作者 | masonpy
本文尽量用最简单的方式, 帮读者理解 LLM,Transformer, Prompt, Function calling, MCP, Agent, A2A 等这些基本概念。 表述时不追求绝对准确,尽量通俗易懂,部分内容有个人理解的成份,内容难免疏漏, 欢迎指正。
注意:本文需要你有基本的代码阅读能力,当然非开发阅读也不会很困难。

一、LLM (大语言模型)
本质就是文字接龙
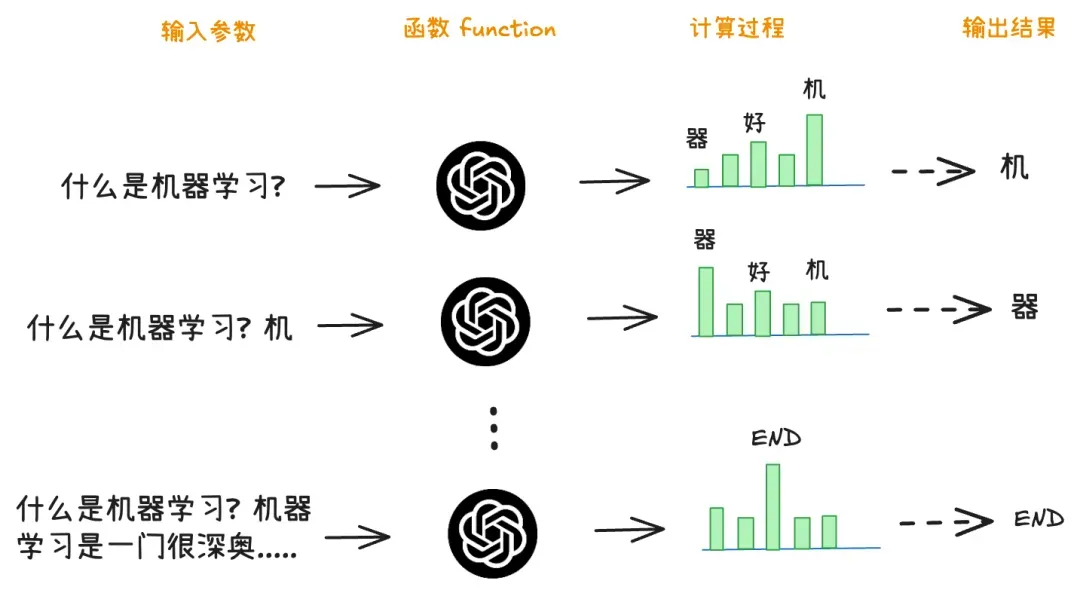
把问题当成输入, 把大模型当成函数, 把回答当成输出。
大模型回答问题的过程, 就是一个循环执行函数的过程。
另外有必要了解一下, AI技术爆发于2023年, ChatGPT经过了几次迭代才崭露头角。
- Transformer架构
- 参数爆发增长
- 人工干预奖励模型
思考题: 语言能代表智能吗?
二、Transformer (自注意力机制)
自注意力机制就是动态关联上下文的能力. 如何实现的呢?
(1) 每个分词就是一个 token
(2) 每个token 都有一个 Q, K, V 向量 (参数)
- Q 是查询向量
- K 是线索向量
- V 是答案向量
(3) 推理的过程:
- 当前token 的Q 与 前面所有的 K 计算权重
- 每个 token 的V加权相加得到一个 token预测值
- 选择 N 个与预测值最接近的 token, 掷骰子选择
最简化示例:小明吃完冰淇淋,结果 => 肚子疼
首先分词及每个token的 Q, K, V向量:
token | Q(查询) | K(键) | V(值) | 语义解释 |
小明 | [0.2, 0.3] | [0.5, -0.1] | [0.1, 0.4] | 人物主体 |
吃完 | [-0.4, 0.6] | [0.3, 0.8] | [-0.2, 0.5] | 动作(吃完) |
冰淇淋 | [0.7, -0.5] | [-0.6, 0.9] | [0.9, -0.3] | 食物(冷饮,可能致腹泻) |
结果 | [0.8, 0.2] | [0.2, -0.7] | [0.4, 0.1] | 结果(需关联原因) |
接着开始推理:
1. 使用最后一个 token 的 Q(“结果”的 Q 向量)
Q_current = [0.8, 0.2]
2. 计算 Q_current 与所有 K 的点积(相似度)
点积公式:Q·K = q₁*k₁ + q₂*k₂
Token | K向量 | 点积计算 | 结果 |
小明 | [0.5, -0.1] | 0.8 * 0.5 + 0.2*(-0.1) = 0.4 - 0.02 | 0.38 |
吃完 | [0.3, 0.8] | 0.8 * 0.3 + 0.2 * 0.8 = 0.24 + 0.16 | 0.40 |
冰淇淋 | [-0.6, 0.9] | 0.8*(-0.6) + 0.2 * 0.9 = -0.48 + 0.18 | -0.30 |
结果 | [0.2, -0.7] | 0.8 * 0.2 + 0.2*(-0.7) = 0.16 - 0.14 | 0.02 |
3. Softmax 归一化得到注意力权重
将点积结果输入 Softmax 函数
