鹭羽 发自 凹非寺
量子位 | 公众号 QbitAI
何恺明残差学习奠基人的身份,也被“挑战”了。
为什么要说“也”?因为发起讨论的,又双叒是我们熟悉的Jürgen Schmidhuber——LSTM之父。
不过这一次,他不是要把功劳揽到自己身上,而是替LSTM的另一位作者Sepp Hochreiter发声:
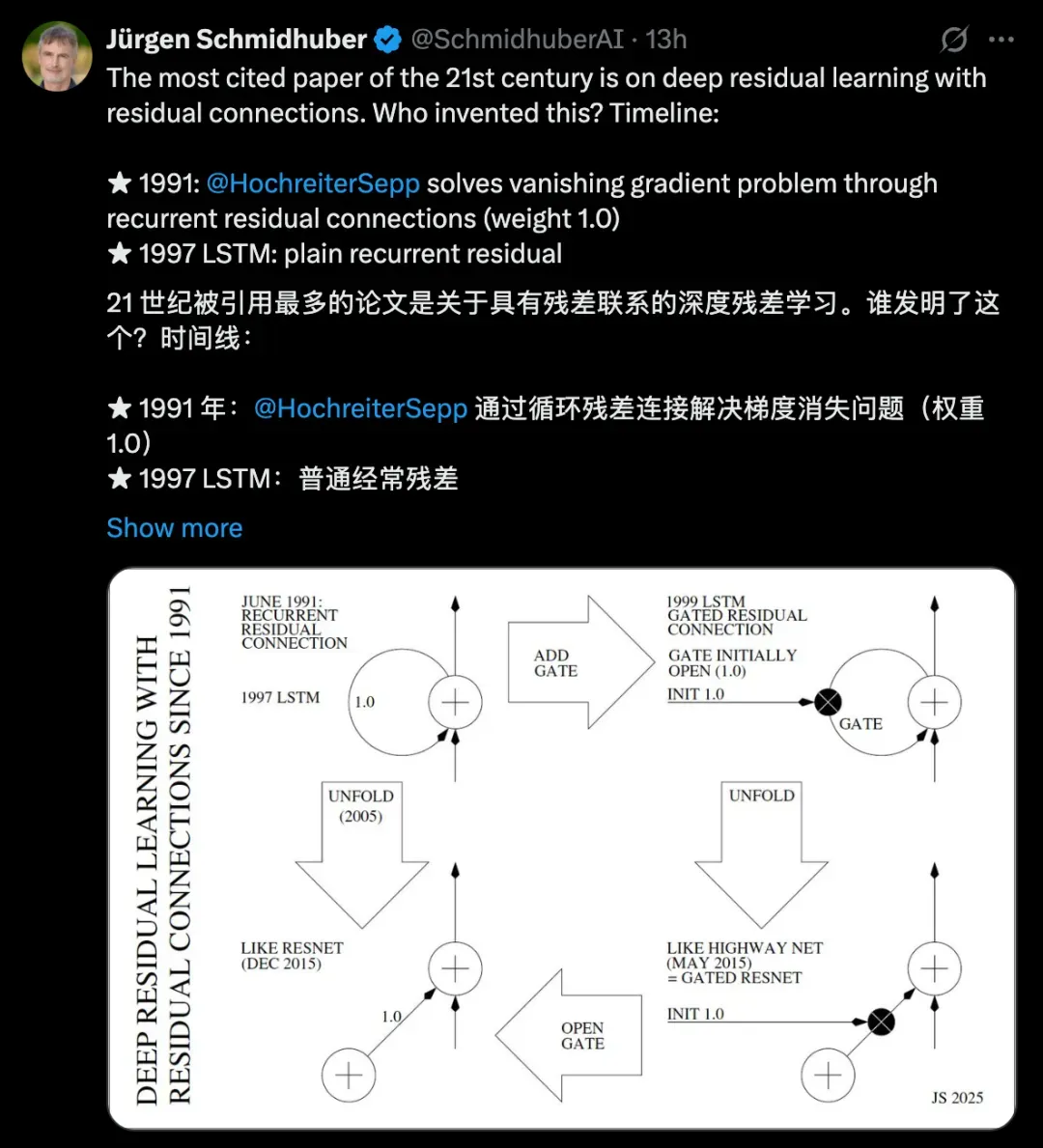
残差学习这把改变深度学习格局的 “钥匙”,其实早在30年前就已经诞生——Sepp Hochreiter在1991年就在使用循环残差连接解决梯度消失问题。
有一说一,Jürgen争title也不是第一次了,作为深度学习的先驱者,Jürgen自认为自己的早期贡献被人为忽视了。
ResNet发布的同年,深度学习三巨头Bengio、Hinton、LeCun在Nature上联合发表有关DL的综述论文,其中大量引用他们三人的自身成果,却对Jürgen等人只字不提。
随即他们展开了长达多年的争论,尤其是在18年的图灵奖结果公布后,Jürgen更是洋洋洒洒写了篇援引200多条文献的小作文反击。
之后在GAN的原创争议上,双方也是争执不休,要知道GAN的提出者正是Bengio的得意门生。
而如今有关残差学习的创始之争,也是因为Jürgen自认为将残差学习这一成果的发现完全归因于何恺明团队有失偏颇。
不过正如网友所说:
从Hochreiter到ResNet,光芒随时间递归延续。阴影是被模糊的归属,但真理始终不变:1991年的种子闪耀着每一层。

Jürgen Schmidhube这次要讲的故事始于1991年。
