 Transformer 架构中的注意力机制是根据内容(what)和序列中的位置(where)将键(key)与查询(query)进行匹配。
Transformer 架构中的注意力机制是根据内容(what)和序列中的位置(where)将键(key)与查询(query)进行匹配。
而在近期 LSTM 之父 Jürgen Schmidhuber 的 USI & SUPSI 瑞士 AI 实验室团队的一项新研究中,分析表明,当前流行的旋转位置嵌入(RoPE)方法中的 what 与 where 是纠缠在一起的。这种纠缠会损害模型性能,特别是当决策需要对这两个因素进行独立匹配时。
基于这一观察,他们提出了新的方案:极坐标位置嵌入(Polar Coordinate Position Embedding ),简称 PoPE。

该团队表示,PoPE 消除了内容与位置的混淆,使得其在需要仅通过位置或仅通过内容进行索引的诊断任务上表现远优于 RoPE。

论文标题:Decoupling the "What" and "Where" With Polar Coordinate Positional Embeddings
论文地址:https://arxiv.org/abs/2509.10534
该论文的一作为 Anand Gopalakrishnan,目前正在哈佛大学从事博士后研究,曾是 Jürgen Schmidhuber 的博士生。参与者中还有 OpenAI 的研究科学家 Róbert Csordás,以及科罗拉多大学计算机科学系教授 Michael C. Mozer(目前已加入谷歌 DeepMind)。
