首份最全ChatGPT用户研究报告来了!
就在刚刚,OpenAI联合哈佛大学经济学家David Deming发表了一篇新论文——
标题为《How People Use ChatGPT》,详细论述了ChatGPT从2022年11月上线到2025年7月的被使用情况。
 图片
图片
为什么要在这个节点推出报告,或许这也和ChatGPT取得的阶段性成果有关。
截至今年7月,ChatGPT的周活跃人数已经超过7亿,每周发送的消息总量达到180亿条。
面对这一庞大用户群及消息量,论文通过分析150万次大规模对话核心想了解:
- 人们都在用ChatGPT干什么?
- 究竟是谁在用ChatGPT?
如果你也对这些问题感兴趣,不妨接着看——
人们用ChatGPT干什么?
对于第一个问题,首先需要强调一点:
和以往基于问卷调查的方式不同,这一次研究团队主要基于内部对话数据,采用自动化分类器并结合隐私保护方法来分析ChatGPT的实际使用情况,可以说更科学合理了。
具体数据集可以分为三类:
1、Growth数据集:2022年11月~2025年9月所有消费者计划(Free/Plus/Pro)的消息总量与基础人口统计。
2、分类消息样本:2024年5月~2025年6月随机抽取约110万条去标识化消息,用LLM分类器标注用途、主题、交互类型。
3、就业数据:约13万用户的职业与教育(来自公开资料),通过数据Clean Room做聚合分析。
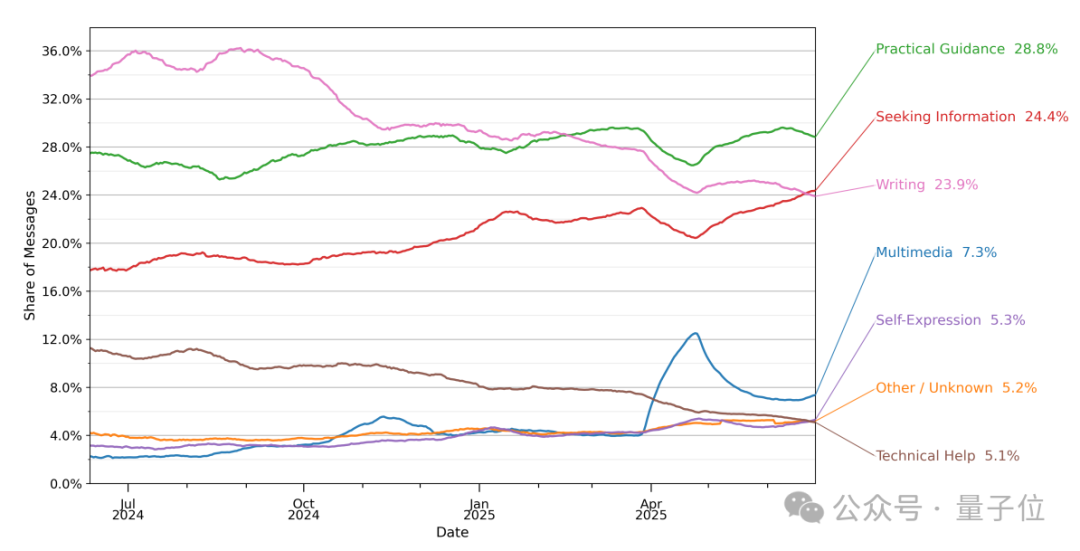