当时还是Jürgen学生的Sepp Hochreiter,正在着手撰写自己的博士论文,也正是在这篇论文里,他首次系统性分析了RNN的梯度消失问题,并提出用循环残差连接解决。

循环残差连接的核心思想相当简单:一个具有恒等激活函数的神经单元自连接,且权重固定为1.0,使其在每个时间步中仅将输入叠加到先前状态,该单元只作为增量积分器存在。
于是误差信号就能在反向传播中保持恒定,不会消失或爆炸。
不过与此前任意实数权重的自连接不同,只有权重严格为1.0,才能完全避免梯度问题。
接近1.0的近似值虽然可以接受,但衰减速度会随时间加快,例如0.99的权重下误差信号会在100个时间步后减少到原来的37%(0.99¹⁰⁰≈37%),0.9的权重则只有原来的0.0027%(0.9¹⁰⁰≈0.0027%)。
但尽管如此,这也为后来的深度学习残差思想奠定了理论基础。
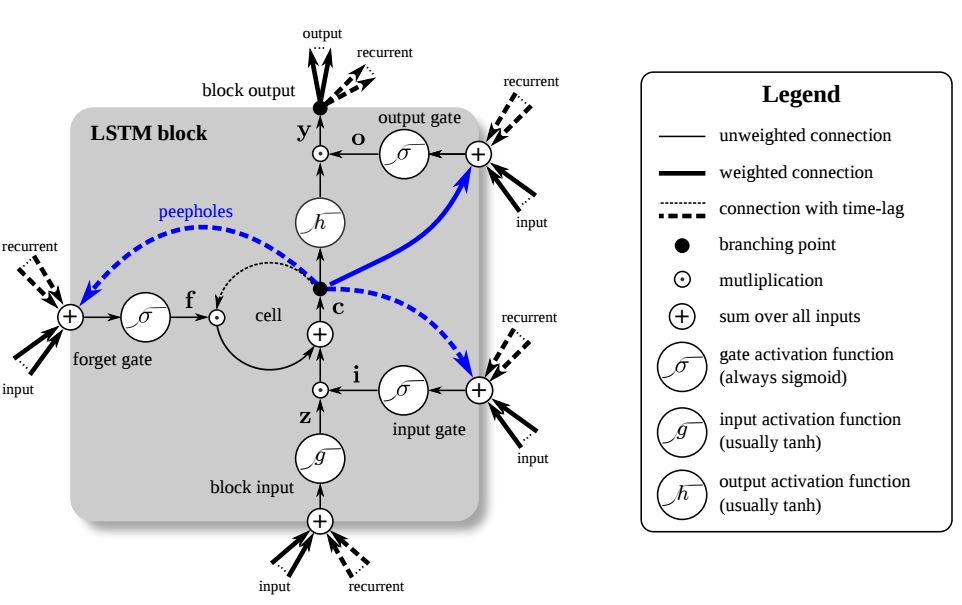
直到1997年,Jürgen和Hochreiter共同提出了著名的LSTM,在该理论的基础上实现了进一步的扩展。
LSTM的核心单元是权重为1.0的循环残差连接,也就是恒定误差轮盘(CECs),这一机制保证了误差可在数百乃至数千时间步中保持不衰减,使LSTM能有效捕捉输入与输出之间的长时间滞后,对语音、语言等任务至关重要。
另外这篇LSTM论文也是20世纪引用次数最多的人工智能论文。
1999年,LSTM演变出新的形态vanilla LSTM,在原来的基础上加入了初始值为1.0的遗忘门,使其具备可控的残差连接,既能保持长时依赖,又能在需要时重置记忆。
