
大家好,我是肆〇柒。在 AI 领域,大型语言模型(LLM)正以前所未有的速度改变着我们处理信息和解决问题的方式。然而,在当下落地 AI 应用时,一个关键问题逐渐浮出水面:LLM 是否能够真正理解并整合外部反馈,从而实现自我改进并达到其性能的极限?
此刻,可以想象一下,一个学生在考试后收到老师的详细批改意见。如果这个学生能够完全吸收并应用这些建议,他的成绩将会逐步提高,最终接近满分。对于 LLM 来说,外部反馈就像是老师给出的批改意见,而模型的自我改进能力则决定了它能否像理想中的学生一样不断进步。然而,一系列研究表明,尽管 LLM 能够在一定程度上利用外部反馈提升性能,但它们在整合反馈方面似乎存在某种根本性的障碍。这种现象,我们称之为“FEEDBACK FRICTION”(反馈阻力),正是本文的核心议题。这是来自约翰·霍普金斯大学(Johns Hopkins University)的研究论文《FEEDBACK FRICTION: LLMs Struggle to Fully Incorporate External Feedback》。
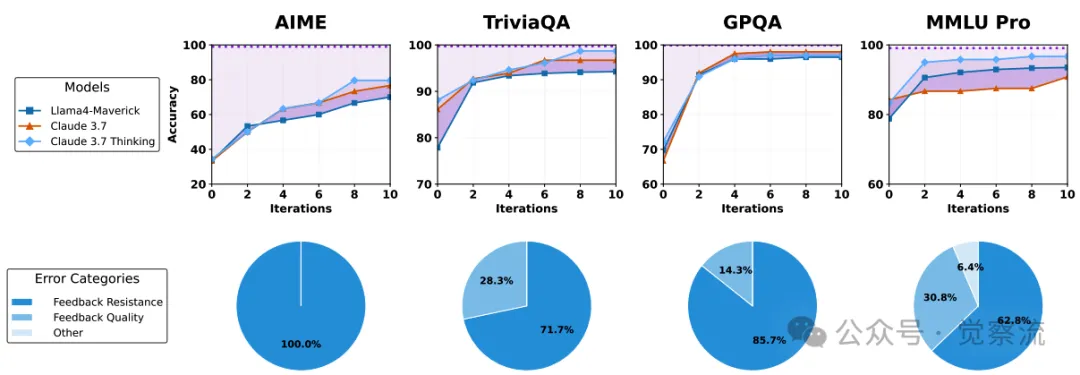
上图:当反复暴露于一个能够获取标准答案的反馈模型(GPT-4.1 mini)反馈时,各种解题模型的准确率。水平虚线代表模型在成功整合所有反馈的情况下理论上能够达到的目标准确率。尽管接收到了高质量的反馈,解题模型的准确率始终低于其目标准确率。下图:在多次修正尝试后,最强解题模型(Claude 3.7 思考)仍未解出的问题的分类。大多数持续存在的错误是由于反馈抗性,而非反馈质量问题
从上图可以看到,即使在高质量反馈的支持下,求解模型的准确率在多次迭代后仍然低于理论目标准确率,且反馈抗性是导致错误持续存在的主要原因。
实验设计与方法
实验框架构建
在探究大型语言模型(LLM)反馈整合困境的研究中,实验框架的构建至关重要。研究者们精心设计了一个受控的实验环境,以模拟理想条件下的反馈整合过程。这个环境的核心是一个迭代自我改进循环(iterative self-improvement loop),它包括以下几个关键组件:
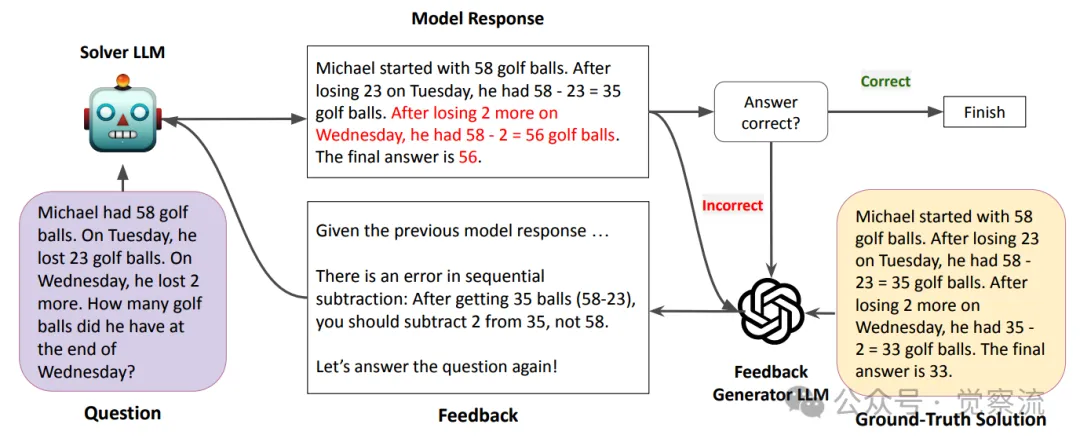
迭代自我改进循环。该过程包括:(1) 求解器模型生成答案,(2) 反馈模型针对错误回答和真实正确答案生成反馈,以及(3) 求解器根据该反馈再次尝试。此循环会重复进行,最多进行10次迭代,或者直到生成正确答案为止
如上图所示,迭代自我改进循环涉及求解模型生成答案、反馈模型根据错误回答和正确答案生成反馈,以及求解模型根据反馈再次尝试,这一过程最多重复 10 次或直到产生正确答案。
求解模型与反馈生成模型的分工与协作
- 求解模型(Solver Model) :其主要任务是尝试解决给定的问题。在实验中,求解模型在每次迭代中生成初始答案,并在后续迭代中基于反馈生成模型提供的反馈进行改进。
- 反馈生成模型(Feedback Generator Model) :当求解模型的答案错误时,反馈生成模型根据正确答案和求解模型的错误输出生成针对性的反馈。这个反馈是为了帮助求解模型识别错误并找到正确的解决方案。
反馈机制的具体设计和特点
反馈机制分为三种类型,每种类型都期望以不同的方式帮助模型整合反馈:
1. 二元正确性反馈(Binary Correctness Feedback,F1) :这种反馈机制仅提供答案正确与否的信息。例如,反馈可能是一个简单的“答案错误”信号。尽管这种反馈的信息量有限,但它为模型提供了一个基本的纠正方向。
