当你刚用AI生成了一个精美的电商网站,却在演示时购物车结功能隐藏Bug?AI能在几分钟内生成完整的电商网站,开发者却像“数字农民工”花几小时甚至几天手动测试每个功能、接收每个模块。每次面对新的界面布局,都要重新编写测试脚本,整个流程既低效又很容易出现。这就是当前AI软件领域的核心矛盾:代码生成狂飙突进,测试验收却仍停留在“手工时代”。
针对这一痛点,MetaGPT用户智能体,具备“双重身份”设计:既是一位资深的产品经理,严格按照产品设计和场景边界进行验收;也是一位不知疲惫的AI测试工程师,7×24小时进行全面测试,从源头杜绝“能跑就行”的平庸方案,真正实现代码生成从质量保障的全链路化。
用户智能体技术报告现已正式发布。由DeepWisdom、复旦大学、香港科技大学(广州)、斯坦福大学、耶鲁大学和新加坡国立大学等顶尖机构组成的研究团队,发布RealDevWorld框架,通过AppEvalPilot实现最终自动化结局,专为生产级代码提供自动化需求交互测试,成为AI软件测试力争范级突破。

•论文地址:https://arxiv.org/pdf/2508.14104
•开源代码:https://github.com/tanghaom/AppEvalPilot
• 项目主页:https://realdevworld.metadl.com/
•开源数据集:https://huggingface.co/datasets/stellaHsr-mm/RealDevBench
• 测试成绩对比: https://appevalpilot.realdev.world/
研究背景
人工智能(AI)的快速发展,尤其是大语言模型(LLM)和编程智能体的崛起,正在初步软件开发格局。AI已从最初生成简单的代码片段,发展到能够构建包含图形界面和复杂交互逻辑的完整应用程序。然而,随着能力的高效提升,如何建立全面的评估体系来似乎像复杂软件的质量,特别是包含图形用户界面(GUI)和用户交互的应用,成为未来待的挑战。
现有评估方法依赖于静态代码分析和单元测试,限制了功能级别的功能验证,依赖于人工编写的测试代码,主要适用于基础逻辑功能检测。然而,对于需要通过复杂操作(如绘图、拖拽操作)和动态反馈机制(如实时搜索、游戏操作)进行的功能评估,传统方法缺乏有效的评估能力。生成的软件,如博客网站、工具应用、游戏等,包含丰富的交互操作和功能逻辑,你无法通过单一的代码审查或者静态评估,知道应用程序是否真正“能用”,直到你去点击它、与它交互,并观察它如何响应(“你不知道一个应用程序是否工作,直到你点击它,与它交互,并观察它如何工作”因此,能够模拟人类交互、持续进行动态测试的焦点评估方法关键,它不仅能全面验证功能缺陷和可用性,还能推动人工智能生成软件的质量评估迈向生产等级水准。
如图1所示,软件开发评估基准不断演进:评估方式越来越智能、自主,评估对象也从简单的函数代码开始,逐步划分完整的仓库,最终迈向生产级别的代码质量评估。