RoPE 的问题
在许多前沿模型中,为了将位置信息纳入进来,RoPE 是首选方法,包括 Llama 3、DeepSeek-v3、Gemma 3 和 Qwen3。它会为每个查询-键对生成注意力分数,该分数基于它们的匹配程度及其在输入序列中的相对位置。
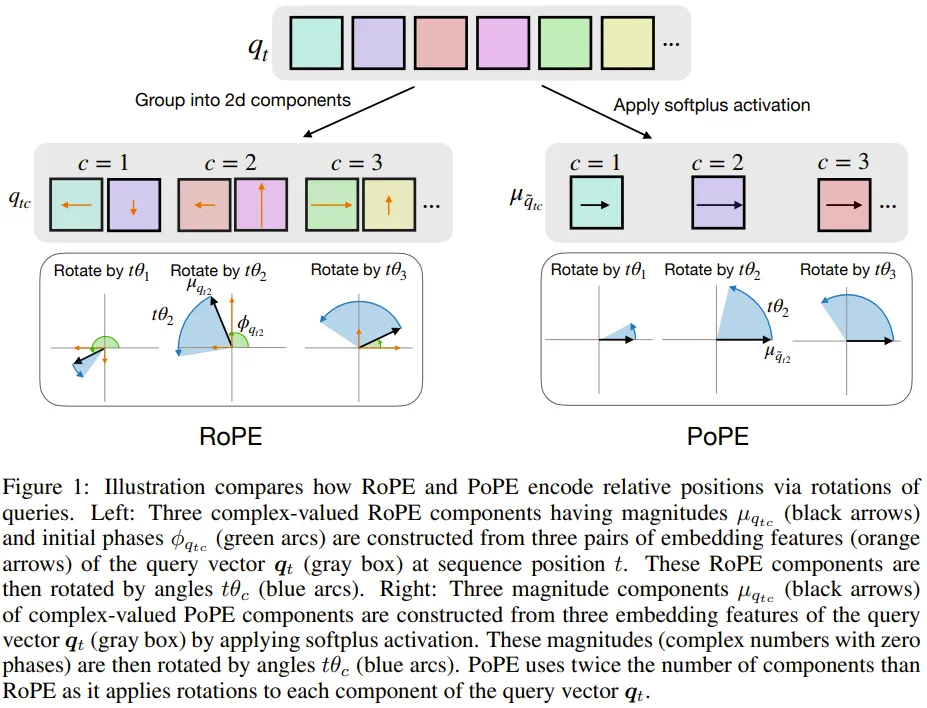
为了更好地理解 RoPE,这里以特定层中的特定注意力头进行说明。该注意力头的作用是执行位置 t 的查询 q_t 与位置 s 的键 k_s 之间的匹配。键和查询是 d 维向量,被划分为 d/2 个二维分量。
这里用 q_tc 和 k_sc 分别表示查询和键的分量 c∈{1,...,d/2}。RoPE 首先在 2D 平面中将每个分量 c 旋转一个与位置成正比的角度。如果 R (Φ) 是执行角度 Φ 旋转的 2×2 矩阵,则旋转后的查询和键分别为 R (tθ_c) q_tc 和 R (sθ_c) k_sc,其中 θ_c 是分量特定的基波波长(base wavelength):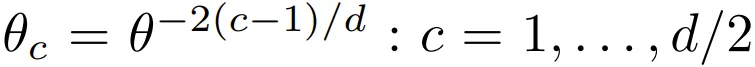 。下图展示了查询(或键)分量的构成及其在二维空间中的旋转方式。
。下图展示了查询(或键)分量的构成及其在二维空间中的旋转方式。
对应的键和查询分量通过点积匹配并求和以获得注意力分数:
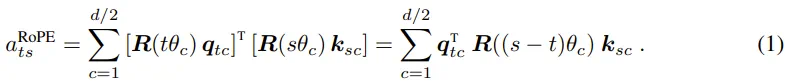
