据百灵大模型公众号,近期蚂蚁百灵团队了开源兼具 SOTA 性能 与 高效性 的 MoE 架构大语言模型系列Ling 2.0,发布首个版本 Ling-mini-2.0。
据了解,Ling-mini-2.0体量小巧,却性能十足。它具备16B总参数,但每个输入 token 仅激活其中的 1.4B(non-embedding 789M)。在超过 20T token 的高质量语料上完成预训练,并通过多阶段的监督微调与强化学习显著提升了复杂推理与指令遵循能力。这使得它在仅有 1.4B 激活参数的情况下,依然达到 10B 以下 dense LLM 以及同等或更大规模MoE模型的顶尖水平。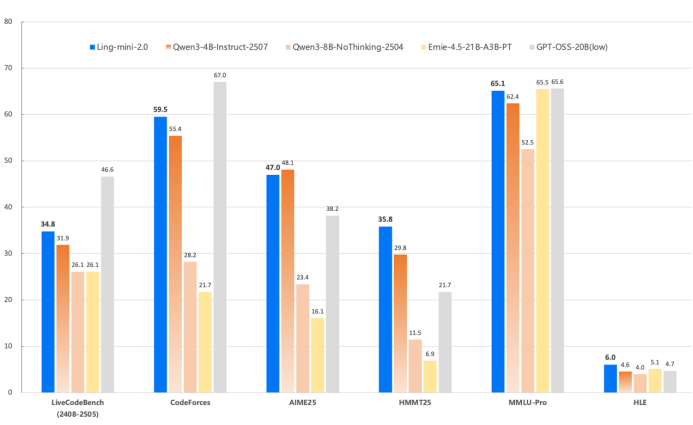
(Ling-mini-2.0性能表现)
蚂蚁百灵大模型团队在高难度的代码(LiveCodeBench、CodeForces)、数学(AIME 2025、HMMT 2025)等通用推理任务,以及覆盖多个专业学科的知识型推理任务(MMLU-Pro、Humanity's Last Exam)上对模型进行了测试。与 10B 以下的 dense 模型(如 Qwen3-4B-instruct-2507、Qwen3-8B-nothinking 等)以及同等或更大规模的 MoE 模型(Ernie-4.5-21B-A3B-PT、GPT-OSS-20B/low)相比,Ling-mini-2.0 展现了出色的综合推理能力。
Ling 2.0 沿用了蚂蚁在MoE架构方面探索出的优势,采用 1/32 激活比例的 MoE 架构,并在专家粒度、共享专家占比、attention 占比、aux-loss free + sigmoid 路由均衡策略、MTP 层、QK-Norm、half RoPE 等多方面实现经验最优,使得小激活 MoE 也能获得 7 倍以上等效 dense 架构的性能杠杆。也就是说,Ling-mini-2.0 仅凭 1.4B(non-embedding 789M)激活参数,即可等效撬动 约 7~8B dense 模型的性能。
值得注意的是,高度稀疏的小激活 MoE 架构带来了显著的训推优势。在 2000 token 以内的简单问答场景中,Ling-mini-2.0 的生成速度可达 300+ token/s(H20部署),相较 8B dense 模型快 2 倍以上。Ling-mini-2.0 通过 YaRN 外推可支持 128K 上下文,随着输出长度增加,其相对加速比最高可达 7 倍以上。
Ling 2.0 全流程采用 FP8 混合精度训练。与 BF16 对比发现,在超过 1T token 的训练量上,两者在 loss 曲线与数十个下游 benchmark 上几乎一致。为帮助社区在有限算力下高效继续预训练与微调,蚂蚁百灵大模型团队已开源 FP8 训练方案。
蚂蚁百灵大模型团队认为Ling-mini-2.0 是 MoE 模型研究的理想起点。它在小规模下首次集成了1/32稀疏性、MTP 层、FP8 训练等特性,并在效果与性能上都表现突出,有望成为小尺寸语言模型的首选。
为推动社区发展,蚂蚁百灵大模型团队不仅开源了发布后训练版本外,还开放了 5 个预训练版本,包括后训练前的 Ling-mini-2.0-base,以及覆盖 5T、10T、15T、20T token 的四个阶段 base 模型,助力社区开展更深入的研究与应用。