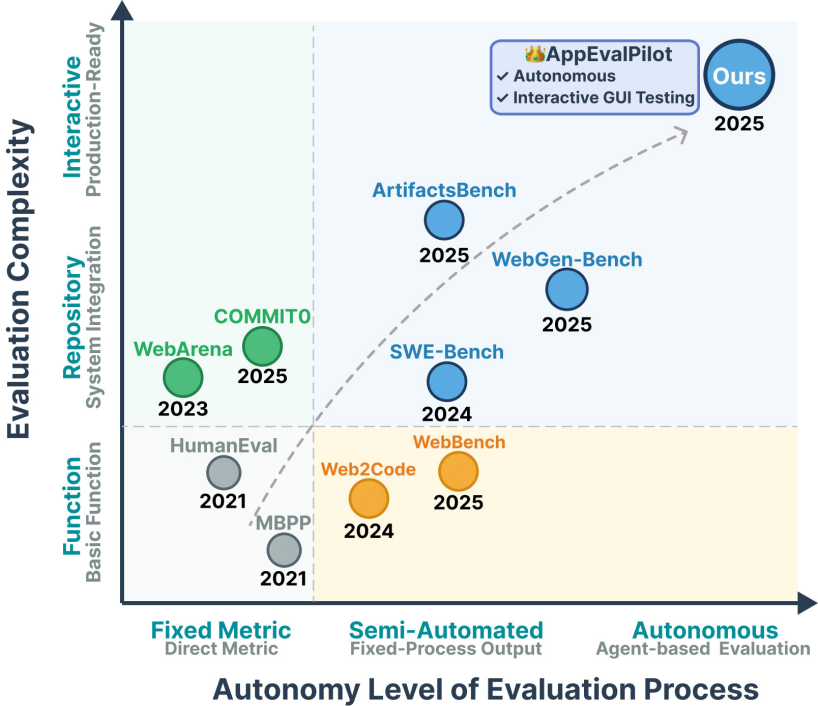
RealDevWorld:全新的评估框架
我们提出了基于“Agent-as-a-Judge”的评估框架 RealDevWorld,包含软件开发任务数据集 RealDevBench和评估智能体 AppEvalPilot。
• RealDevBench:多领域开放软件任务数据集
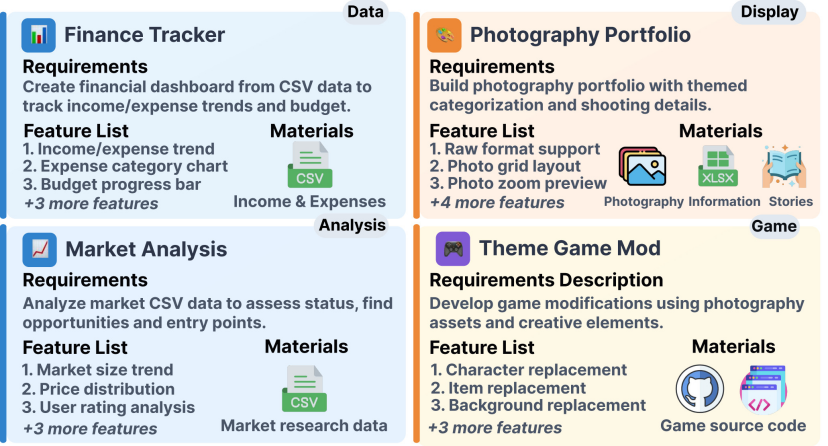
RealDevBench 包含 194 个开放式软件工程任务,覆盖显示、分析、游戏和数据四大领域,具有三大特点:(1)从零构建完整仓库;(2)支持图像、音频、文本、表格等多模态表单输入;(3)框架从组件到动态交互的多层次功能。
如下图所示,RealDevBench中的每个任务由三个部分构成,以模拟真实的软件开发场景:(1)需求描述(需求描述):简要的文本说明,用于万年项目的目的背景和目的背景;(2)功能列表(功能列表):制定的功能目标清单,明确系统需要实现的功能并作为成功的标准;(3)补充材料(补充材料) Materials):与任务相关的额外资源,如图像、音频或数据集,引入更贴近现实的复杂性;
• AppEvalPilot:基于Agent的自动化评估系统
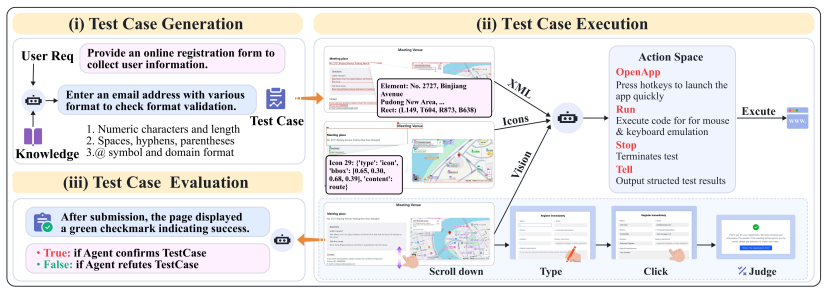
为了实现自动化、端到端的软件交互测试,我们提出了具备GUI能力的评估智能体AppEvalPilot,采用Agent-as-a-Judge范式,模拟用户验收与评估流程,完成从需求到测试的全链条流程。其评估流程分为三个阶段(如下图所示):
1.测试样本生成:结合少样本学习与领域知识(如游戏机制、数据安全协议),自动生成15-20个上下文相关样本,并通过格式提示模拟专业测试工程师。
2.测试示例执行:Agent基于GUI多模态交互能力操作软件,结合A11yTree信息(XML)与视觉信息(OCR、图标、截图等)实现页面解析和元素定位。Agent基于四类原子动作:打开(启动应用程序)、运行(鼠标键盘模拟,如Type、Click、Scroll等)、Tell(输出结果)、Stop(流程),将测试用例转换为排序多步骤执行序列,通过动作自主组合完成表单填写、网页导航、多层结束机制操作等复杂交互。Agent采用Plan-Act执行框架,集成反思实现规划动态调整,结合记忆机制优化关键记录状态,提升长流程任务中的稳定性和自动化能力。
3.结果评估:根据RealDevBench的功能目标,将执行结果分类为 Pass / Fail / Uncertain,生成格式化报告,并量化计算功能列表级别或测试几个级别分数。
评估效果
针对软件质量自动评估能力,我们首先对AppEvalPilot进行了全面的评估,围绕两个关键研究问题:(1)AppEvalPilot能否作为LLM生成的软件的可靠的自动化评估方法的基准评估?(2)与现有评估方法相比,AppEvalPilot评估软件质量的效果如何?