2. 自生成反思反馈(Self-Generated Reflective Feedback,F2) :在这种机制下,求解模型自身根据正确答案和已有解答步骤分析错误。这要求模型具备一定的自我反思能力,能够识别自身解答中的问题并生成改进策略。
3. 强模型反思反馈(Strong-Model Reflective Feedback,F3) :这是最复杂的反馈机制,由更强大的外部模型生成反馈。该反馈不仅指出错误,还提供详细的错误分析和改进建议,类似于一个经验丰富的导师给予的详细指导。
任务与数据集选择
研究涵盖了九个不同的任务,这些任务的选择确保了研究的全面性,能够从多个角度评估反馈阻力现象。具体任务及其特点如下:
数学推理任务
- AIME 2024 :美国邀请赛数学考试(AIME)是针对高中生的数学竞赛,题目难度较高,要求学生具备扎实的数学基础和较强的解题能力。该任务测试模型在解决复杂数学问题方面的能力。
- MATH-500 :包含 500 个具有挑战性的数学问题,涵盖多个数学领域,用于评估模型在不同数学主题上的推理能力。
知识问答任务
- TriviaQA :一个大规模的 distant supervision 阅读理解数据集,包含超过 650,000 个问题 - 答案 - 证据三元组。该数据集的问题来源广泛,涵盖各种主题,用于测试模型在广泛知识领域的理解和回答能力。
- PopQA :包含 95,000 个问题 - 答案对,这些问题由 trivia 爱好者独立编写,并收集了平均每个问题六个支持证据文档。该数据集的问题具有较高的复杂性和多样性,对模型的知识检索和整合能力提出了挑战。
科学推理任务
- GPQA :一个研究生级别的谷歌证明科学问答数据集,用于评估模型在科学推理方面的能力。该任务要求模型能够理解和回答涉及科学概念和原理的问题。
多领域评估任务
- MMLU :大规模多任务语言理解基准测试,包含多个学科的任务,用于评估模型在不同领域的语言理解和推理能力。
- MMLU Pro :MMLU 的增强版本,提供了更具挑战性的任务,进一步测试模型在多领域知识整合方面的能力。
合成数字乘法任务
- 标准 5 位数乘法 :设计用于测试模型在常规算术运算中的系统性推理能力。通过分解复杂计算步骤,该任务评估模型是否能准确执行多步算术操作。
- 十六进制 5 位数乘法 :进一步挑战模型在非标准数系统中的推理能力。该任务要求模型严格按照十六进制规则进行计算,评估其在不同进制下的算术推理能力。
数据集的采样方法和评估指标
为了确保实验结果的可靠性和可重复性,研究者们采用了统一的采样策略。对于 PopQA,研究者们基于实体流行度进行采样,以保证评估的公平性和代表性。对于其他任务,研究者们从完整数据集中随机抽取 10% 的数据进行评估,以减少计算成本并提高实验效率。在评估指标方面,研究者们采用了准确率(Accuracy)作为主要指标,通过比较模型输出与正确答案来计算模型在每个任务上的性能。
模型配置与参数设置
实验中使用了一系列先进的求解模型,包括 LLaMA-3.3-70B-Instruct、Llama-4-Scout、Llama-4-Maverick、Claude 3.7 及其扩展思考版本。这些模型代表了当前 LLM 领域的前沿水平。反馈模型则采用了 GPT-4.1 mini,因其卓越的生成能力和对反馈的精准把握而被选中。
在推理过程中,研究者们对温度参数、采样方法等进行了细致调整:
- 温度参数 :温度参数控制模型采样时的随机性。对于 Claude 模型,使用温度 0 可确保模型输出的确定性。这是因为温度 0 意味着模型在生成答案时会选择概率最高的下一个词,从而保证输出的一致性和稳定性。而对于 Claude 3.7 扩展思考版本,则采用温度 1,这种设置允许模型在生成过程中引入更多随机性,模拟更灵活的思考过程,有助于模型跳出固定的思维模式,探索更多的解答可能性。
- 采样方法 :研究者们探索了多种采样策略以缓解反馈阻力。例如,渐进式温度增加(progressive temperature increases)通过逐步提高采样温度来增加模型输出的多样性。结合温度增加与拒绝采样(rejection sampling)的方法表现更好。这种策略明确要求模型在生成答案时避免重复之前的错误尝试。具体来说,在每次迭代中,模型生成 25 个答案,然后过滤掉之前出现过的错误答案。如果仍有剩余答案,则从中随机选择一个作为最终预测。
这些设置是为了平衡模型的探索性和稳定性,为实验提供最优化的条件。通过这种细致的模型配置与参数设置,研究者们能够在不同的任务和反馈机制下,准确评估模型的自我改进能力,并深入分析反馈阻力现象的本质。
实验结果
整体表现分析
实验结果揭示了一个令人不安的现象:无论采用哪种反馈机制,所有模型在多次迭代后性能均趋于平稳,但始终未能达到理论上的目标准确率(即假设模型完全整合了所有反馈时的预期性能)。例如,在 AIME 2024 任务中,尽管 Claude 3.7 Thinking 初始准确率高达 50%,但经过 10 次迭代后,其准确率仍比目标准确率低 15-25%。类似的情况也出现在 GPQA 任务中,模型性能比理论上限低 3-8%。这些结果表明,反馈阻力是 LLM 面临的一个普遍且根本性的挑战。
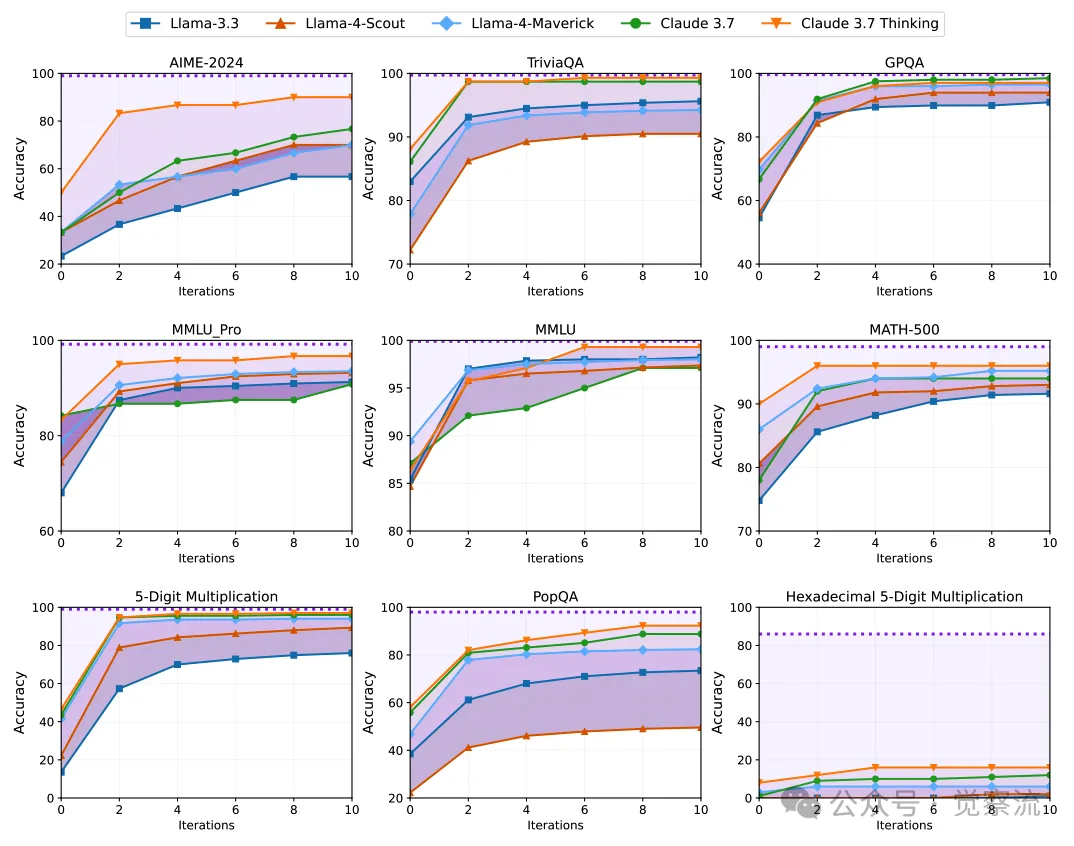
使用强模型反思反馈(F³)对处于前沿的模型,在九项不同任务中的表现进行了测试。这些模型在多次尝试中获得了反馈,反馈内容既包括最终答案,也包括完整的解决方案(如果可用)。虚线表示模型如果完全吸收所有反馈理论上能够达到的目标准确率。结果显示,尽管有强大的反馈,模型在所有任务中都始终无法达到其目标准确率,表现趋于平稳
不同反馈机制对比
反馈质量对模型自我改进能力的影响显而易见。
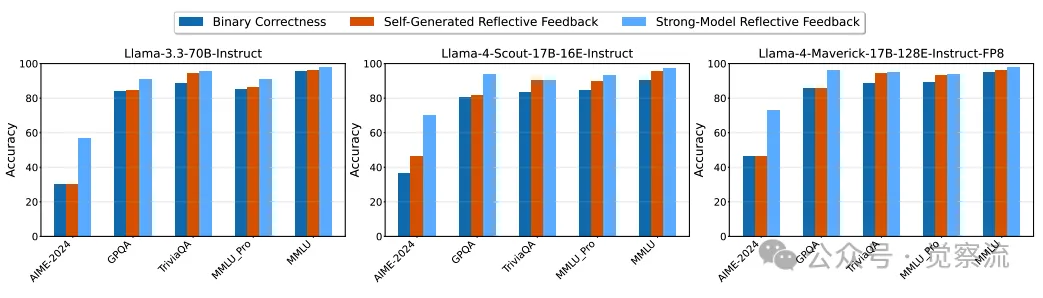
使用不同反馈机制在基准数据集上对Llama-3.3、Llama-4-Scout和Llama-4-Maverick进行性能比较。随着反馈质量从二元正确性反馈(F1)提高到强模型反思性反馈(F3),模型性能逐步提升
上图比较了三种反馈机制下模型在不同任务上的性能差异。结果显示,随着反馈质量的提升(从 F1 到 F3),模型性能显著提高。例如,在 AIME 任务中,使用强模型反思反馈(F3)的 Llama-4-Maverick 准确率比仅使用二元正确性反馈(F1)高出 26.7%。然而,即便在高质量反馈的支持下,模型仍未摆脱反馈阻力的限制。这表明,除了反馈质量外,还存在其他因素制约着 LLM 的自我改进能力。
具体任务与模型的深入剖析
在标准 5 位数乘法任务中,Claude 系列模型表现出色,经过初始改进后准确率接近完美,远超 Llama 模型。
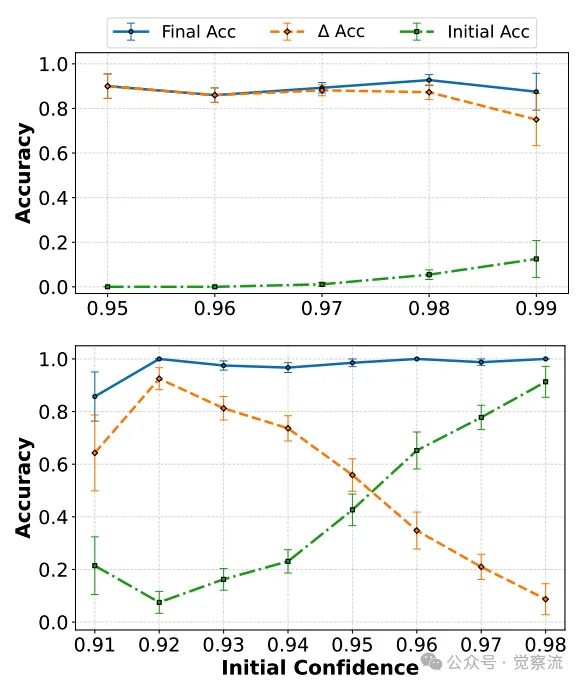
Llama4 Scout(上)和Llama4 Maverick(下)在五位数乘法任务上的准确率
