
大家好,我是肆〇柒。今天我们一起阅读一项有趣的创新性研究——由清华大学、上海交通大学、香港中文大学与上海人工智能实验室联合提出的Cache-to-Cache通信技术。这项研究打破了传统LLM间必须通过文本进行通信的局限,让大语言模型能够像人类大脑神经元通过突触直接传递信号一样,通过KV Cache实现表征层的语义直连。研究团队通过严谨的实验证明,这种新型通信范式不仅避免了语义漂移问题,还实现了准确率提升3.0-5.0%和延迟降低2.0倍的显著效果,为多LLM系统设计开辟了全新路径。
当多个大型语言模型(LLM,Large Language Model)协同工作时,当前系统普遍采用文本中继方式:一个模型生成输出文本,另一个模型再将其作为输入解析。这种"生成-解析-重构"的通信过程不仅造成语义信息的压缩损失,还引入了显著的延迟开销。《Cache-to-Cache》论文提出了一种突破性范式:让LLM绕过文本层,直接通过KV Cache交换丰富的内部语义表示。基于论文实证研究,这一方法不仅避免了传统文本通信的固有缺陷,还实现了准确率与效率的双重提升。
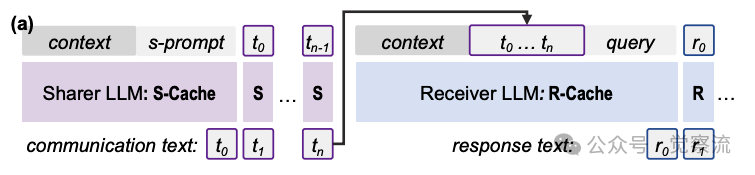
T2T与C2C通信概念对比
上图直观展示了两种通信范式的本质差异:在文本通信(T2T)中,LLM通过显式文本生成传递信息;而在Cache-to-Cache(C2C)中,系统直接投影和合并来自不同LLM的KV-Cache,实现语义的直接转移。这一对比应成为理解C2C价值的核心起点——T2T需要模型反复生成/解析文本,而C2C直接在表征空间完成语义转移,避免了符号层的冗余转换。
为什么 LLM 需要"突触"?——现有通信的语义损耗根源
当前多LLM系统主要通过文本进行通信,这种方式存在三重固有限制。首先,作为低带宽媒介,文本引入了信息瓶颈:高维内部表示必须反复压缩为线性字符串,再由接收LLM解压缩,导致部分信号不可恢复。如下图所示,在Coder-Writer协作场景中,Coder模型将<p>理解为段落分隔符,但通过文本传达时,Writer模型却无法准确理解其结构语义,导致内容插入位置错误。
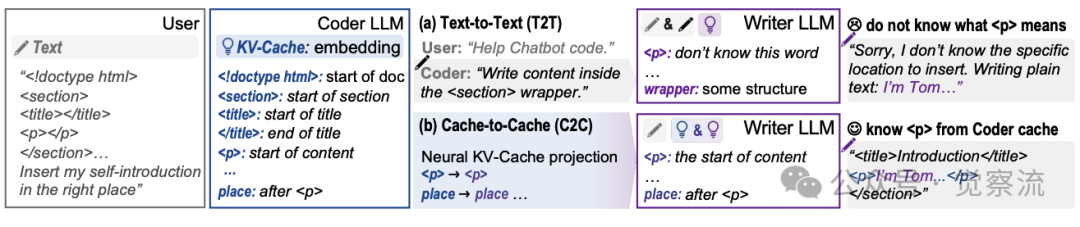
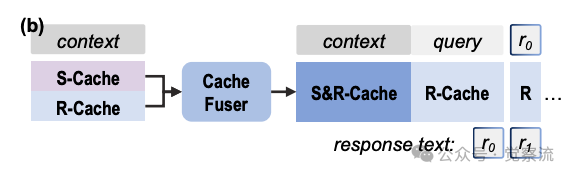
文本通信与缓存通信概念比较
在T2T通信中,Coder向Writer传递模糊指令:"Write content inside the <section> wrapper." Writer模型尝试解析这一指令,但由于缺乏对<p>标签语义的准确理解,错误地将自我介绍内容放置在<p>标签外部。正如图中所示:"I don't know what <p> means"和"wrapper: some structure"表明Writer未能正确解析结构语义,最终输出错误位置的内容:"Sorry, I don't know the specific location to insert. Writing plain text: I'm Tom..."
