
译者 | 李睿
审校 | 重楼
随着机器学习对训练数据的需求与日俱增,传统的集中式训练方式在隐私要求、运营效率低下以及消费者日益增长的怀疑态度下不堪重负。由于道德和法律限制,医疗记录或支付历史等责任信息已经难以被简单地集中采集与处理。
在此背景下,联邦学习提供了一种截然不同的解决方案:它摒弃了“将数据传输至模型”的传统思路,转而采用“将模型推送至数据所在端”的创新模式。参与方基于自身数据在本地完成模型训练,仅共享训练所得的模型更新(如梯度或权重),而原始数据则始终保留于本地。
这种方式不仅从根本上保障了数据机密性,也使得原本因数据隔离而无法协作的各方能够共建共享智能模型,在保护隐私的同时打破了“数据孤岛”。
存在的问题
集中式数据管道虽然推动了人工智能的许多重大进步,但这种方法也存在着重大风险:
•隐私泄露:欧盟《通用数据保护条例》(GDPR)、美国《健康保险流通与责任法案》(HIPAA)以及印度的《数字个人数据保护法案》(DPDP)等法规对数据的收集、存储和传输设置了严格的限制。
•运行效率低下:在网络之间复制TB规模的数据既耗时又昂贵。
•基础设施成本高昂:存储、保护和处理庞大的集中式数据集需要成本昂贵的基础设施,对规模较小的组织构成沉重负担。
•偏见放大:集中式数据集会过度代表某些特定群体或机构的特征,导致基于此类数据训练的模型在广泛现实场景中的泛化能力下降。
上述问题使得集中式训练在多数实际应用场景中难以有效推行。
新范例:联邦学习
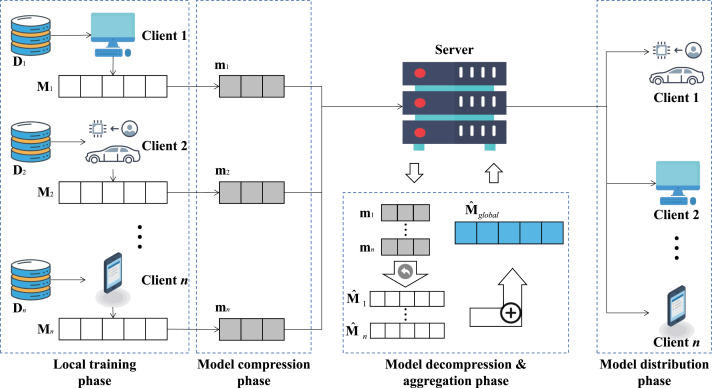
联邦学习(FL)颠覆了传统流程。它不是将原始数据集中到一个中心点,而是将模型安装到每个客户端(设备、医院或机构)。在本地进行训练,只将产生的模型更新内容(如权重或梯度)传输回中心。
联邦学习从根本上颠覆了传统的数据处理流程。它不再将原始数据汇集至中央服务器,而是将模型部署于每个客户端(例如设备、医院或机构)。客户端利用本地数据完成训练,仅将产生的模型更新(例如权重或梯度)回传至中央服务器进行聚合。
下图展示了联邦学习的工作流程:客户端在本地训练模型,并将更新结果发送至中央服务器;中央服务器将这些更新内容整合为一个全局模型。
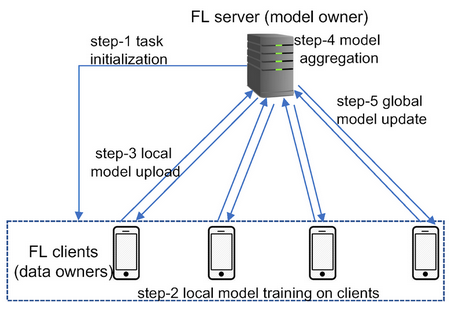
谷歌公司在2016年率先应用这一技术,在无需收集用户击键数据的前提下,成功提升了Gboard输入法的下一个单词预测能力。键盘在设备端进行本地学习,只上传模型更新,由系统整合为统一的全局模型。最终,谷歌在不损害任何用户输入隐私的情况下,持续优化了数百万设备的预测准确性。
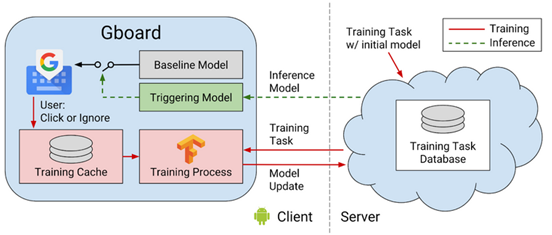
这一突破使得联邦学习受到关注。谷歌公司在2016年发表的论文中使用的联邦平均(FedAvg)算法构成了大多数现代联邦学习系统的核心。到2018年,研究人员通过压缩技术和安全聚合解决了通信开销和隐私问题。从2019年开始,联邦学习进入医疗、金融和制药等敏感领域,这些领域的合作基于严格的数据隐私。
通过让敏感信息始终保留在本地,联邦学习将这一理念的应用范围从移动键盘延伸至更广阔的领域,使得以往相互隔离的“数据孤岛”得以实现协同智能,从而在不牺牲隐私的前提下开辟了新的可能性。
隐私优先