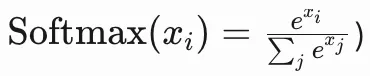
Token | 点积 | 指数值(e^x) | 权重 |
小明 | 0.38 | e^0.38 ≈ 1.46 | 1.46 / 2.74 ≈ 0.53 |
吃完 | 0.4 | e^0.40 ≈ 1.49 | 1.49 / 2.74 ≈ 0.54 |
冰淇淋 | -0.3 | e^-0.30 ≈ 0.74 | 0.74 / 2.74 ≈ 0.27 |
结果 | 0.02 | e^0.02 ≈ 1.02 | 1.02 / 2.74 ≈ 0.37 |
4. 加权求和 V 向量生成上下文向量
将权重与对应 V 向量相乘后相加:
Token | 权重 | V向量 | 加权 V 向量 |
小明 | 0.53 | [0.1, 0.4] | 0.53*[0.1, 0.4] ≈ [0.053, 0.212] |
吃完 | 0.54 | [-0.2, 0.5] | 0.54*[-0.2, 0.5] ≈ [-0.108, 0.27] |
冰淇淋 | 0.27 | [0.9, -0.3] | 0.27*[0.9, -0.3] ≈ [0.243, -0.081] |
结果 | 0.37 | [0.4, 0.1] | 0.37*[0.4, 0.1] ≈ [0.148, 0.037] |
最终上下文向量:
[0.053−0.108+0.243+0.148,0.212+0.27−0.081+0.037]=[0.336,0.438]
5. 预测下一个 token
模型将上下文向量 [0.336, 0.438] 与候选 token 的嵌入向量对比:
嵌入向量不作过多解释, 只要知道QKV三个向量可从嵌入向量计算得到即可
候选词 | 嵌入向量 | 相似度(点积) | 概率 |
肚子疼 | [0.3, 0.5] | 0.336 * 0.3 + 0.438 * 0.5 ≈ 0.101 + 0.219 = 0.320 | 最大概率(例如 65%) |
头疼 | [0.2, 0.1] | 0.336 * 0.2 + 0.438 * 0.1 ≈ 0.067 + 0.044 = 0.111 | 次之(例如 20%) |
开心 | [-0.5, 0.8] | 0.336*(-0.5) + 0.438 * 0.8 ≈ -0.168 + 0.350 = 0.182 | 较低(例如 15%) |
最终模型选择最高概率的 “肚子疼” 作为下一个 token。
注意在实际场景中, 预测的下一个token是不确定的, 是因为有一个掷骰子的操作, 大模型会在概率最大的几个token中随机挑选一个作为最终输出。
三、Prompt (提示词)
对于这个词大家并不陌生. 我们用chatGPT时经常会用到, "你是一个......."
但你真的理解它吗?
与ai对话时的这种预设角色, 其实并不是严格意义上的 prompt
为什么这么说呢? 先看一下API
四、理解API
我们前面提到过大语言模型的 本质就是文字接龙 , 相对应的使用大模型也比较简单. 可以参见deepseek的文字接龙 api 请求:
https://api-docs.deepseek.com/zh-cn/api/create-chat-completion

