Meta FAIR部门的研究员François Fleuret发布了一篇名为《The Free Transformer》的论文,提出了一种对现有解码器Transformer模型的精妙扩展。

这项技术的核心,是让模型在生成每个字之前,能先在内部形成一个类似计划或草稿的隐性决策,而不是像过去那样,只能边写边想。
实验证明,这种先计划,后执行的模式,在编程、数学和推理等任务上带来了显著的性能提升。
AI写作的惯性困境
我们今天所熟知的解码器Transformer,比如GPT系列,模型在生成一段话时,是逐字(token)进行的。它预测下一个字,完全依赖于它已经生成的所有前面的字。
假设我们想训练一个模型来写电影评论,评论有正面和负面两种。
一个标准的解码器Transformer当然可以学会写这两种评论。但它的工作方式是,一个字一个字地吐。它可能写了几个字之后,根据已经写出的这部电影,来判断接下来应该接很精彩还是很糟糕。
它并没有一个全局的、预先的决定:我现在要写一篇负面评论。这个负面或正面的概念,是随着文字的生成,隐含在概率计算中的一种后续推断。
这种模式存在几个潜在的问题。
它需要模型具备非常大的容量和复杂的计算,才能从已经生成的零散词语中,反推出一个全局的意图,这很低效。
如果生成过程的早期,有几个词出现了偏差、模棱两可或者前后矛盾,整个生成过程就可能跑偏,后面再也拉不回来。
关键的概念,比如正面或负面,不是模型主动构建的,而是在拟合训练数据时被动形成的。这使得模型在面对分布外的数据时,可能表现得很脆弱。
Free Transformer让模型拥有了自由意志
Free Transformer的核心思路是,在模型的自回归生成过程中,引入一些额外的、不受训练样本直接控制的随机变量,让模型可以依据这些变量来调整生成。
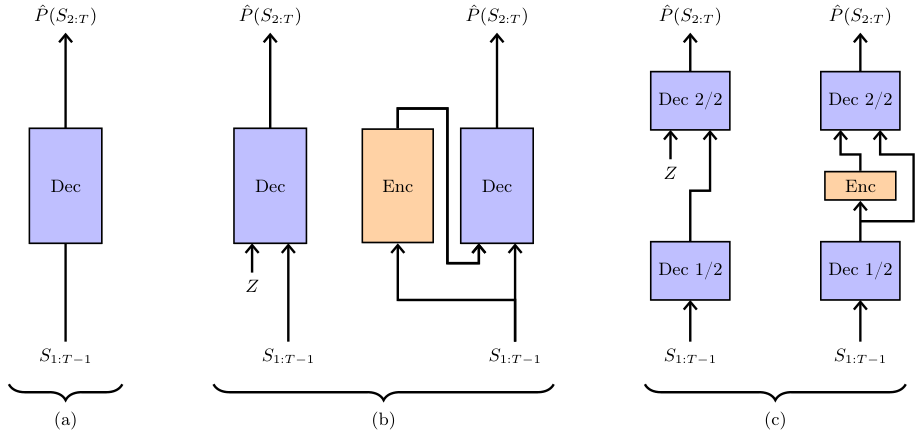