联邦学习在设计之初便将隐私保护作为其核心原则:原始数据无需离开本地,其训练过程均在终端设备或机构内部服务器上完成。这一架构使其符合GDPR、HIPAA等数据法规的严格要求,使组织能够在合规前提下持续推动技术创新。
更重要的是,联邦学习成功释放了诸如医疗记录、银行交易历史等敏感数据的潜力——这些信息曾因隐私与合规顾虑而长期分散孤立。与此同时,该系统具备卓越的可扩展性,能够实时协调数百万台设备同步参与训练。
在安全层面,联邦学习凭借其分布式数据存储特性,显著降低了系统性风险:单一节点的安全漏洞不会导致整个数据库遭受威胁。此外,该技术还在保障隐私的同时实现了高效的个性化:本地模型持续学习用户特定行为(如键盘输入习惯与语音特征),而聚合后的全局模型则不断迭代优化,使所有用户共同受益。
一个值得关注的案例研究是医疗领域:多家医院使用联邦学习来预测败血症风险。每家医院都在本地进行学习,并只交换匿名化处理的信息,这使得这些医院的预测性能都得到了提高,并且遵循了患者隐私与合规要求(Rodolfo,2022)。
由于数据保留在本地,仅共享模型更新仍可能隐含敏感模式泄露的风险。差分隐私(DP)被引入作为有效补充,通过在更新中注入可控噪声,使得网络攻击者难以通过更新获得用户信息。
安全多方计算(SMPC)和同态加密(HE)在聚合时以一种任何人(甚至是服务器)无法知道原始贡献的方式保护更新。
此外,联邦学习仍面临对抗性攻击风险击的挑战:例如模型中毒允许注入恶意更新,推理攻击可能试图获取机密信息。目前防御方法包括:强大的聚合规则、异常检测以及能够在安全性和模型实用性之间取得平衡的隐私保护方法。
联邦学习的类型
联邦学习并不是“一刀切”的方案。其架构需根据机构的数据分布特点调整。有时,不同组织收集不同用户群体的相似信息;有时收集相似用户群体的不同信息;有时甚至是用户和特征部分重叠的信息。针对这些场景,联邦学习被具体分为三类:横向联邦学习、纵向联邦学习、联邦迁移学习。
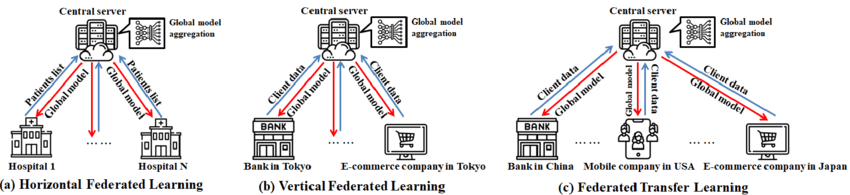
横向联邦学习
横向联邦学习是指在多个组织间开展协作学习的一种模式,其特点是各参与方数据特征空间相同,但覆盖的用户群体不同。例如,不同医院可能拥有结构相同的患者信息(如年龄、血压、血糖水平等),但这些数据来源于不同的患者群体。在该模式下,各方仅在本地进行模型训练,只上传模型参数更新(而不是原始数据),从而在无需共享数据的前提下,共同构建更优的全局模型,通过这种方式可以有效提升模型的泛化能力(Jose, 2024)。
垂直联邦学习
在纵向联邦学习中,多个组织拥有同一批客户群体,但各自掌握不同的特征数据。例如,银行可能持有客户的资金流水记录,而电子商务公司则拥有同一批用户的购物历史。双方可通过加密信道安全地整合这些互补的数据特征,在不泄露原始数据的情况下训练联邦共享的模型。该机制为欺诈检测、风险评估与信用评分等场景提供了高效且合规的解决方案(Abdullah, 2025)。
联邦迁移学习
联邦迁移学习则适用于各方数据主体重叠度较低、特征交集极少的场景。例如,一家机构可能拥有医学影像数据,而另一家机构则掌握不同患者群体的实验室数据。即使在这样的数据异构条件下,联邦迁移学习仍能借助联邦模型更新,安全地迁移已经学习到的特征表示,从而在不共享原始数据的前提下实现跨机构协作。
WeiGuo(2024)指出,其所提出的方法进一步将联邦学习推广至地理分散、数据高度异构的环境中,显著增强了跨行业、跨研究领域的隐私保护协作能力。
联邦学习的工作原理