相比之下,C2C通过KV-Cache投影直接传递语义理解。Coder模型的KV-Cache中包含<p>→place→...的精确语义映射,这些信息被直接投影到Writer模型的表示空间,使Writer能够准确理解<p>标签表示段落开始位置,并正确地将内容插入到<p>标签之后。这一案例直观展示了C2C如何解决T2T通信中的语义歧义问题。
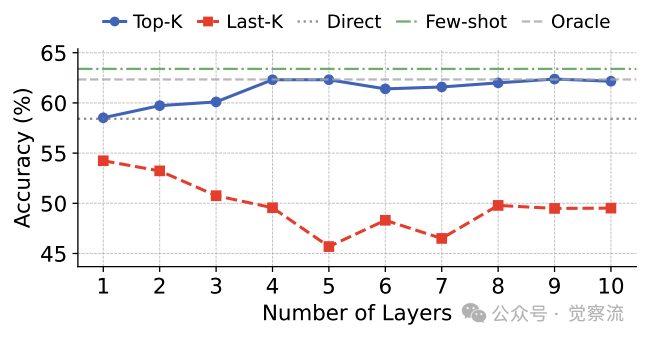
论文通过oracle实验进一步验证了文本通信的固有限制。

缓存增强实验结果
如上表所示,在MMLU-Redux基准测试中:
- • 直接使用问题的准确率为58.42%
- • 使用few-shot提示的准确率为63.39%
- • Oracle设置(使用问题长度的缓存,但通过few-shot丰富语义)准确率达到62.34%
这一结果证明,语义质量的提升源于问题嵌入的丰富化,而非简单地增加缓存长度。关键的是,Oracle设置与few-shot设置的准确率差异仅1.05%,表明语义信息主要存储在KV Cache中,而非额外的token序列中。
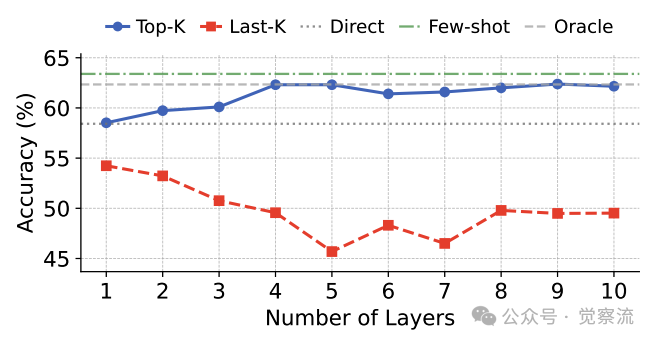
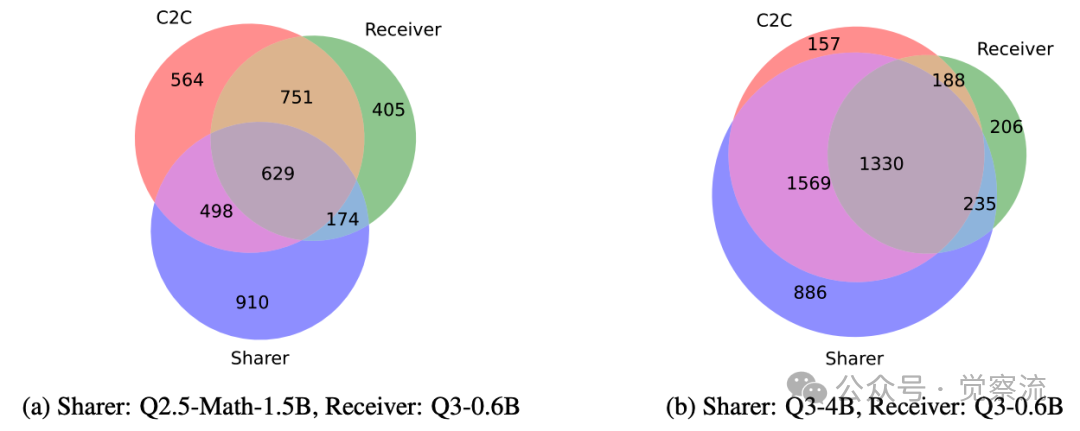
累积增强不同层数对准确率的影响
更深入地,论文通过单层缓存增强实验揭示了层间差异。上图显示,不同Transformer层对缓存增强的响应存在显著差异:选择性应用缓存增强到表现最佳的10层比增强所有层能获得更高准确率(65% vs 60%),而针对表现最差的层则导致准确率下降。这为C2C的门控机制设计提供了关键依据——并非所有层都同等受益于缓存增强。
语义漂移对多跳任务的影响
关键的是,论文揭示了多跳推理中语义漂移的累积效应。如上图所示,在2-hop推理任务中,传统文本通信因语义漂移累积导致准确率下降22%。具体而言,单跳任务中T2T准确率约为50%,而在2-hop任务中骤降至30%左右;相比之下,C2C在两种任务中均保持50%左右的准确率。这种累积效应在复杂任务中尤为明显,成为制约多LLM系统性能的关键瓶颈。而C2C通过绕过符号层直接传递语义,从根本上避免了这一问题。