但在更具挑战性的十六进制 5 位数乘法任务中,所有模型都陷入了困境。即使经过 10 次迭代,没有任何模型的准确率超过 20%。这一现象揭示了 LLM 在处理非常规算术系统时的严重局限性。
对于 Claude 3.7 Thinking 而言,在 AIME 任务中展现出了高初始准确率,但面对复杂问题时,其性能提升空间依然有限。
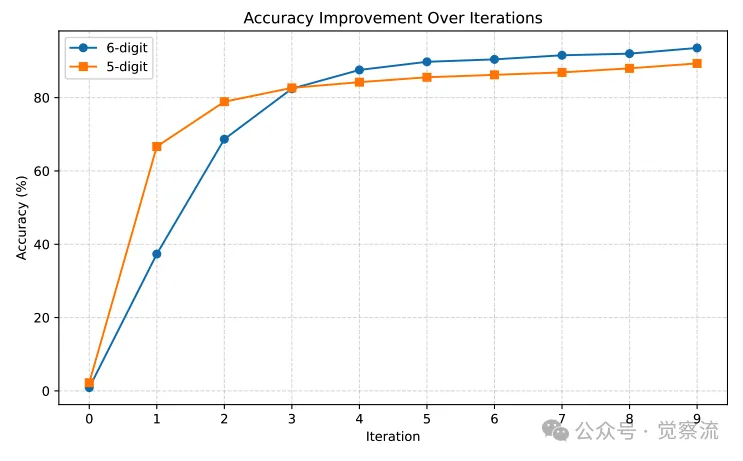
GPT-4.1 mini 作为反馈模型时,5位数乘法和6位数乘法改进效果的比较
这表明,即使是具备扩展思考能力的模型,在整合反馈方面也存在明显的瓶颈。
模型性能的长期趋势与迭代稳定性
进一步分析模型在不同任务上的长期表现趋势,研究者们观察到模型的准确率在多次迭代后趋于稳定,形成一个性能平台期。这表明,模型在经过一定次数的反馈循环后,其内部参数调整和知识整合能力达到一个相对平衡的状态,难以通过进一步的反馈实现显著提升。例如,在 TriviaQA 任务中,Llama-4-Maverick 模型在初始几轮迭代中准确率提升较快,但随后逐渐放缓,最终在大约 20 次迭代后稳定在某个固定值附近,不再有明显的上升趋势。
这种迭代稳定性可能与模型的架构特性、训练数据的覆盖范围以及反馈机制的设计等因素密切相关。研究还发现,当模型在特定任务上反复接受相似类型的反馈时,其参数更新的幅度逐渐减小,表明模型对这类反馈的敏感度降低。这可能是由于模型在早期迭代中已经学习到了反馈所蕴含的主要模式,后续的反馈更多地是对已有知识的重复强化,而非新的知识或技能的引入。
同时,模型在不同任务上的迭代稳定性也存在显著差异。在一些结构化较强、答案明确的任务(如数学推理任务)中,模型的准确率平台期相对较高;而在开放性较强、答案多样化的任务(如知识问答任务)中,模型的准确率平台期则较低。这可能是因为开放性任务的答案空间更为广阔,模型在整合反馈时需要处理更多的不确定性和模糊性,导致其难以达到较高的稳定性能。
分析与讨论
错误类型分类与主导因素
通过对模型在多次反馈迭代后仍无法纠正错误的案例进行人工检查,研究者们将错误分为三类:
1. 反馈抗性(Feedback Resistance) :模型未能准确整合清晰且准确的反馈。例如,在一个简单数学问题中,模型反复犯同样的计算错误,即使反馈明确指出了错误步骤。
2. 反馈质量问题(Feedback Quality) :生成的反馈本身存在错误、模糊或未能针对关键问题。这可能是由于反馈模型未能完全理解问题或求解模型的错误输出导致的。
3. 其他问题(Other) :包括问题本身的模糊性、答案格式不符合要求等情况。
经过自动标注和人工验证,研究发现反馈抗性是导致持续自我改进错误的主要类别。在多个任务中,反馈抗性占比高达 62.8%-100%。这表明,反馈阻力的核心挑战在于模型对纠正性反馈的整合能力,而非反馈质量或问题复杂性本身。
下表是不同任务中错误类型的分布情况(%)
数据集 | 求解模型 | 反馈抗性 | 反馈质量问题 | 其他 |
MMLU Pro | Claude 3.7 | 64.6 | 28.0 | 7.4 |
MMLU Pro | Claude 3.7 Thinking | 62.8 | 30.8 | 6.4 |
GPQA | Claude 3.7 | 100.0 | 0.0 | 0.0 |
GPQA | Claude 3.7 Thinking | 85.7 | 14.3 | 0.0 |
TriviaQA | Claude 3.7 | 72.4 | 25.0 | 2.6 |
TriviaQA | Claude 3.7 Thinking | 71.7 | 28.3 | 0.0 |