将分量对齐的旋转仅取决于键和查询的相对位置,而不取决于它们的绝对位置。
如果将键和查询分量从笛卡尔坐标重新表示为极坐标:
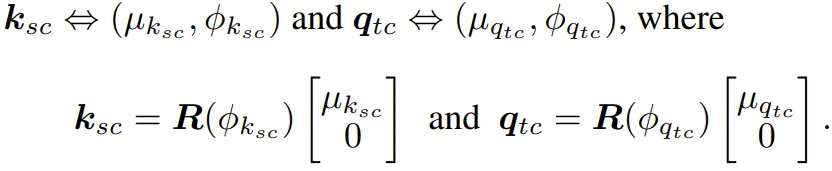
由此,注意力分数可写为:
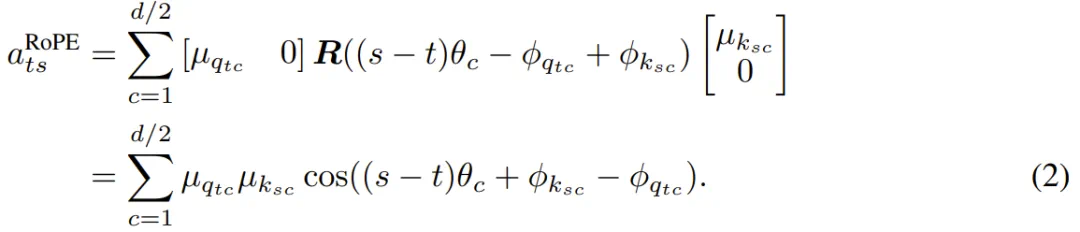
这清楚地表明,嵌入的每个双元素分量都被转换为单个幅值,并且通过 Φ_{q_tc} 和 Φ_{k_sc} 引入了对产生最大响应的相对位置(相位)的调整。因此,键和查询都混淆了关于特征存在与否的信息(what)和相对位置(where)。
该团队的假设是,通过解耦这两类不同的信息,特别是通过消除交互项 ,可以提高模型性能。
解决方案:PoPE
在 RoPE 中,该团队将键和查询的 d/2 个分量解释为复数。而在该团队提出的方法中,该团队利用了极坐标表示的另一种形式,称之为极坐标位置嵌入,即 PoPE。
在 PoPE 中,该团队将键和查询转换为相应的 d 元素复向量 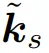 和
和 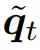 。每个元素 c 的幅值是对原始实值键或查询对应元素的重新缩放:
。每个元素 c 的幅值是对原始实值键或查询对应元素的重新缩放:
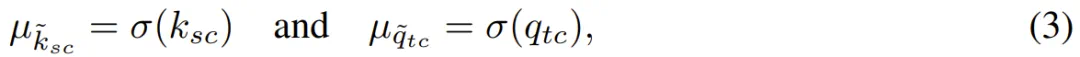
其中 σ(x)=ln (1+e^x) 表示 softplus 激活函数,确保幅值非负。相位仅取决于位置:

PoPE 的注意力分数定义为:
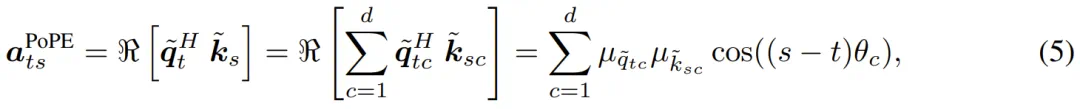
与 RoPE 相比,PoPE:
在单个元素而非元素对上进行索引,将频率数量从 d/2 增加到 d;
消除了导致键和查询影响相位的交互项。
此外,还可以引入一个可学习但固定的偏置项 :
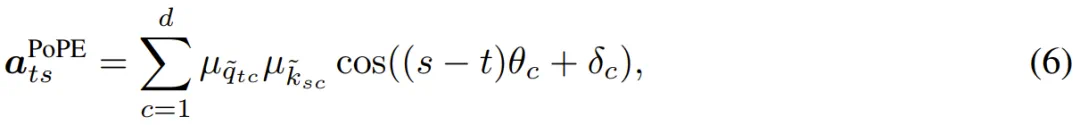
其中 δ_c 是为每个频率调整最佳相对偏移的可学习偏置。
该团队使用 Triton 实现了 PoPE。
通过修改内核,在不显式实例化复杂矩阵的情况下计算点积的实部。该团队的定制 Flash Attention 相比标准版仅需额外一次乘法。该团队表示,虽然目前的通用变体内存开销较大,但可以通过在内核内部执行旋转来优化。
那么,表现如何呢?
该团队将 PoPE 与 RoPE 在两个超参数完全相同的 Transformer 模型上进行比较。
间接索引(Indirect Indexing)
该任务要求在变长源字符串中识别目标字符,目标字符定义为距离指定源字符一定的相对偏移量。

RoPE 在此任务中表现挣扎,平均准确率仅为 11.16%。PoPE 则几乎完美地解决了任务,平均准确率达到 94.82%。这表明 RoPE 难以分离内容和位置信息,而 PoPE 通过解耦实现了高效学习。
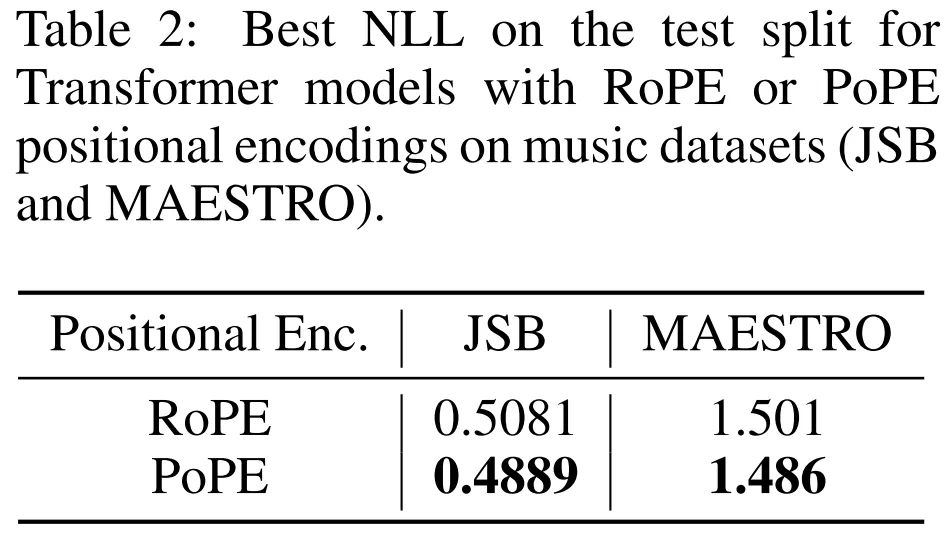
音乐与基因组序列建模
在 JSB 和 MAESTRO 符号音乐数据集上,PoPE 均实现了比 RoPE 更低的负对数似然(NLL)。