回到电影评论的例子。模型可以先用一个内部的随机布尔值,一次性决定接下来要生成的是一篇正面评论,还是一篇负面评论。
有了这个全局性的决策,模型就不再需要从已经生成的零散词语中费力地推断意图。
实现这个想法,需要借助一种名为变分自编码器(Variational Autoencoder,简称VAE)的框架。
在生成新内容时,过程很简单:模型先采样一个随机变量Z,然后像普通的Transformer一样,基于这个Z去生成整个序列。
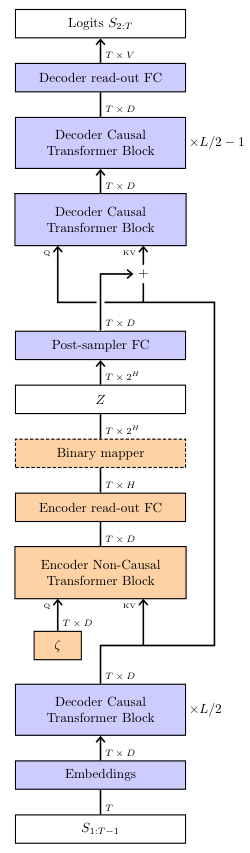
挑战在于训练。我们希望模型学会将有意义的信息(比如评论的情感)编码到Z里面。
这就需要一个编码器(Encoder)。在训练时,编码器会读取一个完整的训练样本(比如一篇已有的正面评论),然后生成一个与之匹配的Z。解码器(Decoder)再利用这个Z,尝试去重建原始的评论。
通过联合优化编码器和解码器,模型就学会了如何将序列的全局属性(情感、主题等)压缩进Z,并利用Z来指导生成。
这里有一个关键点:必须限制从编码器流向Z的信息量。否则,编码器可能会耍小聪明,直接把整个原文复制到Z里,解码器就可以躺平了。这在训练时看起来很完美,但在实际生成时,没有了编码器,模型就什么也做不了。
VAE理论通过计算Z的分布与一个标准先验分布之间的KL(Kullback-Leibler)散度来控制信息量,并将其作为一个惩罚项加入到总的损失函数中。
Free Transformer的结构设计非常巧妙。它不是一个全新的模型,而是对标准解码器Transformer的微小改造。
它将随机噪声Z注入到模型的中间层。
更妙的是,编码器直接复用了模型的前半部分网络层,只增加了一个额外的、非因果的Transformer块和两个线性层。
非因果意味着这个块可以同时看到整个输入序列,这对于捕捉全局信息至关重要。
这种设计,对于一个28层的1.5B模型,额外开销大约是1/28,约等于3.6%。对于一个32层的8B模型,开销约为1/32,即3.1%。
