谷歌和DeepMind联合发布了一个全新的开源人工智能模型套件:MedGemma。
这一套件面向医疗领域打造,不仅支持文本、图像和多模态输入,还能广泛适配放射学、皮肤病学、组织病理学和眼科学等多个分支。
它在今年的I/O开发者大会上首次亮相,MedGemma包含两个版本:一个是体量为40亿参数的4B模型,支持图文混合处理;另一个是更强大的270亿参数的27B模型,提供文本和多模态两种版本。
 图片
图片
地址:https://huggingface.co/google/medgemma-27b-it
谷歌明确表示,MedGemma可以独立运行,也可以嵌入基于智能体的系统中,作为医疗AI工具的基础模块。
开源,使得这套系统可以被全球研究人员和开发者自由使用,但不能直接用于诊断和治疗,需通过相关监管审批。
 图片
图片
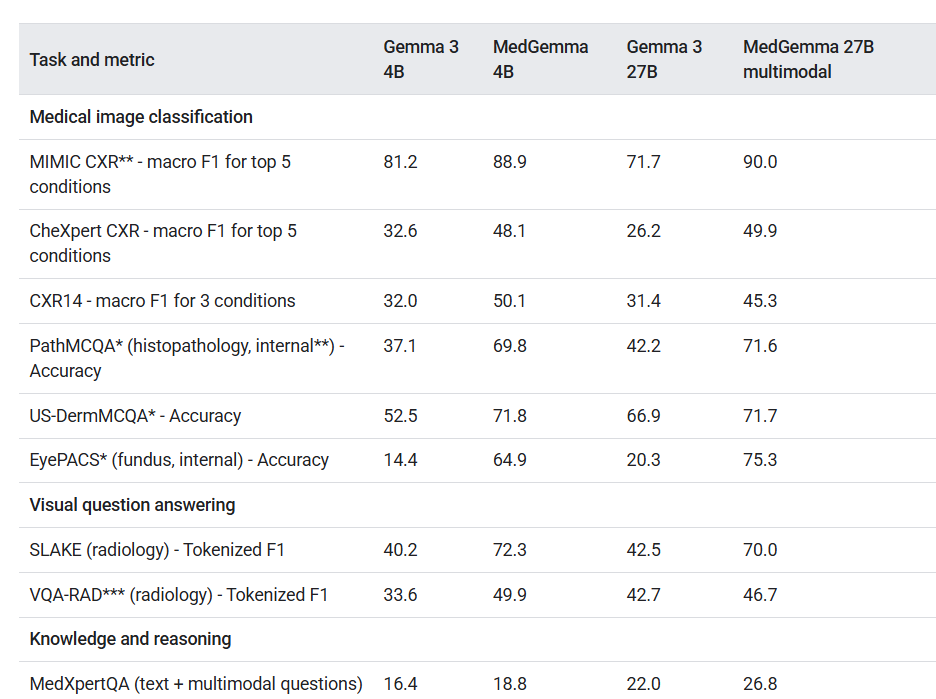
MedGemma在多个标准模型基准测试中表现出色,全面超越同级别的基础模型。
在多模态问答任务中,准确率提升达10%;在X光图像分类上,提升幅度达到15.5%至18.1%;在复杂的智能体任务中,表现提高10.8%。
在医疗考试数据集MedQA中,4B模型准确率从原来的50.7%跃升至64.4%;而27B模型则从74.9%提升至87.7%。
 图片
图片
图注:MedGemma 27B 多模态模型在医学图像分类和视觉问答任务中表现最佳,显著优于其他模型。
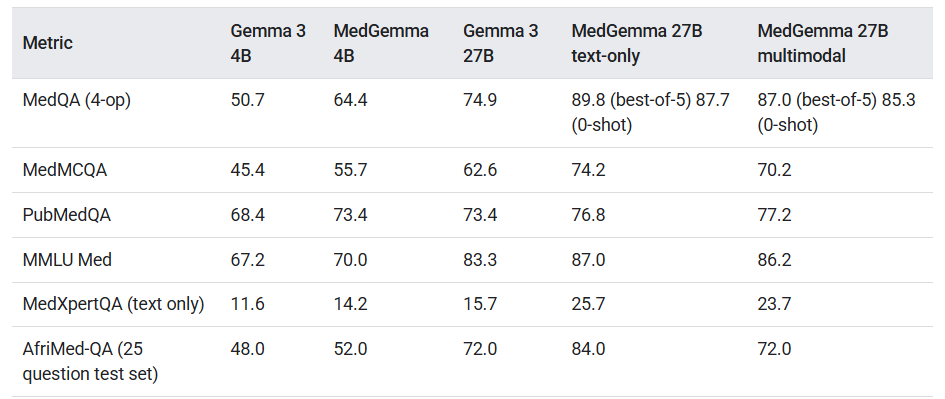
在PubMedQA、MedMCQA、MMLU等多个医疗子领域的基准测试中,MedGemma持续领先于其基础模型。
 图片
图片
在X光图像与报告的数据集MIMIC-CXR中,4B模型的宏观F1得分达88.9,相比之下,其基础模型Gemma 3仅为81.2。
F1得分是衡量模型在多种疾病识别中的整体准确率,它的提升意味着模型对复杂临床图像的理解能力增强。
在自动生成X光报告方面,模型的RadGraph F1从29.5提升到30.3,表明临床关键信息捕捉能力增强。
对于气胸检测任务(即肺部塌陷),准确率从59.7%提升至71.5%,显示出实质性的突破。
组织病理图像分析方面,模型的加权F1得分从32.8跃升至94.5,几乎达到三倍提升。
在电子健康记录的读取任务中,引入强化学习后错误率下降一半,预示着在临床数据管理中有巨大潜力。
谷歌同步推出了一项重要组件:MedSigLIP
 图注:https://arxiv.org/pdf/2303.15343
图注:https://arxiv.org/pdf/2303.15343
这是一个专为医学图像设计的编码器,拥有4亿参数,是原始SigLIP(Sigmoid Loss for Language Image Pre-training)的医疗扩展版。
MedSigLIP专注于医学图像的理解,配合MedGemma处理文本,构成完整的多模态AI架构。
图像处理分辨率设定为448×448像素,比MedGemma高分辨率版本的896×896更高效。
为了构建通用能力与医学能力兼具的模型,谷歌以3360万对图文配对数据进行训练,其中包含63.5万条医学实例和3260万个组织病理图像块。
医学数据占比约为2%,在保留SigLIP通用图像识别能力的基础上,增强了医学图像理解能力。
这一平衡策略的关键意义在于:模型不仅能处理医疗图像,也可用于通用图像任务,适配多场景需求。
目前,MedGemma已在Hugging Face上线,开发者可以依据其许可协议用于科研、开发与一般AI应用,但在商业化和临床场景中仍需遵循相关限制。
尽管在多个测试中表现惊艳,谷歌也承认:基准测试成绩并不能完全代表临床真实表现。现实中的使用情境更复杂,模型可能因用户误解或交互失误而出现偏差,限制了实际疗效。
地址:https://huggingface.co/google/medgemma-27b-it