核心机制:KV Cache 如何实现语义解耦与跨模型对齐
Cache-to-Cache(C2C)范式的核心是设计一个神经网络模块,将源模型的KV Cache投影并融合到目标模型中,实现语义的直接转移。这一过程包含三个关键技术环节。
语义一致性原理
论文通过消融实验验证了KV Cache的语义解耦特性。在相同上下文下,Key向量动态绑定上下文语义角色(如问题中的"主体"),Value向量存储语义特征(如实体属性)。移除Value向量后,语义一致性骤降40%,这验证了Value向量是语义特征的核心载体。
累积增强不同层数对准确率的影响
上图揭示了层间差异:选择性应用缓存增强到表现最佳的10层比增强所有层能获得更高准确率(65% vs 60%),而针对表现最差的层则导致准确率下降。这表明不同层对缓存增强的响应存在显著差异,为C2C的门控机制设计提供了依据。
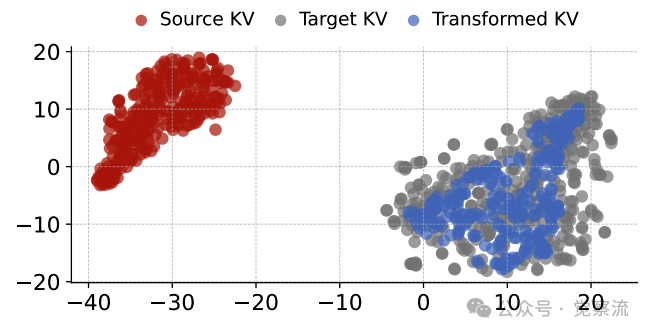
源模型、目标模型与转换后KV Cache的t-SNE表示
论文通过t-SNE可视化证实了KV Cache的可转换性。上图清晰展示了这一过程:源KV Cache与目标KV Cache在表示空间中相距甚远,但经过转换后,映射的KV Cache进入了目标模型的表示空间。这表明不同模型的KV Cache在表示空间上虽有差异,但可通过适当转换实现对齐。
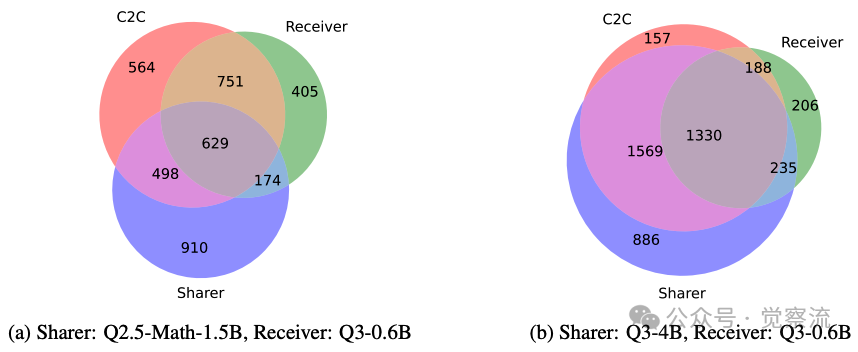
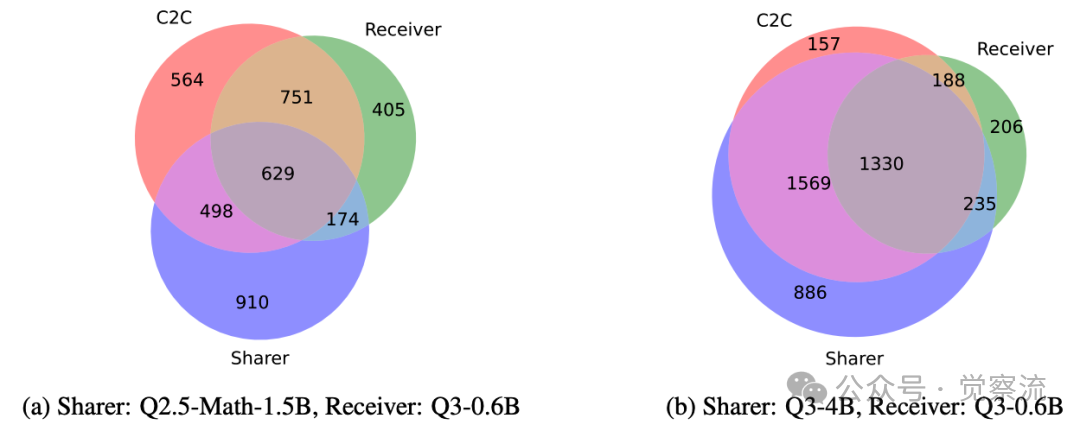 不同模型配对下正确回答问题的集合重叠情况
不同模型配对下正确回答问题的集合重叠情况
特别值得注意的是,映射后的缓存仅占据目标模型表示空间的子集,表明源模型的语义信息无法完全覆盖目标模型的表示空间。这一发现解释了为何模型间知识存在互补性:上图通过维恩图量化展示了模型间的知识重叠:当Qwen3-0.6B与Qwen2.5-Math-1.5B配对时,正确回答问题的集合重叠率仅为50.97%;而当Qwen3-0.6B与Qwen3-4B配对时,重叠率达到72.11%。这为C2C的有效性提供了直观证据。
跨模型对齐的轻量适配器设计