AIME 2024 | Claude 3.7 | 100.0 | 0.0 | 0.0 |
AIME 2024 | Claude 3.7 Thinking | 100.0 | 0.0 | 0.0 |
采样策略的缓解效果评估及深度分析
为了缓解反馈阻力,研究者们尝试了多种采样策略。其中,渐进式温度增加(progressive temperature increases)是一种简单的方法,通过逐步提高采样温度来增加模型输出的多样性。然而,单独使用这种方法效果有限。例如,在 Llama-4-Scout 和 Llama-4-Maverick 模型上,尽管温度增加使输出更加多样化,但额外的探索往往未能收敛到正确答案,可能是由于响应空间过于庞大。
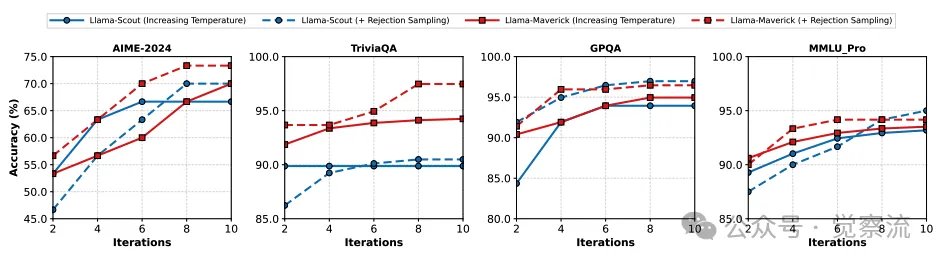
使用逐步增加的温度和拒绝采样方法在Llama-4-Scout和Llama-4-Maverick中的结果表明,拒绝采样可以在多项选择和非多项选择任务中,为基于温度的采样提供额外的改进
结合温度增加与拒绝采样(rejection sampling)的方法表现更好。这一策略明确要求模型在生成答案时避免重复之前的错误尝试。具体来说,在每次迭代中,模型生成 25 个答案,然后过滤掉之前出现过的错误答案。如果仍有剩余答案,则从中随机选择一个作为最终预测。如上图,这种组合策略在多项选择和非多项选择任务上均带来了显著的性能提升。然而,即便采用了这些策略,模型准确率仍未达到目标准确率。这表明,采样策略虽然有助于缓解反馈阻力,但无法完全消除这一问题。
反馈阻力的潜在原因探究与模型内部因素关联
研究者们对可能导致反馈阻力的多种因素进行了深入调查:
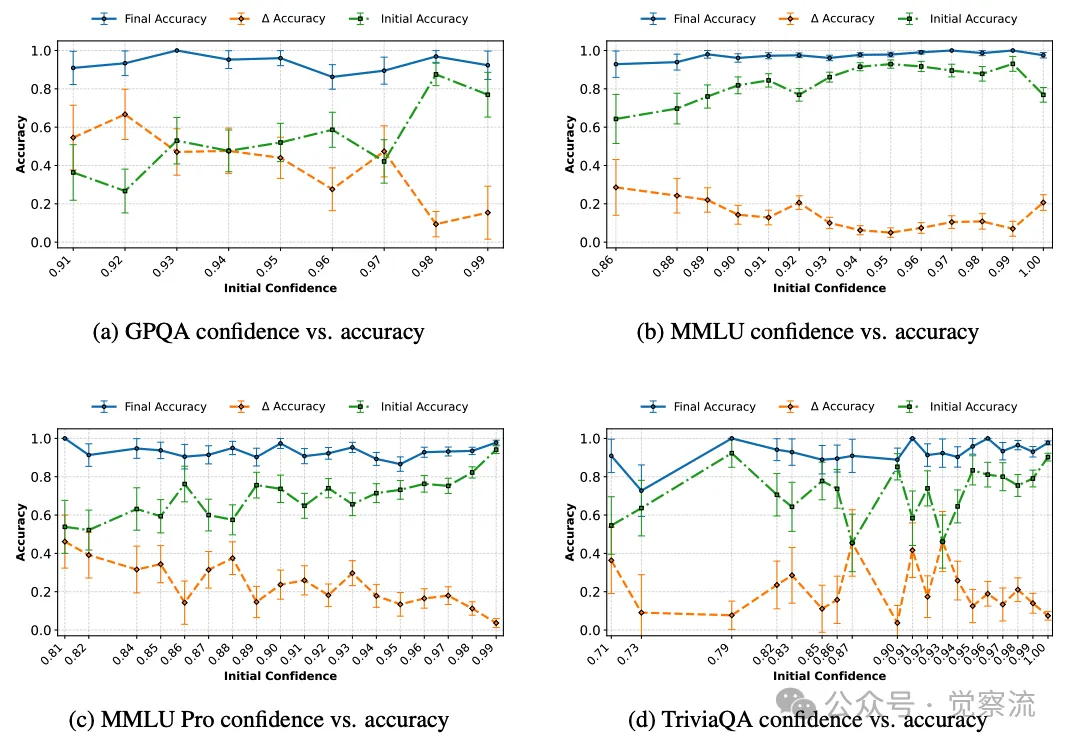
不同数据集中使用 GPT-4.1 mini 作为反馈模型以及使用 Llama-4-Scout 作为解决模型时的置信度与准确性对比
1. 模型置信度 :高置信度模型是否更难接受反馈?通过对 5 位数乘法任务的分析发现,初始置信度与最终准确率之间并无显著相关性。高置信度答案既可能正确也可能错误,且模型在自我改进迭代中的提升幅度与初始置信度关系不大。
2. 数据熟悉度 :模型是否对熟悉的实体或主题更抗拒反馈?利用 PopQA 数据集中的实体流行度指标进行分析后发现,准确率的变化与实体流行度之间没有一致的模式。
3. 推理复杂度 :问题的复杂性是否与反馈阻力相关?通过比较 5 位数和 6 位数乘法任务的结果,研究发现复杂任务的提升空间更大,但简单问题的最终准确率往往更高。这表明,任务复杂性与反馈效果之间的关系并非线性,还受到其他因素的影响。
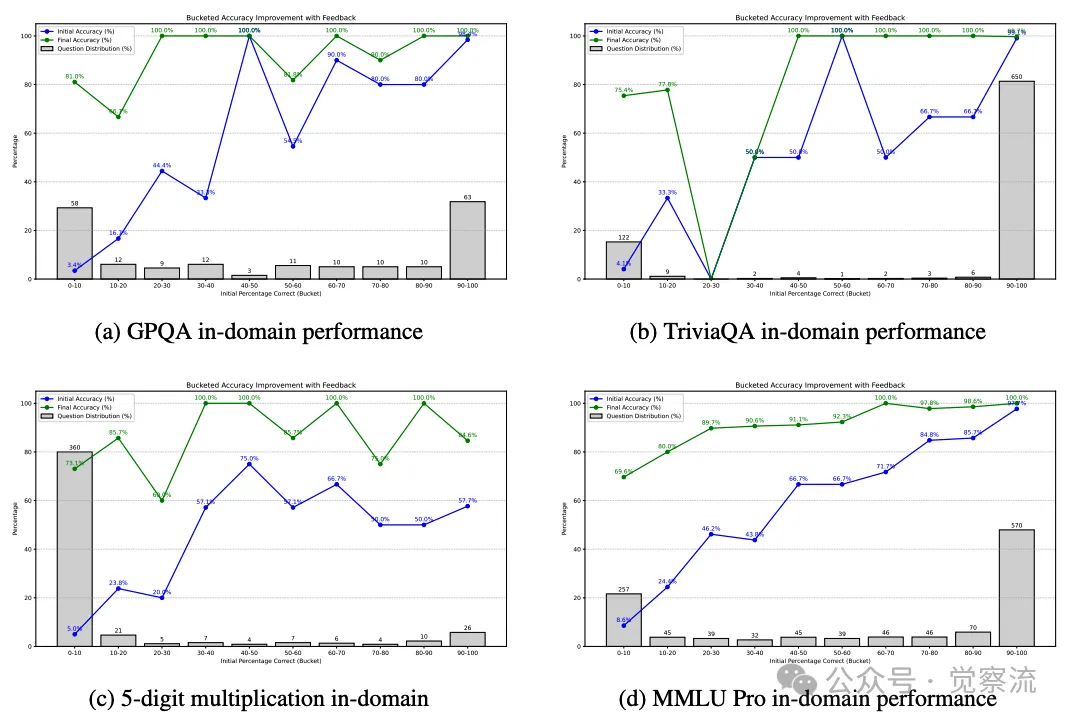
Llama-3.3 在四个基准任务中的领域内准确率
此外,研究还发现不同模型在相同问题上表现出的错误各不相同。例如,在 AIME 任务中,三个模型共有 35.7% 的共同错误,但在 GPQA 和 5 位数乘法任务中,这一比例分别降至 6.9% 和 0.7%。这表明,模型的失败往往是特异性的,而非集中在一组通用的难题上。这种现象进一步凸显了反馈阻力的复杂性,意味着不存在一种通用的解决方案能够适用于所有模型和任务。
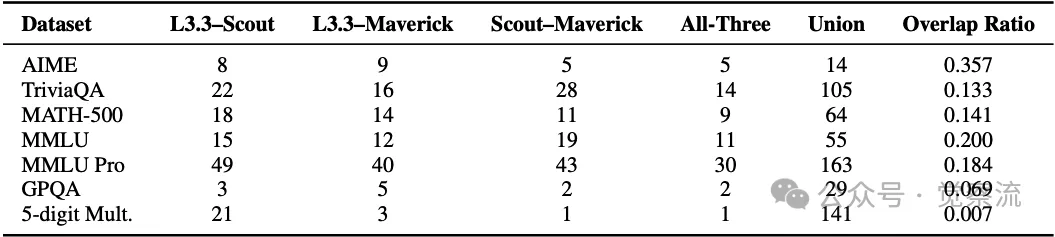 在Llama-3.3、Llama-4-Scout 和 Llama4-Maverick 这三种模型中,存在成对以及三者共同的失败案例。这些失败案例是在多个数据集上统计的。重叠率是通过计算所有三个模型都失败的问题数量除以所有不同失败案例的并集来得出的
