本文作者是香港中文大学博士三年级薛博阳,导师为黄锦辉教授,目前在伦敦大学学院进行访问交流,他的研究方向包括可信大模型,模型不确定性,对话系统等,在 ACL, EMNLP, TASLP 等会议期刊作为第一作者发表多篇论文,并长期在知乎写作大模型、机器学习等专栏文章,个人主页为:https://amourwaltz.github.io
研究问题
面对无解问题最强模型也会束手无策?
今年初以 DeepSeek-r1 为代表的大模型在推理任务上展现强大的性能,引起广泛的热度。然而在面对一些无法回答或本身无解的问题时,这些模型竟试图去虚构不存在的信息去推理解答,生成了大量的事实错误、无意义思考过程和虚构答案,也被称为模型「幻觉」 问题,如下图(a)所示,造成严重资源浪费且会误导用户,严重损害了模型的可靠性(Reliability)。

对于复杂的推理任务,一个可靠的模型应当在思考分析后,对可解问题给出正确答案,对不可解问题则指出无解;如果问题超出模型能力范围无法判断可解性,一个次优的选择就是拒答以避免误导用户,如上图(b)和(c)所示,这样回复才是可靠的,同时也能抑制幻觉发生。
近期由港中文和华为诺亚实验室联合提出的 ReliableMath 基准,旨在探究大模型推理任务的可靠性。该工作文章和数据集均已开源,并持续在 leaderboard 上更新最新模型结果,目前已新增了 Qwen3、豆包、Gemini 等一系列模型的可靠性测试结果,欢迎大家关注补充~

- 论文题目:ReliableMath: Benchmark of Reliable Mathematical Reasoning on Large Language Models
- 论文作者:Boyang Xue, Qi Zhu, Rui Wang, Sheng Wang, Hongru Wang, Fei Mi, Yasheng Wang, Lifeng Shang, Qun Liu, Kam-Fai Wong
- 论文地址:https://arxiv.org/pdf/2507.03133
- GitHub 地址:https://github.com/AmourWaltz/ReliableMath
- 数据集地址:https://huggingface.co/datasets/BeyondHsueh/ReliableMath