虽然这样做会重新引入一定的梯度消失,不过整体仍然处于可控状态。
到2005年,通过时间反向传播 (BPTT)算法,LSTM可以展开为深度前馈神经网络 (FNN),让每个输入序列的时间步都对应一个虚拟层,从而大幅增加了网络深度,可以处理更长时间滞后。 而无论是循环还是前馈,残差连接始终依赖权重固定为1.0。
接下来就是众所周知的2015年,首先在同年5月,需要优先提及Highway网络的贡献。

此前,基于反向传播的前馈神经网络的深度有限,只有20到30层,直到Highway网络的出现,才首次成功训练出上百层的深度前馈网络,比过去要深10倍以上。
其核心是将LSTM的门控残差思想从循环神经网络引入前馈网络,每层输出为g(x)x+t(x)h(x),其中x是来自前一层的数据,g、t、h表示带实值的非线性可微函数。
关键的残差部分g(x)x初始化为1.0,让Highway网络既能保持类似ResNet的纯残差连接,又能根据任务需要,以依赖上下文的方式自适应调整残差流,从而大幅提升深度可训练性。
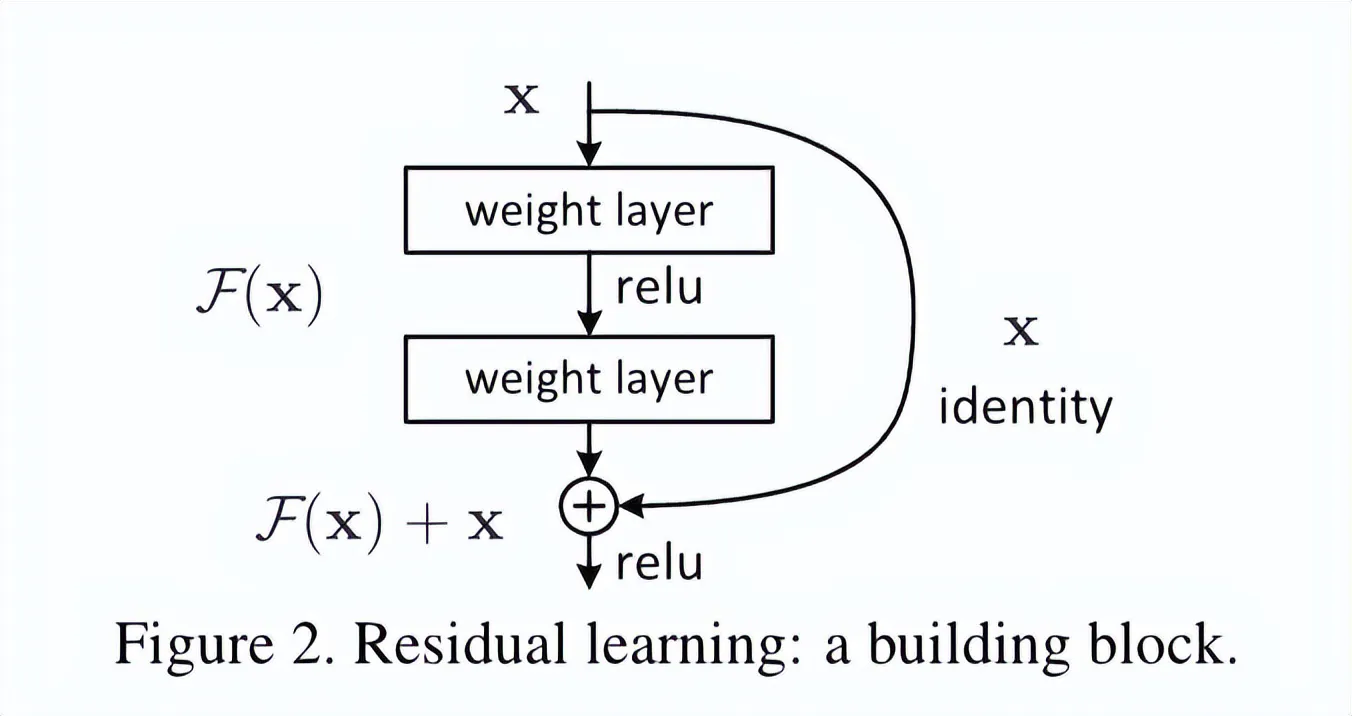
最后再到12月,ResNet在ImageNet竞赛中大获成功,彻底将残差学习带入大众视线。
ResNet在残差部分设计上,与展开的LSTM以及初始化的Highway网络相似,如果将Highway网络的门恒定设置为1.0,就可以得到纯残差网络ResNet,而它们本质上都是1997年的LSTM前馈变体。
ResNet的残差连接允许误差在深层网络中稳定传播,使网络能够训练数百层,但Jürgen也指出,ResNet论文中并没有明确说明它实际上就是开部门控的Highway网络,二者之间存在相似的标准残差连接。