这里比较重要的几个部分, 需要理解:
1. temperature 温度
Temperature(温度) 是一个控制生成文本随机性和多样性的关键参数。它通过调整模型输出的概率分布,直接影响生成内容的“保守”或“冒险”程度. 看几个典型场景:
场景 | 温度 |
代码生成/数学解题 | 0 |
数据抽取/分析 | 1 |
通用对话 | 1.3 |
翻译 | 1.3 |
创意类写作/诗歌创作 | 1.5 |
2. tools 工具支持
大模型对 function calling 的支持, 后面再详细介绍。
3. 角色和信息
这一部分是ai对话的主体. 其中role 定义了四个角色:
- system 系统设定
- user 用户回复
- assistant 模型回答
- tool 是配合function call工作的角色, 可以调用外部工具
回到前一章的问题, ai对话时其实是user部分输入的内容, 所以system角色的设定内容才应该是严格意义上的Prompt。
这有啥区别呢? (user 与 system?)
个人一个合理的猜测: system的内容在Transformer推理中拥有较高的权重,所以拥有较高的响应优先级。
4. 关于多轮对话
因为LLM是无状态的. 我们要时刻记得文字接龙的游戏, 因此在实际操作中也是这样的:
(1) 在第一轮请求时,传递给 API 的 messages 为