基于以上数据,论文发现ChatGPT主要被用来完成日常任务。
四分之三的对话侧重于实用指导、信息搜索和写作。其中写作是最常见的工作任务,而编程和自我表达仍然是小众活动。
三大主要使用类型的具体占比如下:
- 实用指导(28.8%):如个性化健身计划、创意构思、技能教学等;
- 信息搜索(24.4%):人物/事件信息、食谱、产品咨询等;
- 写作(23.9%):邮件 / 文档生成、文本编辑、翻译、总结等。
而像计算机编程、社交(如人际关系反思、游戏角色扮演等)这样的需求则相对占比较小。
 图片
图片
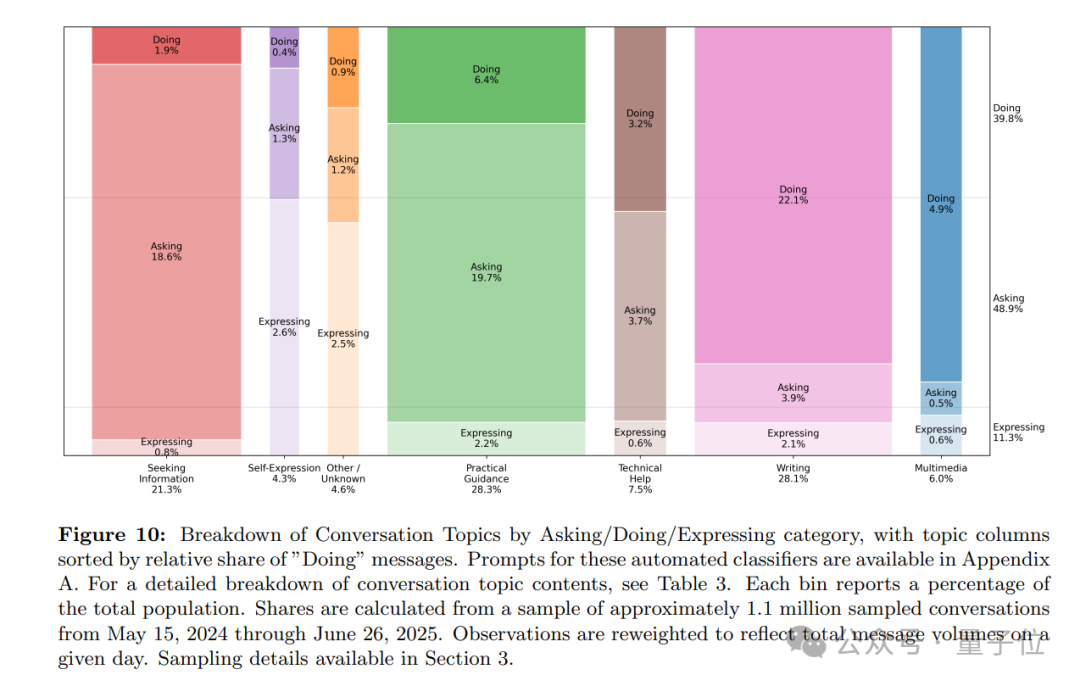
此外,人们使用ChatGPT的模式也可以分为三类:询问(Asking)、行动(Doing)和表达(Expressing)。
结果发现,大约一半的消息(49%)属于“询问”,这是增长最快、用户评价最高的类别,说明人们更倾向于将ChatGPT视作顾问,提供建议和决策参考,而非简单地完成任务。
“行动” 类占40%,其中约三分之一与工作相关,包括起草文本、规划或编程。
“表达” 类占11%,主要涉及个人的反思、探索和娱乐,而非明确的问题求助或具体任务。
 图片
图片
小结一下,目前ChatGPT主要还是担任顾问角色,且最常被用于实用指导、信息检索和写作。
重点提醒,为了在研究过程中保护用户隐私,他们核心采取的措施如下:
一是在分析用户消息时,没有人能直接查看原始消息内容,而是通过自动化工具对去标识化和隐私信息被删除后的数据进行分析。
