测反馈。Speech-02在字错误率(WER)和说话者相似度等客观指标上达到业界领先,同时在主观听感上以99%的真人相似度和零节奏瑕疵,带来流畅自然的听觉体验。这种双重优势使其在播客、有声书和实时交互等场景中表现尤为突出。
技术突破:零样本克隆与多语言支持
Speech-02的核心创新在于其零样本语音克隆和多语言覆盖能力。AIbase了解到,该模型仅需10秒音频即可完成高精度语音克隆,克隆后语音与原声的相似度令人难以分辨。用户可通过简单文本提示生成带有情感表达的语音,支持快乐、悲伤、愤怒等多种情绪调节,极大提升了语音的感染力。
此外,Speech-02支持30+种语言,包括中文、英语、日语、韩语、阿拉伯语等,覆盖全球主要语种,并实现原生发音效果。其动态暂停控制功能允许用户通过<#x#>标签插入0.01至99.99秒的停顿,使语音节奏更自然,适合复杂场景如有声读物和AI配音。AIbase测试显示,Speech-02-HD在生成20万字符的长文本语音时,依然保持稳定性和高质量输出。
架构创新:Flow-VAE与可学习编码器
根据MiniMax的技术报告,Speech-02采用自回归Transformer架构,结合可学习说话者编码器和Flow-VAE技术。前者通过参考音频提取音色特征,无需转录即可实现零样本克隆;后者则增强了音频合成的整体质量,确保音色一致性和表达力。AIbase认为,这种架构设计不仅提升了语音逼真度,还在32种语言的客观评估中刷新了多项记录,奠定了其行业领先地位。
Speech-02的低延迟特性也令人瞩目。Speech-02-Turbo在实时应用中可实现即时音频流输出,生成速度达到每秒数千字符,适合虚拟助手和实时翻译等场景。而Speech-02-HD则专注于高保真场景,如专业配音和有声书制作,满足多样化需求。
行业影响:重塑AI语音应用生态
Speech-02的发布标志着AI语音技术进入高逼真、低成本的新阶段。AIbase观察到,其在Artificial Analysis和Hugging Face的榜首地位引发了广泛讨论,社区开发者纷纷测试其在播客、教育内容和AI助手中的应用。相比ElevenLabs的高定价(约$100/百万字符),Speech-02-HD和Turbo分别以$50和$30/百万字符的定价更具竞争力,为中小企业和独立开发者提供了可负担的选择。
此外,MiniMax通过fal.ai和Replicate平台提供Speech-02的API支持,开发者可轻松集成到现有工作流。AIbase预测,Speech-02的低门槛和高性能将推动AI语音在全球市场的普及,尤其在多语言教育、跨境电商和沉浸式娱乐领域展现巨大潜力。
国产AI的全球突破
作为AI领域的专业媒体,AIbase对MiniMax Speech-02的双榜第一表示高度认可。其零样本克隆、多语言支持和低延迟特性,不仅超越了OpenAI和ElevenLabs,还展现了中国AI企业在语音技术上的全球竞争力。AIbase特别注意到,Speech-02与Qwen3等国产模型的生态协同潜力,或将进一步加速中国AI技术的国际化进程。