(2) 大模型回答

(3) 当用户发起第二轮问题时, 请求变成了这样

五、Function Calling (函数调用)
仅仅一个可以回答问题的机器人, 作用并不太大。
要完成复杂的任务, 就需要大模型的输出是稳定的, 而且是可编程的。
因此OpenAI 推出了 function calling的支持. 也就是前面提到的 tools参数相关内容。
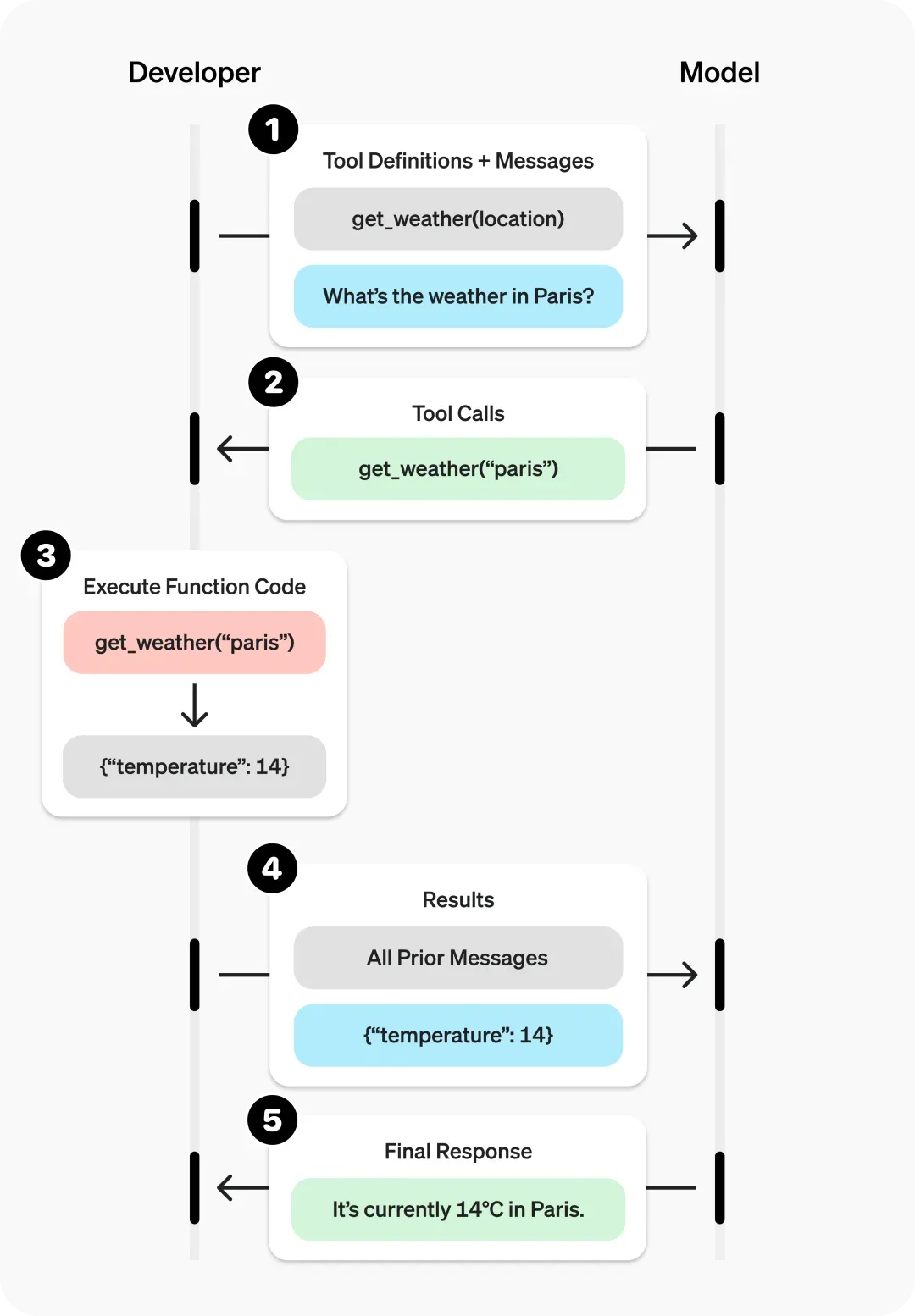
1. 基本流程
(1) 工具声明及用户输入

(2) 模型检测到需要使用工具, 返回相关工具参数

(3) 开发者根据方法名和参数, 调用相关工具方法

(4) 将工具方法的返回值, 附加到请求中, 再次请求大模型

(5) 得出最终结果
复制"The current temperature in Paris is 14°C (57.2°F)."
(6) 总结一下
2. 实现原理(猜测)
(1) 实现方式一: prompt 遵循 (示例)
提前设置规则:

(2) 实现方式二: 模型训练特定优化
对结构化输出有特定要求, 可能需要特定训练吧. 这个不太确定?
六、Agent (智能体)
包含: 大模型, 任务规划, 上下文记忆, 工具调用. 它是大模型能力的拓展. 其实只要对API进行简单的封装, 只要能完成特定任务, 都可以称为智能体. 比如下面的例子:
1. 创建AI客服系统