联邦学习是一种分布式机器学习模式,多个客户端(例如电话、医院或公司)利用本地数据训练模型。原始数据不会上传到某个中间人服务器,而上传的是模型更新内容。
步骤1:客户端选择和模型初始化
中间人服务器初始化全局模型,并选择符合条件的客户端(在线状态、空闲状态、数据量是否充足)。
步骤2:本地训练
被选中的客户端使用本地数据,通过小批量随机梯度下降等常用算法对接收到的全局模型进行训练。
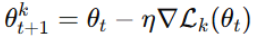
可选的隐私保护措施:安全飞地(基于硬件的保护)或差分隐私(添加噪声)。
步骤3:模型更新共享
客户端不发送原始数据;与其相反,它们会发送参数更新(梯度/权重)。这些更新内容可以通过安全聚合进行加密或屏蔽。
步骤4:联邦平均(FedAvg)
服务器使用联邦平均(FedAvg)聚合客户端更新:
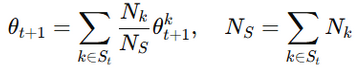
其中Nk是客户端k的数据集的大小。
异步或分层聚合可用于大规模部署以提高效率。
步骤5:全局模型分发和迭代
新生成的全局模型会被重新分发以进行另一轮训练。迭代会持续进行,直到模型收敛或达到性能目标。
实际应用示例
谷歌的“Hey Google”语音查询功能使用了联邦学习,使得语音数据在每部手机上进行本地处理。手机只传输模型更新内容,而不是声音片段,从而确保了在不牺牲隐私的情况下保证更好的模型(Jianyu, 2021)。
核心技术组件
联邦学习使得多个分散的客户端能够在不共享原始数据的情况下协作学习机器学习模型。分布式模型依赖于多个管理计算、通信、聚合和安全的技术组件。由于这些组成部分之间的协同作用,联邦学习的范式具有可扩展性、高效性和隐私保护性。
1.联邦平均(FedAvg)
联邦平均(FedAvg)是联邦学习的核心。在该模型中,每个客户端都根据自己的数据在本地训练模型,并将参数更新发送到中央服务器,而不是模型本身。服务器将这些更新(最常见的是通过平均)整合到全局模型中。这个过程在训练中反复迭代,直到收敛。
以下摘录提到了基本步骤:在客户端数据上进行本地训练,独立地将更新内容(而不是原始数据)传输到服务器,以及服务器对更新进行平均以提高全局模型的准确性。
Python
1
复制2.同步机制
有两种方法可以对模型更新内容进行同步:
- 同步训练:服务器保持空闲状态,直到所有客户机完成更新并取其平均值。它提供了一致性,但可能会因运行较慢的设备增加延迟(“滞后节点问题”)。
- 异步训练:服务器会在收到更新内容时立即进行更新,从而更快地完成工作,但偶尔会使用稍微过时的参数。
3.客户端设备
客户端是联邦学习的基石。它们可能是智能手机、物联网设备或大型企业服务器。每个客户端在本地使用私有数据训练模型,并只共享更新内容,这有助于保护隐私,同时还捕获参与者之间非独立同分布(non-IID)数据集的多样性。
4.中央服务器(聚合器)
聚合器负责处理训练工作。它提供初始的全局模型,收集客户端的更新内容,将其整合,并重新分发改进后的模型。它还必须应对现实世界中的挑战,例如客户流失、硬件能力的变化和参与水平的不平衡。
5.通信效率
由于联邦学习在大多数情况下是在带宽受限的设备和网络上运行的,因此必须最小化通信开销。模型压缩、稀疏化和量化等方法可以在不牺牲模型性能的情况下显著降低数据传输成本。
6.处理异构性