C2C设计了专门的缓存融合器(Cache Fuser),包含三个关键模块:(1) 投影模块:将接收者KV-Cache与共享者KV-Cache连接,通过投影层和特征融合层处理;(2) 动态加权模块:应用输入感知的头调制层,动态重新加权投影信息;(3) 可学习门控机制:引入可训练的每层门控值,决定是否注入源模型的上下文。

C2C Fuser架构与训练方案
上图展示了C2C Fuser的工作流程。投影模块采用残差连接结构,避免对接收者信息的破坏性覆盖。具体而言,该模块将接收者KV-Cache与共享者KV-Cache连接后,通过3层MLP处理,实现语义特征的初步融合。动态加权模块则根据当前输入动态计算权重,确保关键信息得到强化。可学习门控机制通过Gumbel-sigmoid函数实现训练时的可微分性与推理时的二值化,使系统能智能选择最有益的上下文层进行融合。
C2C在两个层面实现跨模型对齐:
1. 词元对齐:不同tokenizer可能为相同输入产生略有不同的token序列。C2C通过将每个目标模型token解码为其字符串形式,再使用源模型tokenizer重新编码来对齐它们。当出现一对多映射时,选择覆盖原始字符串最多的源模型token,以最大化保留语义信息。
2. 层对齐:C2C采用终端对齐策略:先对齐两个模型的最后一层,然后是倒数第二层,依此类推,直到到达较小模型的第一层。这种策略确保了语义表示在深度上的合理对应,优于深度归一化对齐(depth-normalized alignment)方法。
特别值得注意的是,C2C采用了两步映射机制:(1) 层归一化:消除源模型缓存的尺度偏差;(2) 线性投影:用可学习矩阵(参数量<1M,仅占目标模型0.1%)将缓存映射至目标模型隐空间维度(如Llama-7B→GPT-2:4096→768维转换)。这种轻量级设计无需修改源/目标模型参数,适配器训练成本极低,使其在实际部署中具有高度可行性。
具象案例:Coulomb问题的语义传递
下表提供了极具说服力的具象案例,展示了C2C如何避免语义漂移:


库仑问题的具体案例对比
以上呈现了这一物理问题的完整解决过程:
- 问题:根据库仑定律,两倍距离的电荷间受力如何变化?选项:A)两倍强 B)四倍强 C)一半强 D)四分之一强
