1. 一眼概览
Quantum Cartpole 提出了一个结合弱测量与强化学习的量子控制基准环境,展示了深度强化学习在非线性量子系统控制中的显著优势,支持从经典模型迁移学习到量子系统。
2. 核心问题
传统的反馈控制方法难以直接应用于量子系统,主要由于测量引起的反作用和不可完全观测性。论文的核心问题是:在弱测量条件下,如何稳定控制一个处于非稳定势阱顶端的量子粒子,特别是在面对非线性系统和无法准确建模的噪声时,如何实现有效控制。
3. 技术亮点
- 量子Cartpole环境构建:引入弱测量反馈和单位力控制机制,作为强化学习控制的量子版本标准测试平台;
- 强化学习与传统控制对比:提出并比较了LQGC(线性-二次-高斯控制)与模型无关的RL控制器(含估计器RLE)在不同非线性势能下的表现;
- 迁移学习实践验证:首次实验证明可将RL模型从经典系统训练迁移至量子系统,控制效果几乎无损。
4. 方法框架
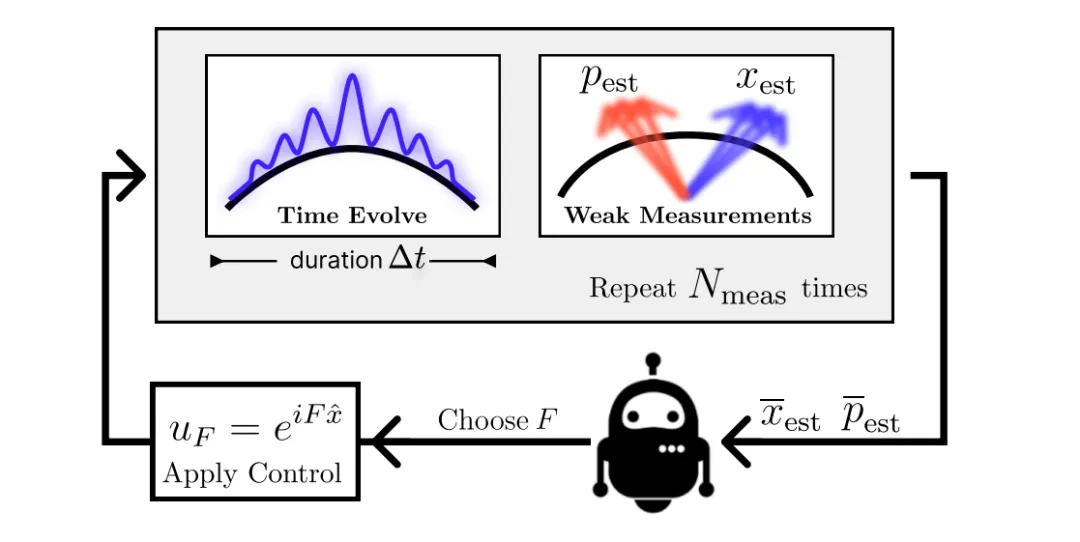 图片
图片
整体方法可概括如下:
• 量子系统建模:构建处于反向势阱的高斯波包量子粒子,施加单位冲击控制;
• 控制策略实现:
使用 LQGC(包括 Kalman 滤波器 + LQR)控制经典系统;
使用 RL 训练两个模块:RLC(控制器)+ RLE(估计器);
• 弱测量反馈机制:每 Δt 时间执行 N 次弱测量并求均值(frame-stacking),用于状态估计;
• 控制评估与迁移:在三种不同势能(反抛物线、余弦、四次方)中评估控制性能,并测试RL控制器的迁移能力。
5. 实验结果速览
• RL控制优于LQGC:在非线性系统(如quartic势能)中,RL控制器+Kalman估计器的稳定时间提升高达60%;
• 迁移学习效果佳:经典系统上训练的RL控制器迁移至量子系统后,性能几乎无衰减;
• RLE表现略逊于Kalman:但仍具备在单次测量下稳定控制能力。
6. 实用价值与应用
该工作为量子反馈控制问题提供了一个可标准化、可迁移的测试平台,适用于:
• 量子计算与量子仿真系统的鲁棒控制;
• 基于观测反馈的量子信息处理;
• 未来适应性强的量子机器人/装置决策系统;此外,它展示了在无法建模系统上使用RL替代传统控制器的可行性。
7. 开放问题
• RL控制器能否进一步替代估计器,实现完全 end-to-end 量子控制?
• 若测量资源受限(如稀疏/间断测量),强化学习策略是否仍有效?
• 是否可在更复杂的多体系统、非马尔科夫噪声环境中推广此控制框架?