客户端设备在数据分布、计算和网络稳定性方面具有高度的异构性。为了解决这个问题,个性化联邦学习和FedProx优化等方法使模型能够在动态条件下表现良好,从而促进公平性和鲁棒性。
7.容错性和鲁棒性
最后,联邦学习系统对失败甚至主动的恶意尝试具有弹性。客户端采样、退出处理、异常检测和信誉评估等技术即使在动荡的环境中也能确保可靠性。
效率优化技术
联邦学习通过压缩模型更新的方法将通信成本降至最低。稀疏化、量化和压缩在不牺牲模型精度的情况下减少了数据大小,从而使得即使在低带宽设备上也可以进行训练。
压缩技术
压缩方法通过减少冗余信息的表示以最小化客户端和服务器之间传输的模型更新内容的大小。例如,预测编码消除了模型梯度中的冗余,在不影响学习性能的情况下大幅降低了通信成本。
量化
量化通过使用更低精度的数值(例如将32位浮点数转换为8位整数)来表示模型权重或梯度,从而减少通信开销。近年来的研究引入了误差补偿机制,以最大限度地减少精度损失,使量化成为带宽受限联邦系统的可行解决方案。
稀疏化
稀疏化通过仅传输对模型性能有关键影响的梯度更新,同时舍弃贡献微小的部分,以此降低通信负载。在实际应用中,这种方法能大幅减少传输数据量,如果与量化技术结合,则可实现更高的压缩比。
构建隐私优先的未来
联邦学习不仅是一种在没有原始数据的情况下训练模型的方法,也是人工智能系统中数据、协作和信任管理的重新定义。
数据主权
通过保留原始数据或机器的信息,联邦学习可以满足GDPR和HIPAA等高度严格的隐私法规,并且可以在不公开敏感数据的情况下实现跨国协作。
英伟达公司与伦敦国王学院、Owkin公司合作,使用联邦学习在多家医院训练脑肿瘤分割模型。各个机构都在从BraTS 2018数据集中获取的磁共振成像(MRI)扫描上进行本地训练,并只共享匿名化更新内容,并通过差分隐私技术增强隐私保护。最终,联邦学习方案的准确率与中心化训练相当,且患者信息全程未离开医院服务器。这清晰地表明了联邦学习在医学领域的可行性(英伟达与伦敦国王学院,2019年)。
人工智能民主化
联邦学习使得小型机构与边缘设备能够通过共享模型更新(而非数据)来参与协作训练。谷歌Gboard等案例表明,联邦学习能够优化数百万设备的系统性能,而无需集中任何数据。
鲁棒性和安全性
联邦学习通过引入安全聚合和差分隐私等技术来增强保护。这确保了即使是由设备发送的微小模型更改也不能被反编译。也就是说,黑客甚至中央服务器都无法使用共享参数拼凑敏感的本地数据。
更公平的代表性
联邦学习基于各种分散的数据进行训练,从而最大限度地减少了在小规模集中数据上进行训练时可能出现的偏差。这提高了模型在不同人群中的代表性,增强了医疗、金融服务和教育等领域的公平性。
结论
联邦学习有力地证明,隐私保护与模型性能无需以牺牲对方为代价。通过将数据保留在源头,同时实现协同智能,联邦学习解决了人工智能面临的一些核心挑战:合规性、信任、公平性和安全性。从数百万台智能手机优化预测输入法,到协助多家医院改善患者治疗效果,这项技术已经在重塑智能系统的构建方式。
人工智能的未来不再是以牺牲隐私为代价,而是在其背后构建智能系统。联邦学习不仅仅是一项技术方案,更是引领人们迈向更安全、更民主、更具代表性的人工智能未来的路线图。
原文标题:Federated Learning: Training Models Without Sharing Raw Data,作者:Saisuman Singamsetty