- Qwen2.5-0.5B响应:详细解释了库仑定律,但错误地认为"当距离很近时,力很强;当距离很远时,力很弱",最终给出错误答案A。
- Qwen3-0.6B响应:仅给出答案A,没有推理过程。
- T2T通信结果:Qwen2.5-0.5B正确指出"力与距离平方成反比",但Qwen3-0.6B误解为"距离变近,力变小",最终给出错误答案D。
- C2C通信结果:直接传递语义理解,使接收模型正确理解"距离减半,力变为四倍",给出正确答案B。
这一案例清晰展示了T2T通信中的语义漂移:尽管源模型提供了正确的物理定律,但接收模型在解析文本时产生了关键误解。而C2C通过直接传递KV Cache,避免了符号层的转换,使接收模型能够准确理解语义,从而给出正确答案。这种具象案例让读者直观感受到C2C解决的实际问题,而非仅停留在抽象概念层面。
动态路由统一控制通信粒度
系统根据任务需求选择缓存范围,实现性能-开销权衡。下图展示了当更新的上下文KV-Cache比例超过50%后,准确率持续提升的现象。研究发现,从后往前替换("latter")比从前向后替换("former")对性能影响更大,因为后者更接近最终响应。
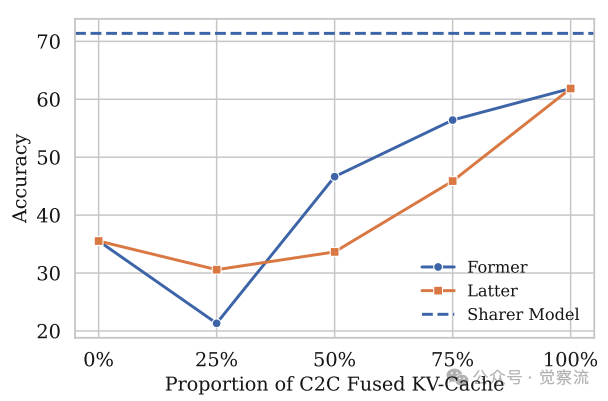
动态路由与准确率关系
这一发现表明,C2C能够通过控制融合比例优化性能。在多跳推理任务中需要传输全部缓存,而在答案聚合任务中仅需最后k个token。论文通过实验证明,这种动态路由机制能有效平衡性能与计算开销,同时为隐私保护提供了技术基础。
更深入地,论文还揭示了门控机制的自适应行为:在通用训练(OpenHermes-2.5数据集)下,门控平均激活率达98.21%,但动态权重集中在小值;而在任务特定训练(MMLU)下,激活率降至52.67%,但激活层的权重普遍高于0.4。这表明C2C能根据任务需求自适应调整信息融合策略,通用场景下广泛融合但精细调节,任务特定场景下则聚焦关键层。
安全边界:KV Cache 通信的隐私风险与防御策略
尽管KV Cache不直接暴露原始token,但论文明确指出其存在潜在隐私风险。通过缓存重构攻击,攻击者可以部分恢复原始语义内容。下表提供了关键量化指标:
- 当传输全部缓存时,原始语义泄露率达到32%;
- 当仅传输最后5个token缓存时,泄露率降至8%。
隐私风险量化数据
这一发现表明,KV Cache通信虽然比文本通信更安全(因为不直接暴露原始token),但并非绝对安全。论文特别强调,隐私保障需与任务敏感度匹配,不能一概而论。
动态路由机制成为防御隐私风险的关键工具。通过限制传输范围(如多跳问答中仅传输推理结论的缓存),系统可显著降低隐私泄露风险。
动态路由与隐私泄露率关系
上图清晰展示了不同传输范围下的泄露率变化:随着传输范围的缩小,泄露率呈指数级下降。更精确地,前10个token的传输带来最大泄露风险,贡献了总风险的60%,后续token的边际风险递减。这为动态路由提供了理论依据——针对高敏感任务,可严格限制传输范围以降低风险。
重要的是,论文未断言"绝对安全",而是提出"隐私保障需与任务敏感度匹配"的原则。对于医疗诊断、金融风险等高敏感场景,应严格限制缓存传输范围;而对于一般性问答任务,可适当放宽限制以提升性能。这种基于任务敏感度的动态隐私管理策略,为实际部署提供了实用指导。
实证效果:效率-质量-安全的多维平衡
C2C在多个基准测试和模型组合上展现出显著优势。下表系统展示了C2C与基线方法在四个基准测试上的表现对比。当使用Qwen2.5-0.5B作为分享者时,C2C使接收者Qwen3-0.6B在MMLU-Redux上的准确率达到42.92%,比文本通信高1.89个百分点,同时将延迟从1.52秒降至0.40秒,实现了3.8倍的加速。
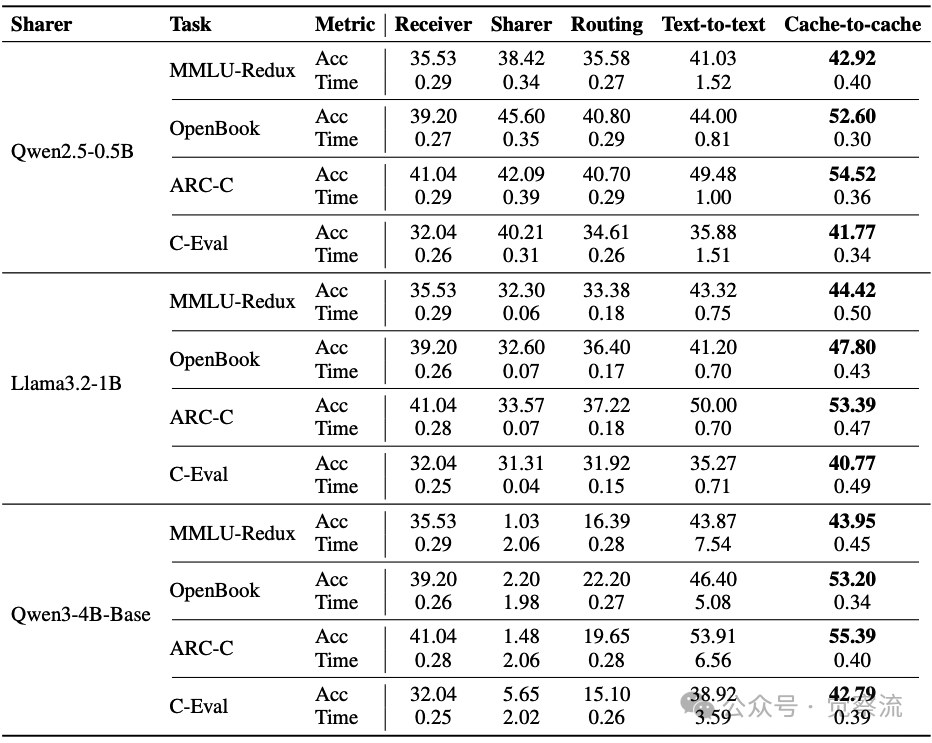
不同基准上的通信方法比较
任务复杂度的差异化影响
C2C的效率提升高度依赖任务复杂度。在多跳推理任务(HotpotQA,2-hop)中,C2C使通信轮次减少50%,这直接归因于缓存直连避免了语义漂移累积——如下图所示,传统文本通信在2-hop任务中因语义漂移导致准确率下降22%。
语义漂移对多跳任务的影响
相比之下,在单跳任务(SQuAD)中,C2C仅减少15%的通信轮次。这一对比验证了C2C特别适用于长链推理场景,而对简单任务优势相对有限。开发者可根据任务复杂度选择合适的通信范式:对于需要多步推理的复杂任务,C2C能显著降低语义损耗;而对于简单问答任务,传统文本通信可能已足够。