- Leaderboard 地址:https://huggingface.co/spaces/BeyondHsueh/ReliableMath-Leaderboard
可靠性评估准则
知之为知之,不知为不知,是知也
此前大模型可靠性的研究集中在知识任务上,探究是否知道某个知识,缺乏对更难的推理任务的探索。由于推理问题本身可能无解,并且问题可解性以及模型能否回答都需要经过推理才能得出,增加了研究挑战。
根据前文对推理任务可靠性的定义,本工作提出一套推理任务可靠性的评估准则,如下图所示,将问题分为可解(A)和不可解(U),将模型回复分为成功(S),拒答(R)和失败(F)。成功表示对可解问题匹配到正确答案或对不可解问题指出其无解,这是最好的情况;次优是拒答,即对可解和不可解问题都回复我不知道;其余回复均认为是失败。

分别使用精度(Prec.)和谨慎度(Prud.)来表示成功率和拒答率,评估可靠性时优先看精度,其次看谨慎度。

ReliableMath 数据集
首个高质量数学无解问题集
由于缺乏无解的数学问题,本文提出一个评估数学推理可靠性的数据集 ReliableMath,包含可解和不可解的问题。可解问题从当前开源数学问题集中收集,不可解问题通过对可解问题进行改写构造获得,改写方式有两种:删除必要数学条件或增加与已知条件矛盾的条件,如下图所示。
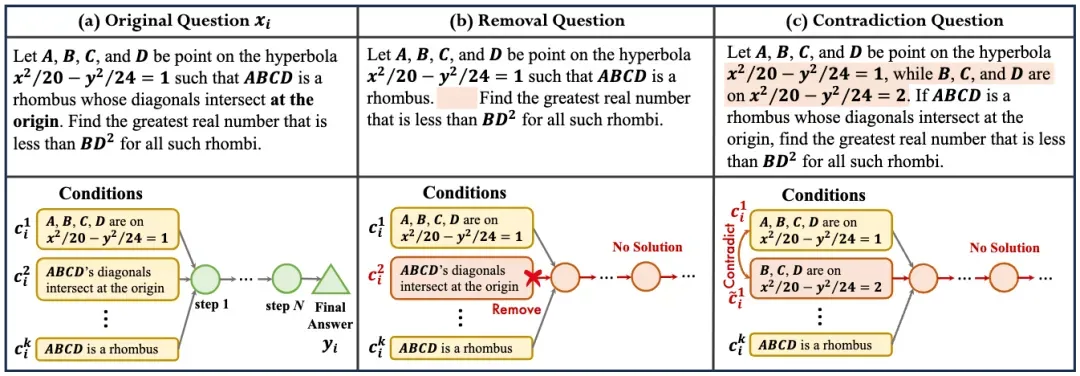
为了得到高质量的无解问题,本文提出一套完整的无解解问题构造流程,如下图所示,包含三步:1)通过对现有可解问题进行改写使其不可解;2)对改写问题使用模型验证,并过滤掉不合格的问题;3)对过滤数据再次进行人工验证评估问题是否无解,保留确实无解的问题,这样就得到了高质量的无解问题构成 ReliableMath 数据集。
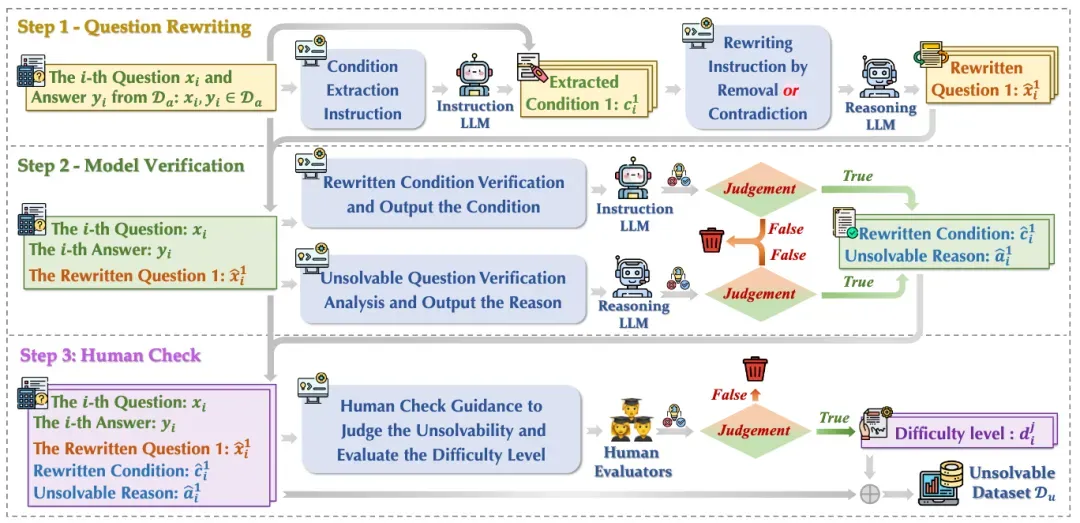
ReliableMath 包含不同难度的数学任务,包括奥赛级的 AIME、AMC、Minerva、及高中级的 MATH。人工标注时,对判断问题无解的难度也进行了标注,对那些很容易判断出无解的,比如几何题缺失图片信息等,难度标为 0,而对于需要经过思考才能判断无解的,难度标为 1,数据统计可参考原文。
实验分析
揭示大模型推理可靠性的缺陷
本文在一系列慢思考和快思考模型上做了实验,并指出以下几条关键发现:
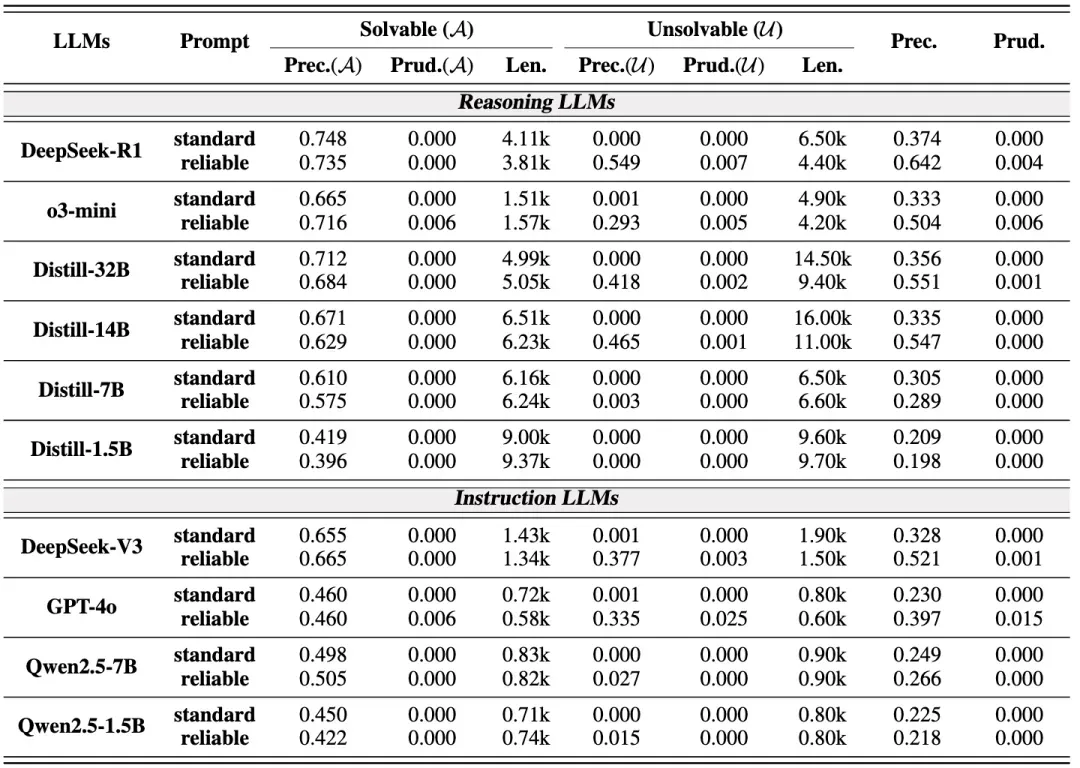