用约3%的计算开销,带来大幅性能提升,这几乎是免费的午餐。
实验证明了它的有效性
为了验证Free Transformer是否真的学会了利用潜变量Z,研究人员设计了一个巧妙的合成数据集。
每个数据样本的生成规则如下:
- 以64个下划线_开始。
- 随机选一个大写字母,在序列的随机位置,用8个该字母组成的目标替换掉下划线。
- 以很小的概率,将任意字符替换为感叹号,作为噪声。
- 在末尾附上一个提示,比如 a>,告知目标字母是什么。

研究人员用这个数据集训练了模型,并设置了不同的KL散度阈值(κ),这个阈值控制了模型可以往Z里塞入多少信息。

结果非常直观。
当KL阈值很低时,模型几乎不使用Z,表现和普通Transformer一样(图左上)。所有生成的序列都各不相同。
当阈值稍微提高,模型开始将目标的位置信息编码到Z中。在图右上的绿色框里,所有序列共享同一个Z,它们的目标都出现在了相同的位置。
当阈值进一步提高,模型不仅编码了位置,还编码了噪声(感叹号)的模式。图左下的绿色框里,不仅目标位置一样,连感叹号出现的位置都完全一样。
当阈值过高时,模型开始作弊,把整个序列的信息都塞进了Z,导致生成出错(图右下)。
这个实验清晰地证明,Free Transformer学会了根据任务需求,自主地将最关键的全局信息(目标位置、噪声模式)打包到潜变量Z中。
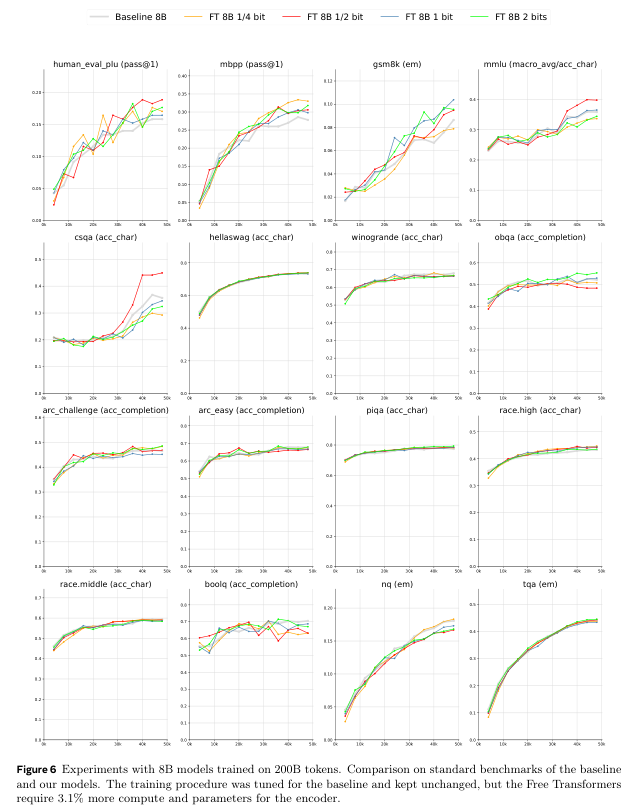
接下来是真实世界的基准测试。研究人员使用了1.5B和8B两种规模的模型,与结构相同的标准解码器Transformer进行对比。
为了保证公平,所有超参数都沿用基线模型的设置,没有为Free Transformer做特殊优化。
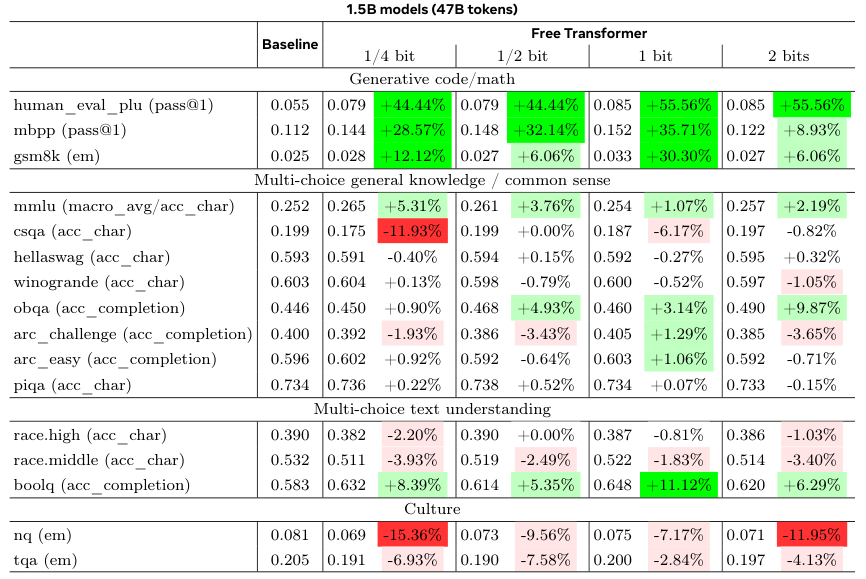
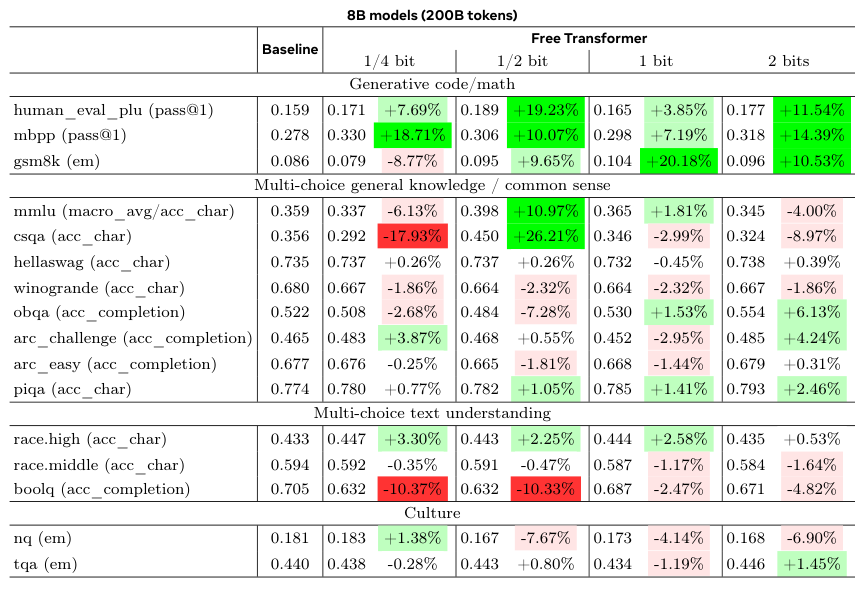