这个智能体, 主要包括:
- 配置了一个 prompt: "你是一个电商客服, 可查询订单状态"
- 引入 query_order 工具
2. 其它创建方式
服务商开放接口, 供用户创建, 比如腾讯元器:https://yuanqi.tencent.com/my-creation/agent
一个简单的提示词都可以创建智能体:
七、MCP (模型上下文协议)
通过上面的智能体调用工具的示例我们可以看到, 每接入一个工具, 都需要编写相应的接入代码. 经常写代码的我们都知道, 这不是好的架构设计. 好的设计应该把动态改变的部分 ( tools的声名和调用分离出来 ), 做为一个独立的模块来拓展. 这就有了大众追捧的 MCP: -----(哪有这么玄, 都是程序员的常规操作啊....)
MCP是工具接入的标准化协议:https://modelcontextprotocol.io/introduction
遵循这套协议, 可以实现工具与Agent的解耦. 你的Agent 接入MCP协议的client sdk后. 接入工具不再需要编写工具调用代码, 只需要注册 MCP Server就可以了. 而MCP Server可由各个服务商独立提供.
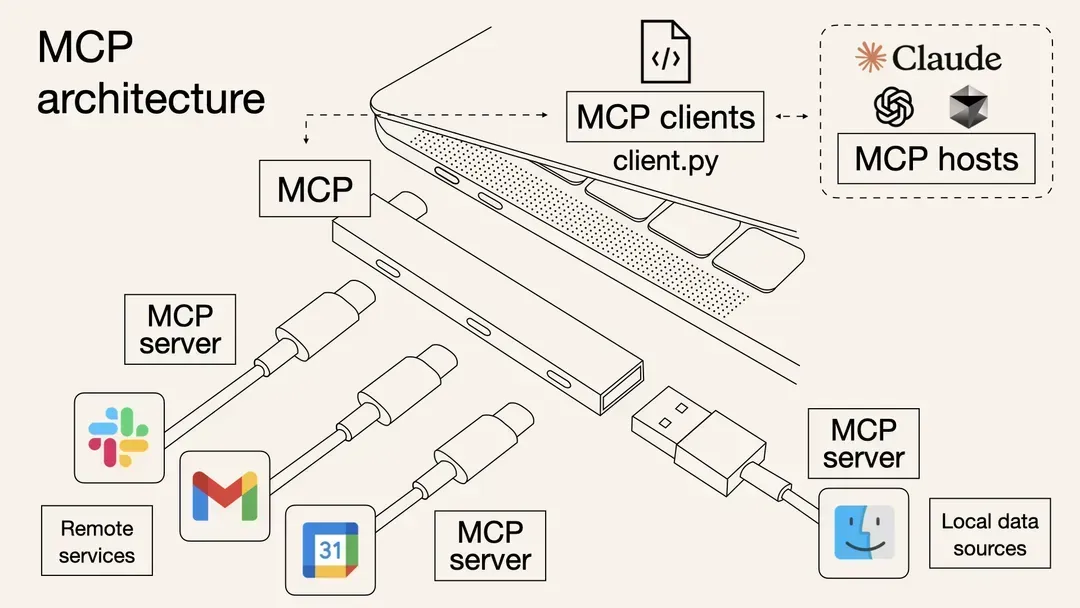
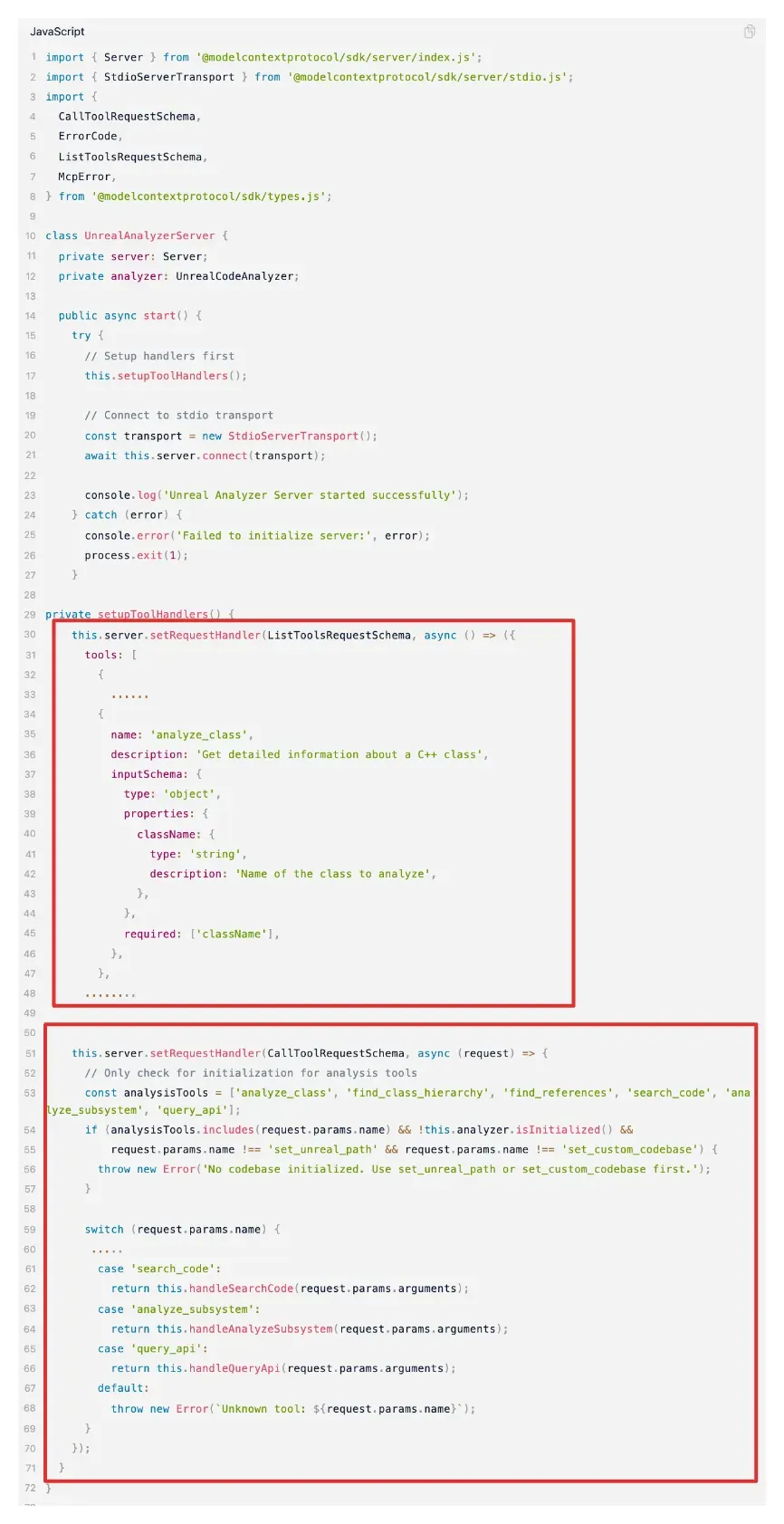
MCP Server做什么呢?
- 声明提供的能力 ListTools