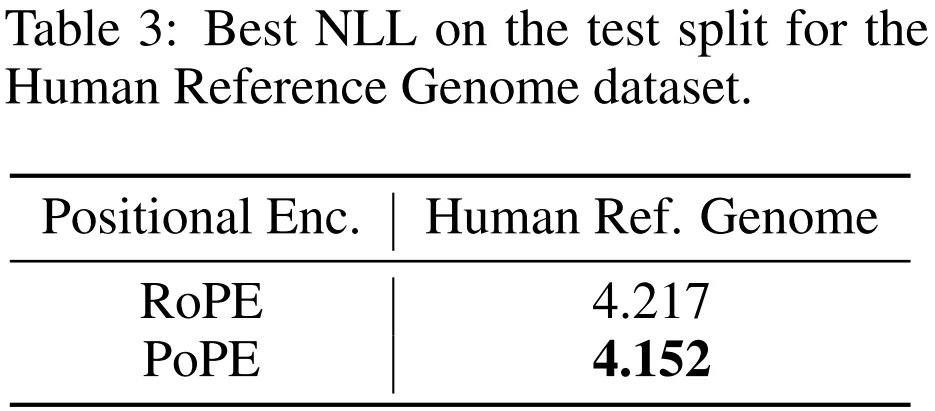
在人类参考基因组数据集上,使用 PoPE 的模型 NLL(4.152)显著低于 RoPE 基线(4.217)。
语言建模
在 OpenWebText 数据集上,该团队测试了三种规模的模型(124M、253M、774M)。
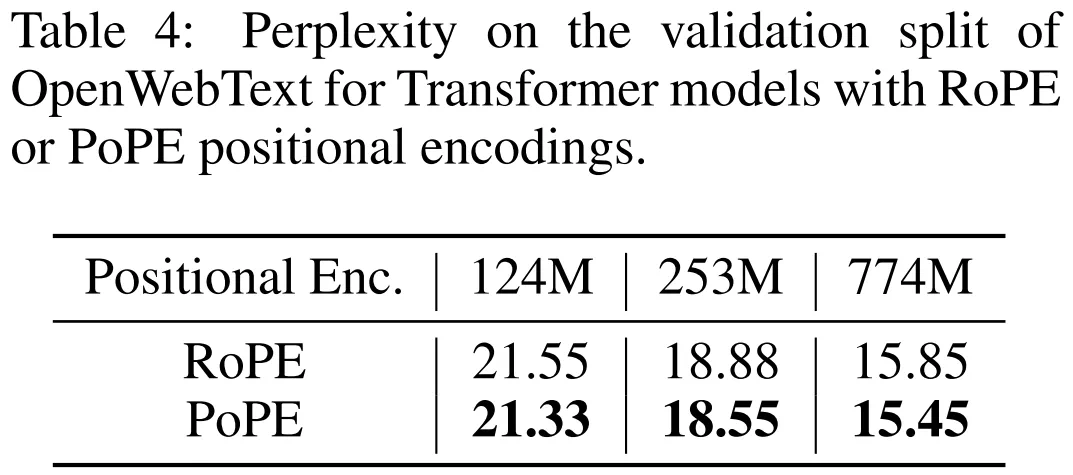
结果来看 ,在所有规模下,PoPE 的困惑度均始终低于 RoPE。
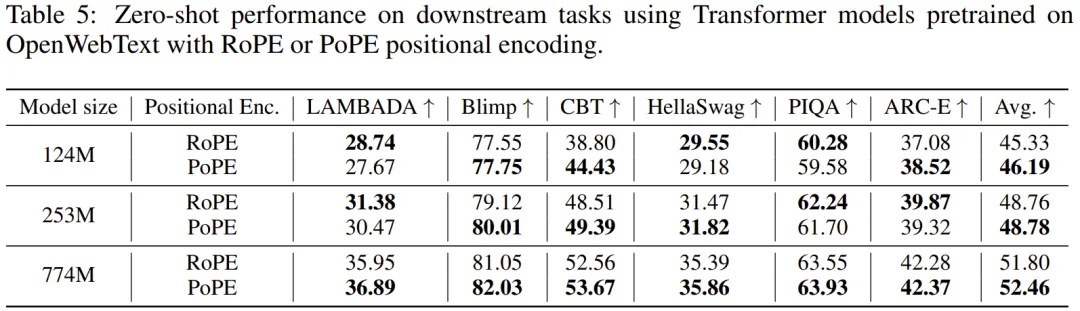
而在 LAMBADA、CBT、HellaSwag 等六项下游任务的零样本评估中,PoPE 在所有模型规模下的平均准确率均高于 RoPE。
测试时长度外推
该团队在 1024 个 token 上训练模型,并在长达 10240 个 token 的序列上评估。
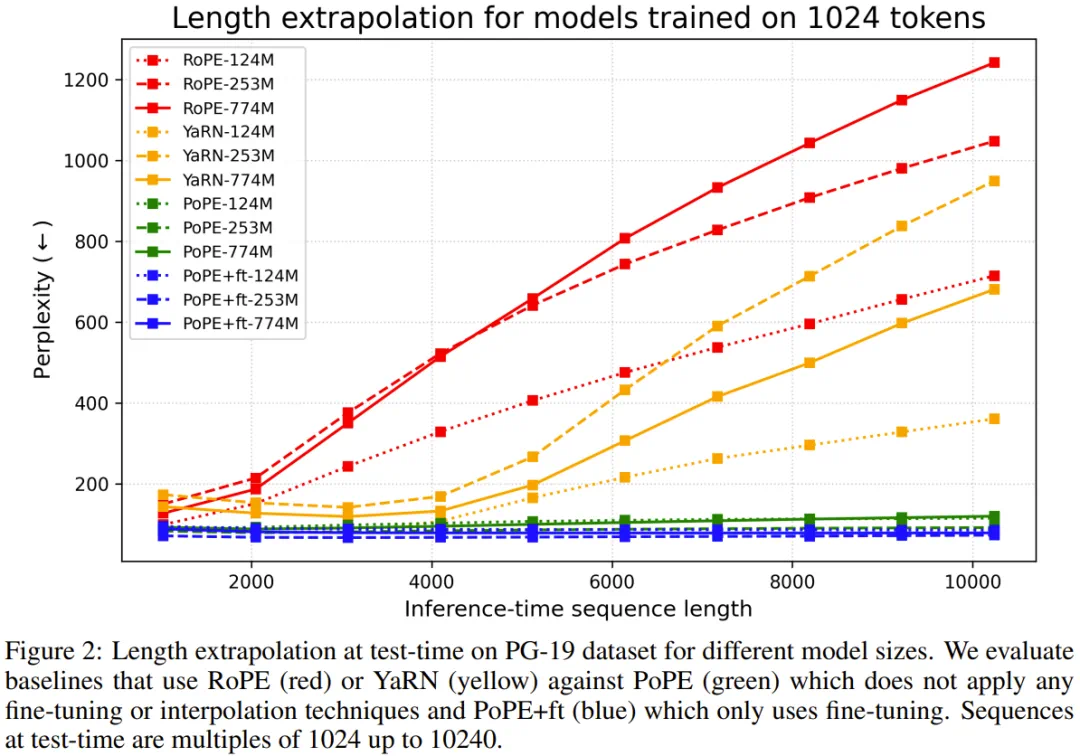
RoPE 的性能在长序列上显著下降。YaRN 在超过其微调长度后也会失效。
可以看到,PoPE 优势是在无需任何微调或插值的情况下,显示出强大的开箱即用外推能力,甚至优于专门的基线模型 YaRN。
PoPE 的稳定性也不错: RoPE 的外推性能随模型规模增加而恶化,而 PoPE 则保持大体稳定。
参考链接
https://x.com/agopal42/status/2003900824909746344