在Llama-3.3、Llama-4-Scout 和 Llama4-Maverick 这三种模型中,存在成对以及三者共同的失败案例。这些失败案例是在多个数据集上统计的。重叠率是通过计算所有三个模型都失败的问题数量除以所有不同失败案例的并集来得出的
模型内部机制对反馈整合的影响
深入探究模型内部机制对反馈整合的影响,研究者们发现,模型的注意力分配模式在反馈整合过程中起着关键作用。在接收反馈时,模型需要将其注意力集中在反馈中关键的纠正性信息上,以便准确理解错误所在并进行相应的调整。然而,研究发现,LLM 在处理反馈时往往难以有效地分配注意力。例如,在一些复杂的数学推理任务中,模型可能会过度关注反馈中的某些局部信息,而忽略整体的解题思路调整建议。这种注意力分配的偏差导致模型无法全面理解反馈的意图,从而影响其整合效果。
此外,模型的内部知识表示方式也对反馈整合能力产生重要影响。LLM 通过大规模预训练学习到了丰富的知识,但这些知识以一种分布式、非结构化的形式存储在模型的参数中。当接收到反馈时,模型需要将其与内部知识进行匹配和整合,以形成新的知识表示。然而,由于模型内部知识的复杂性和模糊性,这一过程容易出现错误。例如,模型可能会错误地将反馈中的信息映射到不相关的知识区域,或者无法准确更新已有的错误知识,从而导致反馈整合的失败。
反馈阻力与模型泛化能力的关系
反馈阻力现象还与模型的泛化能力密切相关。在实验中,研究者们观察到,模型在训练数据分布内的任务上表现出相对较好的反馈整合能力,但在面对分布外的新型任务或问题时,反馈阻力问题更为突出。这表明,模型的反馈整合能力在一定程度上依赖于其对任务类型的熟悉程度和对相关知识的预先学习。
例如,在标准 5 位数乘法任务中,模型经过多次迭代后能够逐渐适应任务模式,准确率有所提升。然而,当任务转换为十六进制 5 位数乘法时,模型的准确率急剧下降,且难以通过反馈进行有效调整。这可能是因为十六进制乘法任务超出了模型在预训练和早期迭代中所接触的知识范围,模型缺乏对这类任务的有效知识表示和推理策略,从而导致其在整合反馈时面临更大的困难。
这种对训练数据分布的依赖性限制了模型在现实世界中的应用,因为在实际场景中,模型往往需要面对各种新颖、多变的任务和问题。如果模型无法有效克服反馈阻力,其在新环境中的适应能力和泛化性能将受到严重制约。
技术实现与工具
为了支持这项研究,约翰霍普金斯大学的研究团队开发了一个名为 Feedback-Friction 的 GitHub 项目(地址见参考资料)。该项目提供了一个统一的框架,用于评估 LLM 在多个推理领域中整合不同类型反馈的能力。
项目的核心组件包括:
1. openai_async_process.py :主实验运行脚本,负责驱动模型在不同数据集上的迭代生成和优化过程。
2. utils.py :包含核心工具和数据集处理功能,支持实验的顺利进行。
3. error_analysis.py :基于反馈的迭代改进系统,用于分析模型错误并生成改进策略。
4. oracle_beam_search.py :通过大规模采样评估理论最大性能,为实验结果提供参考上限。
5. digit_multiplication/ :专门处理数字乘法任务的模块,包括十进制和十六进制乘法的实现。
项目的安装和配置过程相对简单。首先,确保安装了 Python 3.9 或更高版本,以及 vLLM 0.8.3+ 库。然后,克隆项目仓库并安装依赖项:
复制git clone https://github.com/JHU-CLSP/Feedback-Friction.git cd Feedback-Friction pip install vllm==0.8.3 datasets pip install -r requirements.txt
如果需要使用强模型反馈(如 OpenAI 模型),还需设置 OpenAI API 密钥:
复制export OPENAI_API_KEY="your-api-key-here"
实验运行示例与反馈模式
项目支持四种反馈模式,每种模式均可通过特定的命令参数启用:
1. 二元反馈(Binary Feedback) :仅提供正确/错误信号。命令示例:
复制python openai_async_process.py \
--dataset gpqa \
--agent_model meta-llama/Llama-3.3-70B-Instruct \
--base_url http://c007 \
--ports 1233 \
--write_file gpqa_log.jsonl \
--iterations 102. 自生成反馈(Self-Generated Feedback) :模型自动生成反思反馈。命令示例:
复制python openai_async_process.py \
--dataset gpqa \
--agent_model meta-llama/Llama-3.3-70B-Instruct \
--base_url http://c007 \
--ports 1233 \
--write_file gpqa_log.jsonl \
--iterations 10 \
--use_feedback3. 过程级反馈(Process-Level Feedback) :包含详细的推理过程。命令示例:
复制python openai_async_process.py \
--dataset gpqa \
--agent_model meta-llama/Llama-3.3-70B-Instruct \
--base_url http://c007 \
--ports 1233 \
--write_file gpqa_log.jsonl \
--iterations 10 \
--use_feedback \
--use_process_feedback4. 强模型反馈(Strong-Model Feedback) :使用 OpenAI 模型生成高质量反馈。命令示例:
复制python openai_async_process.py \
--dataset gpqa \
--agent_model meta-llama/Llama-3.3-70B-Instruct \
--base_url http://c007 \
--ports 1233 \
--write_file gpqa_log.jsonl \
--iterations 10 \
--use_feedback \
--use_process_feedback \
--use_openai输出格式与结果解读
实验结果以 JSONL 格式保存,每行代表一个问题的完整交互历史。主要字段包括:
- question :原始问题及完整交互历史。
- normalized_answer :正确答案。
- normalized_prediction :模型预测结果。
- full_response :当前迭代的完整原始响应。