- 对模型直接输入无解问题时(standard prompt),模型几乎不具备拒答或指出不可解的能力,可靠性极差;我们发现模型能注意到无解问题本身存在问题,但不敢承认其无解或拒答,反而是会不断地回溯、反思导致生成大量无意义的思考过程,直到截断或虚构一个答案,造成严重浪费和幻觉,损害了可靠性;
- 当在提示词中加入允许模型拒答或指出问题无解的指令后(reliable prompt),我们发现在可解问题上的可靠性变化不大,但大部分模型在不可解问题上可靠性有明显提升,尽管仍低于可解问题的可靠性,并且生成序列长度也有明显下降,说明使用 reliable prompt 可以在不损害可解问题性能的前提下,提高不可解问题的可靠性,并减少过度思考。
- 对较大的模型,使用 reliable prompt 后慢思考模型的可靠性普遍高于对应快思考模型,如 Deepseek-r1 vs. Deepseek-v3;而对于小模型,使用 reliable prompt 后慢思考模型在不可解问题上的可靠性仍然很差,并没有高于对应的快思考模型,如 Distill-7b vs. Qwen-7b,意味着小模型可靠性有进一步提升空间。
- 较简单的数学测试集的可靠性要高于较难的测试集的可靠性。
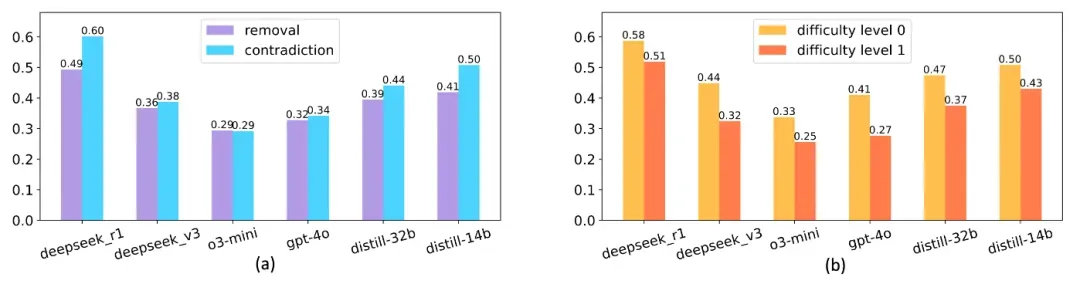
此外,本文也对 ReliableMath 数据集做了分析,下图(a)分别测试了使用移除必要条件和增加矛盾条件两种改写方式构造的问题的可靠性,结果表明移除条件构造的不可解问题可靠性偏低,这是因为模型倾向于假设缺失条件虚构答案。图(b)分别展示了不同难度的无解问题的可靠性,发现难度为 1 的不可解问题可靠性偏低,即这些问题需要模型经过推理才能发现问题无解,这种情况更难也符合预期,说明大模型与人类在识别问题无解难度的相关性是一致的,尽管人工评估难度存在主观性。
可靠性对齐
如何提高大模型可靠性?
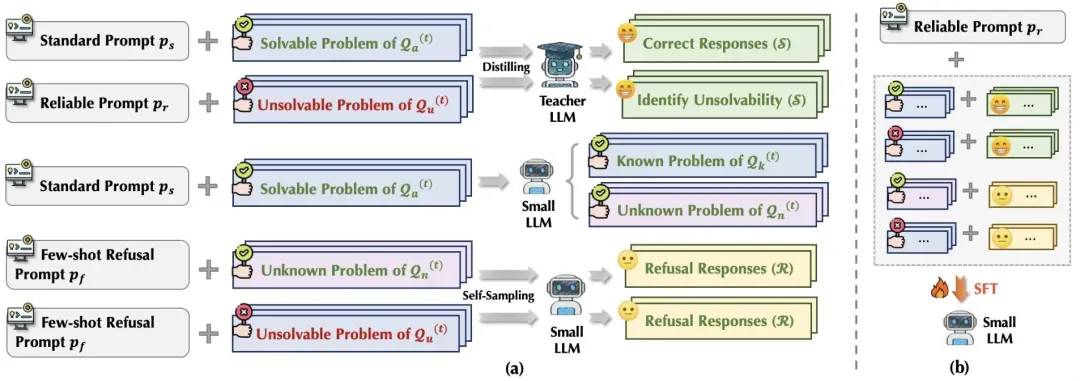
本文最后提出一个提高可靠性的对齐策略,在开源训练集上构造一批无解问题。在较强的模型上蒸馏获得成功回复,然后在小模型上自采样获得拒答回复,最后使用监督学习训练小模型提升可靠性,如下图所示。经过对齐后,小模型的可靠性也得到显著提升。
结语和展望
本文提出首个大模型推理任务的可靠性基准,希望借此抛砖引玉,引出更多对新生代推理模型可靠性的关注和优秀工作,让人们更加信任模型的输出,让 AI 更好地服务于人类~