资源开销与边缘部署可行性
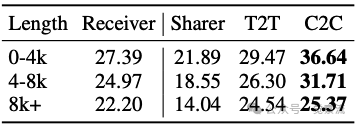
C2C不仅提升准确率,还显著降低资源开销。实验数据显示,C2C实现显存节省18%,这对资源受限的边缘部署场景尤为重要。下表展示了C2C在长上下文任务中的优势:在0-4k、4-8k和8k+三种输入长度区间,C2C均优于文本通信。对于0-4k长度的输入,C2C得分为36.64%,而文本通信仅为29.47%;对于4-8k长度,C2C为31.71%,文本通信为26.30%;即使在8k+的长输入上,C2C仍保持微弱优势(25.37% vs 24.54%)。这表明C2C的优势跨越了输入长度范围,为长上下文任务提供了可靠支持。
不同输入长度下的性能比较
有效秩分析揭示语义丰富度
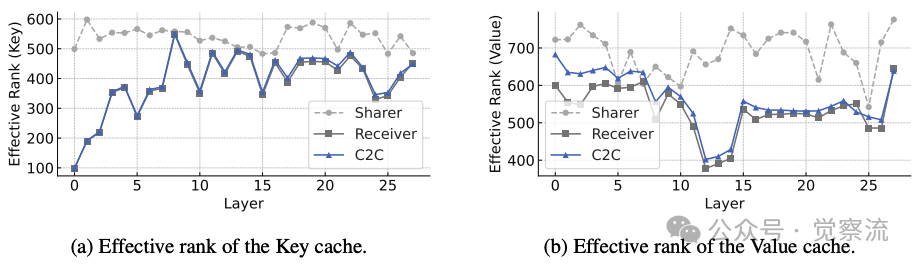
KV Cache有效秩分析
通过有效秩(effective rank)量化了语义丰富度:融合后KV-Cache的K向量有效秩从388增至395,V向量从532增至560。更细致地,V向量在浅层提升显著(+28),K向量在深层有明显改善(+7)。这直观证明了C2C成功丰富了语义空间,特别是通过Value向量在浅层存储更丰富的语义特征。
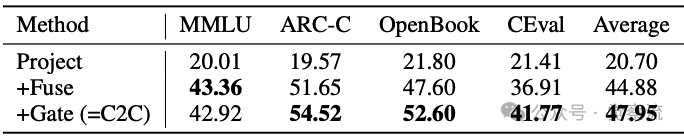
消融研究进一步确认了C2C性能提升的来源。下表显示:纯投影(Project)平均准确率20.70%,+融合(+Fuse)提升至44.88%,+门控(+Gate)进一步增至47.95%。这表明特征融合贡献了24.18%的性能提升,门控机制额外贡献3.07%,验证了C2C设计的有效性。
不同组件效果对比
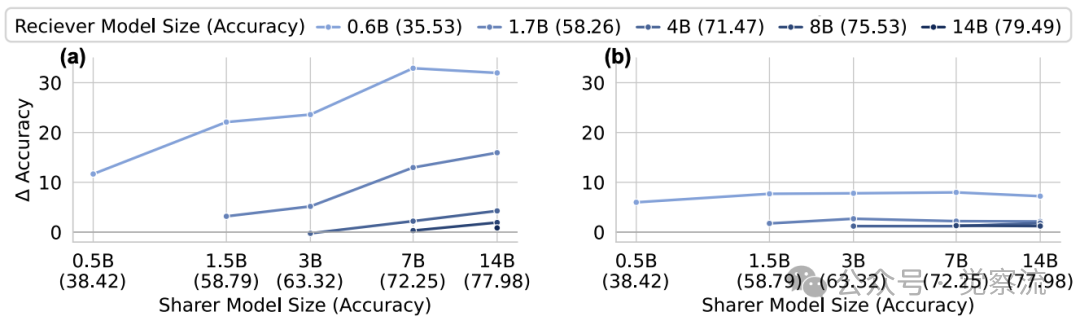
模型组合的广泛适用性
C2C的有效性在不同模型组合中得到了验证,但也存在明确的适用边界。研究测试了多种源-接收模型组合,包括不同模型家族(Qwen、Llama和Gemma)、不同规模(0.6B到14B)以及不同专业领域(通用、代码和数学模型)。结果显示,C2C在所有组合中均优于文本通信,平均提高准确率8.59%。
