你有没有想过,什么时候一个国产开源模型能在编程领域真正"碾压"GPT-5?
这个问题的答案,快手给出了。
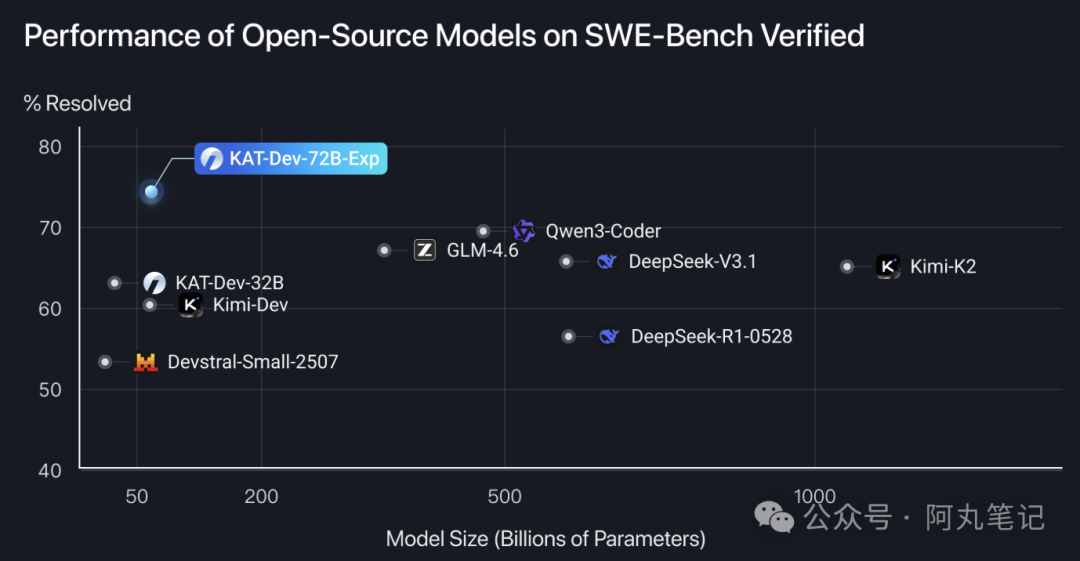
昨天看到快手开源KAT-Dev-72B-Exp的消息时,我第一反应是——这数据是不是搞错了?74.6%的SWE-Bench解决率,不仅是开源模型第一,甚至超过了GPT-5的72.8%和Claude 4 Sonnet的67.2%。
一个720亿参数的开源模型,居然在最权威的软件工程基准测试中击败了那些闭源巨头?
不只是参数大,更是训练方法的革命
说实话,720亿参数的模型并不稀奇,但KAT-Dev-72B-Exp的厉害之处在于它背后的训练方法。
快手团队没有走传统的"堆数据、堆算力"路线,而是专门针对软件工程任务设计了一套大规模强化学习训练流程。这个模型经历了中期训练、监督微调和强化微调等多个阶段,特别是在大规模Agentic强化学习阶段,模型通过与可执行环境和可验证测试用例的交互,学会了真正"理解"代码,而不只是"生成"代码。
更有意思的是,为了解决传统强化学习框架的瓶颈,快手还自研了一个叫SeamlessFlow的工业级强化学习框架。这个框架有多厉害?在32张H800 GPU上的训练任务中,相比主流框架实现了100%的吞吐量提升和62%的训练时间减少。
这意味着什么?同样的算力成本,快手能训练出更强的模型。
从《水果忍者》到太阳系模拟,这才是真正的编程能力
看数据很震撼,但更震撼的是实际能力展示。
根据快手的演示,KAT-Dev-72B-Exp能够复刻出像《水果忍者》这样包含完整计分和生命值系统的游戏,也能生成遵循真实物理规律的建筑物爆破过程动画和太阳系运行模拟。
这不是简单的代码补全,而是真正理解需求、设计架构、实现功能的完整编程能力。模型的能力覆盖了功能实现、Bug修复、性能优化、测试用例生成等八大编程场景,并且支持多种主流编程语言。
我特意去看了看他们的技术细节,发现快手还引入了一个叫"Trie Packing"的机制。这个机制通过合并共享前缀的计算,将训练速度平均提升了2.5倍。同时采用熵感知的优势缩放方法,让模型在训练中更好地平衡探索与利用。
这些技术细节听起来很复杂,但本质上就是一个目标:让AI真正学会编程,而不是背诵代码片段。
开源筑基,闭源变现的双轨战略
说到这里,你可能会好奇:快手为什么要开源这么强的模型?
我觉得这背后体现的是快手"开源筑基 + 闭源变现"的双轨战略。通过开源高性能模型抢占开发者生态,构建技术影响力,同时通过闭源版本KAT-Coder瞄准企业级市场。
这个策略挺聪明的。开源版本让所有开发者都能体验到快手AI的强大能力,建立品牌认知和技术信任。而对于有更高需求的企业用户,闭源版本提供更全面的服务和支持。
目前KAT-Dev-72B-Exp已经在Hugging Face上开源,你可以直接下载使用。如果想体验闭源版本,可以通过StreamLake平台申请KAT-Coder API试用。
技术突破背后的思考
不过,业界对这个成绩也有一些讨论。有观点认为,基准测试的高分与实际编码效率的关联性还需要更多第三方验证。毕竟,能在测试中解决74.6%的问题,和在真实项目中帮助程序员提升效率,可能还是两回事。
另外,虽然开源版本免费,但闭源版本的商业定价对个人开发者的可及性也是个关注点。毕竟,如果定价太高,可能会限制技术的普及。
但不管怎么说,快手这次的技术突破还是很有意义的。特别是在大规模Agentic强化学习训练技术上的实践与分享,为整个行业提供了新的思路和借鉴。
更重要的是,这证明了国产AI在编程领域已经具备了与国际巨头正面竞争的实力。从跟跑到并跑,再到某些细分领域的领跑,这个过程比我们想象的要快。
总的来说,KAT-Dev-72B-Exp的发布不仅刷新了开源编程模型的性能纪录,更重要的是展示了一种全新的AI训练范式。如果你对编程AI感兴趣,建议去体验一下,看看这个"开源新王者"到底有多强。