二是研究团队无法直接访问个人级别的详细信息,并且不会对少于100名用户的群体进行数据汇总。

那么接下来的问题是——
都是谁在用ChatGPT?
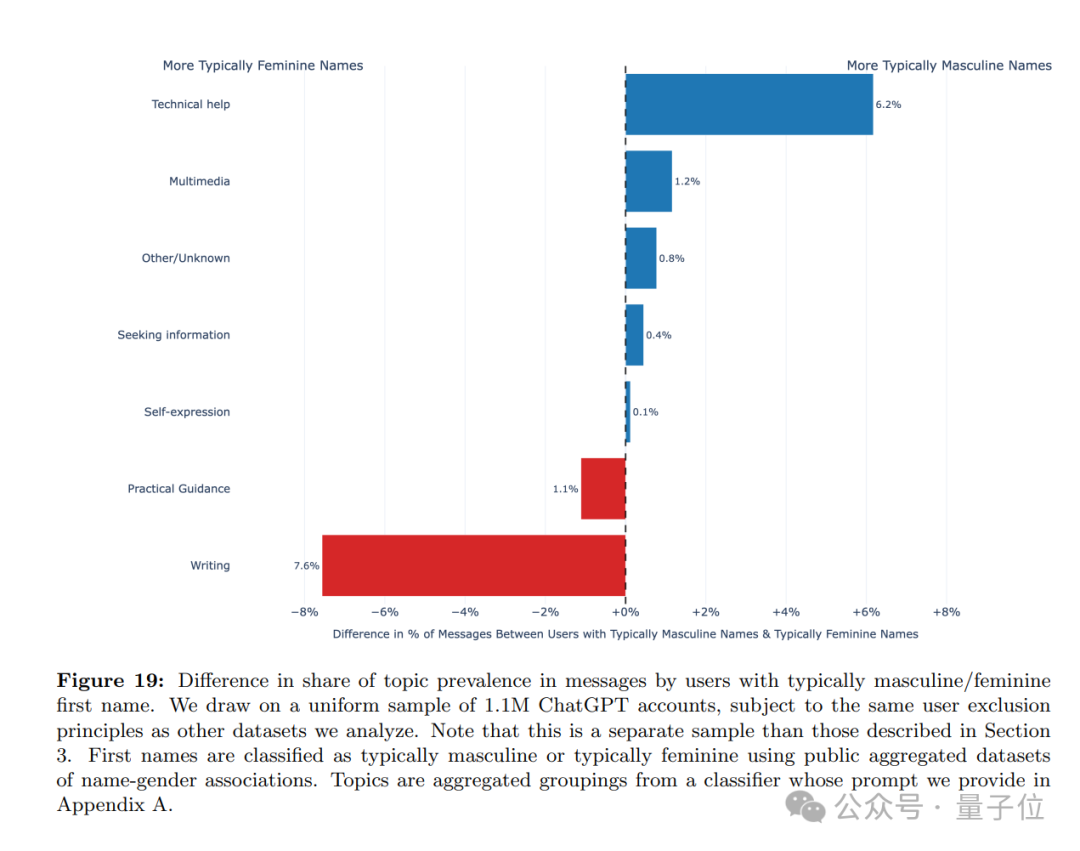
关于使用人群,论文得出的最核心观察是:ChatGPT的性别差距已经大幅缩小。
在早期阶段(2022年底-2023年初),大约80%活跃用户为典型男性名字,而到今年,典型女性名字用户占比却实现了反超:
男性名字已下降至48%,女性略超男性,性别使用差距基本消除。
 图片
图片
从年龄分布来看,18-25岁用户属于成年用户中使用ChatGPT最多的,贡献了46%的消息量。且年龄越大,工作相关消息占比越高。
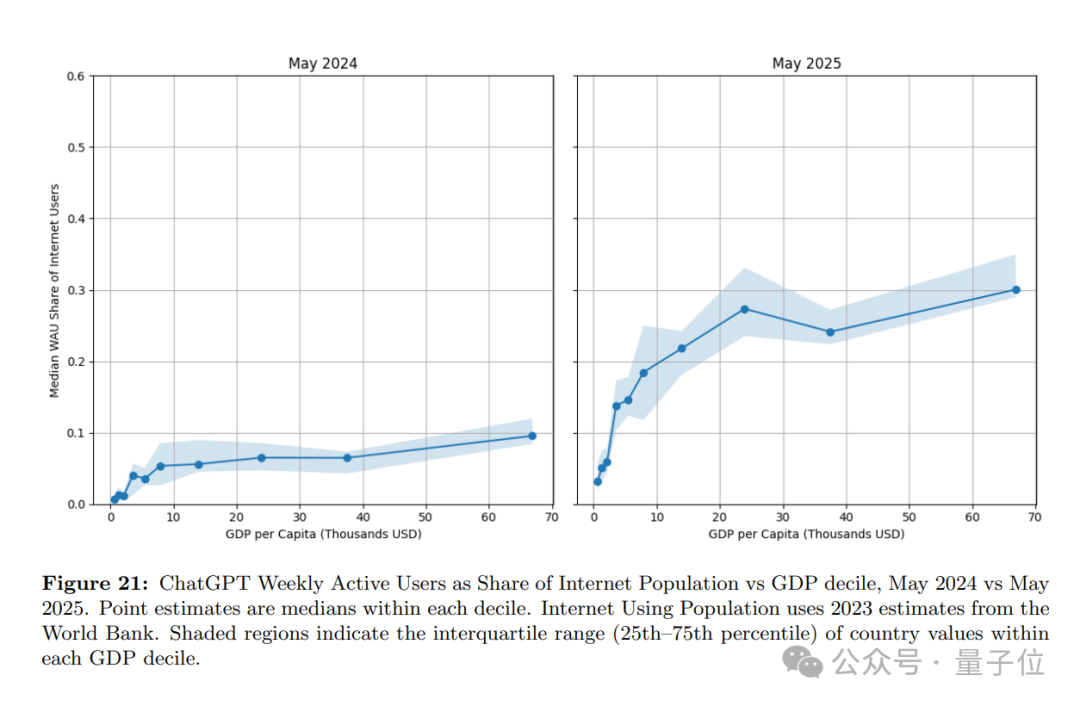
此外,从用户分布地区的经济水平来看,ChatGPT尤其在中低收入国家增长迅速。
截至今年5月,ChatGPT在最低收入国家的使用增长率是最高收入国家的4倍以上。
 图片
图片
总之,从用户数据来看,ChatGPT仍在被进一步普及。
更多细节欢迎查看完整报告。
完整论文:https://www.nber.org/system/files/working_papers/w34255/w34255.pdf
参考链接:[1]https://openai.com/index/how-people-are-using-chatgpt/[2]https://x.com/dotey/status/1967580799844413915?s=46