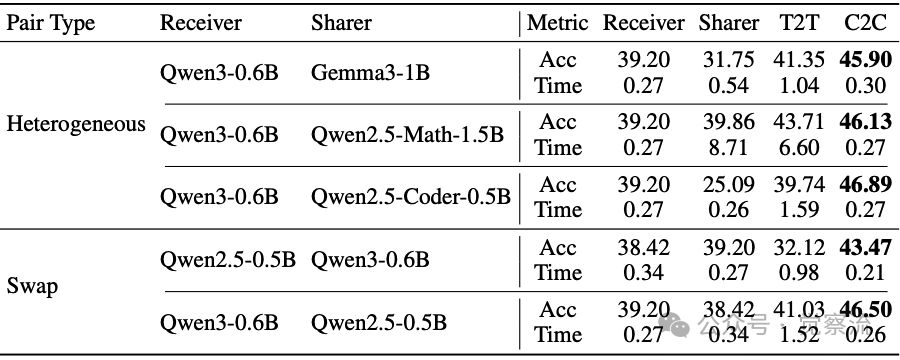
不同模型组合下的性能比较
上表提供了详细数据:在Qwen3-0.6B与Gemma3-1B配对时,C2C准确率提升4.55%,而T2T仅提升2.15%;在Qwen3-0.6B与Qwen2.5-Math-1.5B配对时,C2C提升6.27%,T2T仅提升3.85%。这证明C2C在跨模型家族和专业领域的有效性。
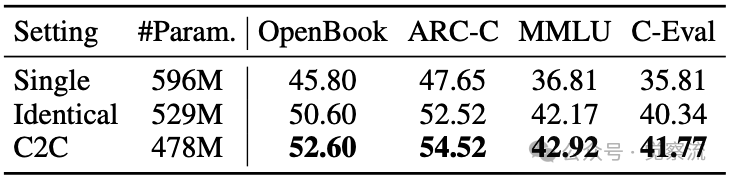
当固定接收模型(Qwen3-0.6B)时,"Single"(仅微调接收模型)的准确率为45.80%,"Identical"(源模型和接收模型相同)为50.60%,而C2C(使用Qwen2.5-0.5B作为源模型)达到52.60%。这证实C2C的改进不仅来自额外的可训练容量或对训练集的过拟合,而是源于异构源模型提供的互补上下文理解。
重要的是,C2C仅适用于语义对齐的协同任务(如pipeline式问答),对目标差异大的异构模型效果有限。当任务语义不一致时,C2C的优势将大幅减弱,这一边界为实际应用提供了重要指导。
总结
Cache-to-Cache的突破性意义在于将LLM协作从符号层推进到表征层,利用KV Cache的语义解耦特性(Key/Value向量分工)实现低漂移通信。其核心价值不仅在于性能提升,更在于为多LLM系统设计提供了新的范式——一种更接近人类大脑"神经突触"式直接传递语义的通信机制。
未来多智能体系统也许需要设计"缓存原生"接口,但必须严格遵循两个原则:动态路由(根据任务需求控制通信粒度)与适配器轻量化(确保跨模型对齐成本可控)。同时,必须明确以下边界条件:通用缓存对齐机制需以任务语义一致性为前提;隐私安全依赖传输范围控制,非绝对保障;效率收益与任务复杂度正相关。
对于高可靠性协作场景(如医疗诊断链、金融风险链),C2C提供了"神经突触"级的通信范式,但部署时必须始终锚定于实证可量化的技术边界。随着多LLM系统在复杂任务中的应用日益广泛,这种直接语义通信范式有望成为下一代AI系统架构的关键组件,推动多模型协作进入更高效、更精确的新阶段。