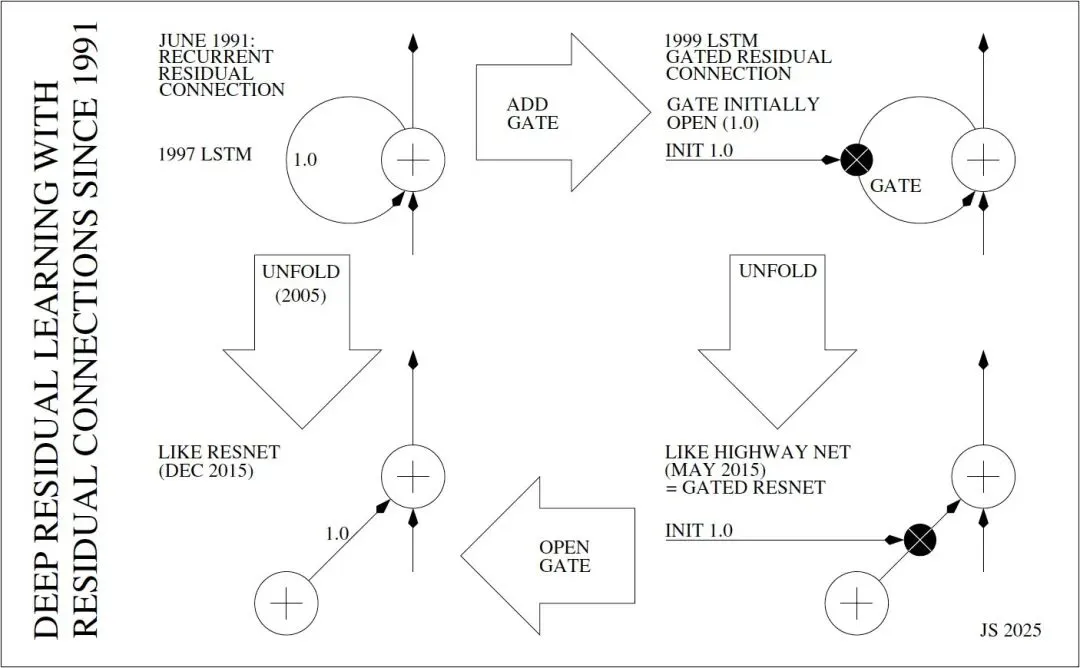
总结就是,LSTM与Highway网络分别奠定了循环和前馈网络的深度训练基础,ResNet则将这一原理成功应用于前馈网络,延续了自1991年Hochreiter首创的残差思想。
不过,这种说法目前仅代表Jürgen Schmidhuber的个人观点。(叠甲doge)
因为这已经不是他第一次对著名神经网络的起源提出质疑。
早在2021年,他就公开表示,LSTM、ResNet、AlexNet、VGG Net、GAN以及Transformer,都是受到了他实验室成果的启发。

例如他认为AlexNet和VGG Net采用了他们的DanNet;GAN是对他在1990年提出的Adversarial Curiosity原则的应用;Transformer的变体,即线性Transformer,是对他提出的快速权重存储系统的延伸。
但除了无可争议的LSTM归属,其他几项至今都没有得到普遍认可。
甚至衍生出这样一种说法:“Schmidhuber is all you need.”
参考链接: [1]https://x.com/SchmidhuberAI/status/1972300268550369631 [2]https://people.idsia.ch/~juergen/who-invented-residual-neural-networks.html [3]https://mp.weixin.qq.com/s/XkGs9rsSlI4D6oNv52pfOw