(1)AppEvalPilot能力验证
团队从 RealDevBench 中一批 49 个任务中,分别进行测试级别和功能需求级别的标注,然后分别用 AppEvalPilot 和多个先进的多模态大模型及 GUI 体进行对比,并采用准确性和人工评分一致性进行评估。结果如下表所示,AppEvalPilot 表现出色,在测试中准确性达到 0.92,和人工评分一致性达到 0.81,超过 Claude、WebVoyager等基线;在功能需求级别的评估一致性达到0.85,远超浏览器使用的0.58。同时,AppEvalPilot的单应用的平均评估运行时间为9min,成本平均约为0.26大概。
(二)对比评估分析
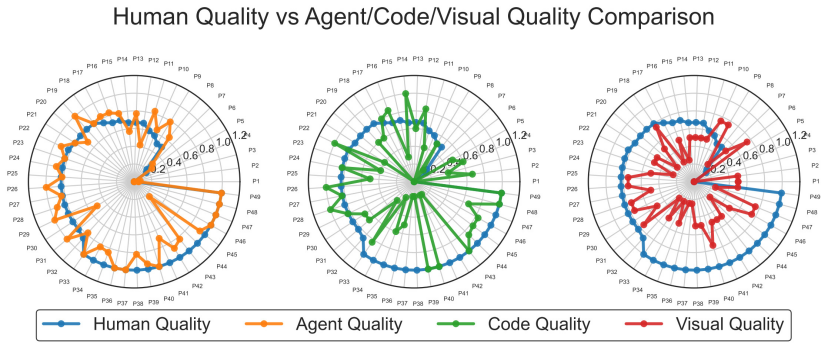
研究团队在49个软件对比了动态评估方法(AppEvalPilot)和两种静态评估方法:代码质量评估(Code Quality)和视觉质量(Visual Quality)。如图所示,实验结果表明,传统静态评估方法存在显着局限性:代码质量评估和视觉质量评估的偏差分别比AppEvalPilot高出2.79倍和3.34倍,而AppEvalPilot与人工评估的重合率达到0.96,凸显了动态交互的重要性。
(3)RealDevBench评测分析
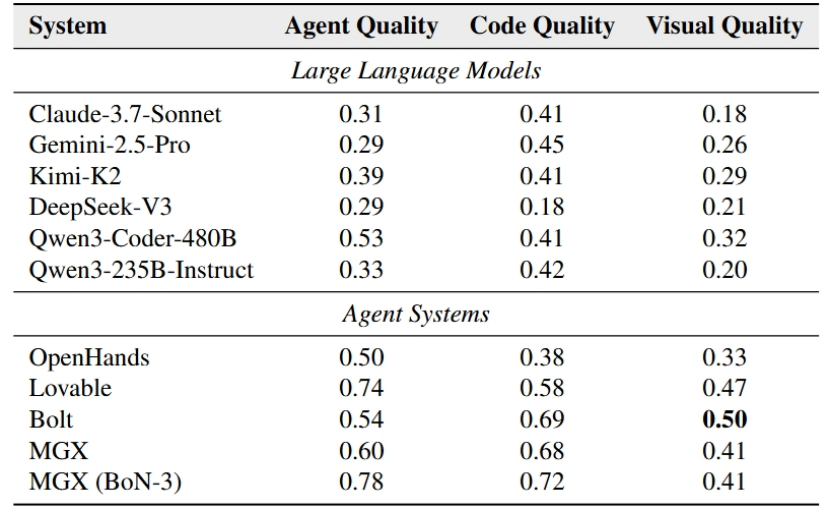
研究团队基于RealDevBench-Test对多种先进LLM、Agent系统的代码生成能力进行了全面评估(见下图)。结果表明,单一LLM在真实软件开发场景中表现有限,甚至是最新的Kimi-K2、Claude-3.7-Sonnet等先进模型,软件质量评分仍低于0.4,普遍存在交互不完整、功能解除和可部署性差等问题,而纯和静态代码无法充分校准这些限制。相比之下,Agent系统在复杂的软件开发任务上具备优势,在Agent质量上较LLM平均提升0.27,这主要是由于Agent系统能够结合设计、开发、执行验证等来提升代码可用性。
开启全自主质控新时代
AI代码生成爆发式增长,传统评估方式难以面对胜任,自主评估为大规模落地应用提供了新范式。RealDevWorld通过AppEvalPilot实现端到端自动化分数,全面覆盖软件功能完成度、交互可用性和动态运行表现。
这不仅仅是体育工具的改进,更是自动化评估范式的变化。当AI系统能够像资深工程师一样自主思考软件质量,像经理产品一样自动化反馈用户体验,像测试专家一样自动识别潜在问题时,我们正在见证从人工把关到智能自治质控的覆盖。
“我们要让测试验收像代码生成一样的智能,彻底告别手动测试时代高效,”项目负责人表示。这一突破意味着从个人开发者到大型科技公司,都将告别“AI生成代码、人工手动测试”的低效模式,将开发者从繁重的手动测试中解放出来,专注于创新功能开发和架构优化,真正期待目标开发新时代。