- 调用能力的方式 CallTool
来看一下MCP Server的部分代码 (红框中就是做上面两个事, 不难理解) :
八、A2A (Agent通信协议)
A2A本质是对 MCP协议的拓展, 按字面意思就是 Agent to Agent. 有兴趣的自己详细看吧。
智能体与智能体之间通信的标准化协议:https://github.com/google/A2A?tab=readme-ov-file#agent2agent-a2a-protocol
在这套协议下, 一个智能体要引入其它的智能体的能力, 也变得可插拔了。
九、未来假想
如同蒸汽机, 电, 计算机这些伟大的技术一样. AI会成为下一个彻底改变人类生活工作方式的新技术.
1. 现在AI编程能力越来越强, 程序员是不是要失业了?
职业不会消失, 消失的只有人. 但是AI编程的确会重塑整个行业。
我预想几年后, 纯粹的业务代码工程师可能会消失. 而会增加更多的AI编程工程师。
AI编程工程师的职责是解决AI模糊性的问题. 而工具的引入就是增加确定性的手段。
我们程序员可以把自己的积累通过 mcp server的方式, 挂载到项目agent 上去. 这样我们就可以解放双手, 去解决更多有挑战性的问题。
2. 当前我们有哪些工作可以由AI来处理?
理论上一切重复性的工作都可以交由AI完成. 保险起见, 创造性的工作暂时可以只作为参考:
- 日常的反馈分析.
- 团队知识库
- 个人知识库