结果显示,在HumanEval+(代码生成)、MBPP(代码生成)和GSM8K(小学数学应用题)这些需要推理能力的基准上,Free Transformer取得了显著的性能提升。
在8B模型上,当每个token允许引入半比特信息时,性能提升最为明显。
为了验证这种改进在更大规模的训练下是否依然存在,研究团队用1T(万亿)级别的token训练了8B模型。
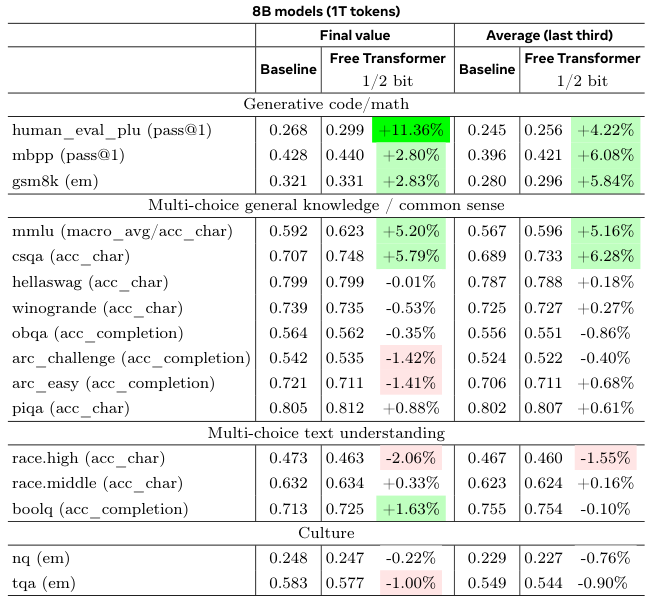
结果再次证实了之前的发现。无论是在训练结束时还是在训练后期的平均性能上,Free Transformer在推理、数学和多项选择问答任务上都稳定地优于基线模型。
这项工作意味着什么
Free Transformer用一种极为高效的方式,对标准解码器Transformer的归纳偏置(inductive bias)进行了改进。
它让模型有能力无监督地学习数据中存在的潜在结构,并利用这些结构来指导内容生成。
在某种意义上,这与思维链(Chain-of-Thought)或强化学习中的推理模型(如DeepSeek-R1)有异曲同工之妙。后者是在token层面,通过显式的文本来进行推理;而Free Transformer则是在模型的潜在空间(latent space),通过自编码的方式,进行一种更底层的、隐式的规划。
将这两种方法结合起来,无疑是一个充满潜力的研究方向。
这项工作仅仅是一个开始。研究人员指出,模型的训练过程有时不稳定,这可能是编码器和解码器优化过程耦合导致的,未来可以探索不同的优化策略。随机嵌入Z的形式也可以有多种选择。
它在更大规模的模型和数据集上的表现,仍有待进一步探索。
这项研究给我们的启示是,即使在Transformer架构已经非常成熟的今天,对其核心的自回归机制进行微小而深刻的改造,依然能带来意想不到的性能飞跃。
AI不仅在学习如何说话,更在学习如何思考。