- feedback :生成的反馈(如果启用了反馈)。
- response_probs :每个标记的平均对数概率。
- is_correct :当前迭代是否正确。
- iteration :当前迭代次数(从 0 开始)。
数字乘法数据集的特殊设计与验证
项目中专门设计的十进制和十六进制数字乘法数据集在评估模型系统性算术推理能力方面发挥着重要作用。十进制乘法数据集基于分配律分解复杂计算,提供逐步提示以引导模型正确计算。十六进制乘法则进一步挑战模型在非标准数系统中的推理能力,要求模型严格按照十六进制规则进行计算。这些数据集通过自动验证与内置十六进制计算器的结果进行比对,确保反馈的正确性和一致性。
技术实现局限性与挑战
尽管 Feedback-Friction 项目提供了一个强大的实验框架,但在实际操作中仍面临一些局限性和挑战:
1. 计算资源需求 :处理大规模数据集和大型模型需要大量的计算资源。例如,运行 Claude 3.7 等 70B+ 参数模型需要配备多个高性能 GPU 的服务器。
2. 推理速度与迭代次数的平衡 :在有限的时间内完成多次迭代反馈,对模型推理速度提出了较高要求。研究者们需要在模型精度和推理速度之间找到最佳平衡点。
3. 模型架构兼容性 :不同 LLM 架构对反馈机制的适配性存在差异。某些模型可能在特定反馈模式下表现更好,而在其他模式下则表现不佳。这需要对反馈机制进行适当调整以适应不同模型架构。
针对这些问题,研究者们提出了多种优化策略,如采用分布式计算加速实验进程、对模型进行蒸馏以提高推理速度、以及对反馈机制进行定制化调整等。
洞察与前瞻:超越Feedback Friction的未来
“Feedback Friction”的研究为我们展示了大型语言模型(LLM)在整合外部反馈方面面临的严峻挑战,更迫使我们重新审视AI自我改进的本质。这项研究清楚地揭示了一个现实:即使在提供了高质量的外部反馈后,LLM 的性能在多次迭代后仍然趋于平稳,未能达到理论上的目标准确率。它清晰地表明,即使是当下最先进的LLM,也并非能像人类学生那样,轻易地从“老师的批改”中完全吸收并举一反三。这种“吸收不良”的现象,无论是归咎于模型对反馈的“抵抗”,还是反馈本身的“质量”问题,都指向了一个核心事实:LLM的认知模式与人类学习机制存在根本差异。我们不能简单地将人类学习的反馈循环套用到AI身上,而必须深入探索LLM处理信息、更新知识的独特方式。
这项研究的价值远不止于指出问题。它为我们构建更强大的、真正能够自我进化的AI系统具有指导意义。我们需要从多个维度攻克“反馈阻力”的难题。在模型架构层面,这可能意味着需要设计全新的记忆机制或注意力模块,让LLM能更有效地识别、储存和调用关键的纠正性信息,甚至能在内部建立一个“批判性思维”单元,主动审视并整合外部反馈。在反馈机制层面,与其寄希望于单一的“最优反馈”,不如探索更智能、自适应的反馈策略,例如结合元学习(meta-learning)的反馈生成模型,根据LLM当前的表现和错误模式,动态调整反馈的粒度、形式和侧重点,甚至能够识别并避免产生“无效反馈”。同时,深入理解模型内部状态将变得至关重要。
解决“反馈阻力”不光是追求模型性能的极限,更是解锁LLM在真实世界中巨大潜力的关键。因为,一个能有效克服反馈阻力的LLM,将能在科学发现中更迅速地迭代实验假设,在医疗诊断中更精准地吸收临床经验,在复杂工程规划中更敏捷地响应环境变化。它将不仅是一个强大的信息处理工具,更是一个真正意义上的智能伙伴,能够通过持续的交互和学习,不断提升自身的能力。


