AI在线从月之暗面 Kimi 公众号获悉,Kimi 的第一个 Agent(智能体)Kimi-Researcher 于 20 日开启小范围灰度测试。

Kimi-Researcher 是基于端到端自主强化学习(end-to-end agentic RL)技术训练的新一代 Agent 模型,也是一个专为深度研究任务而生的 Agent 产品。其后,月之暗面也将逐步开源 Kimi-Researcher 基础预训练模型及强化学习后的模型。
对于每一个问题,Kimi-Researcher 都会自主规划任务执行流程,最终交付完整结果:
澄清问题(clarification):理解问题时主动反问,构建更清晰的问题空间;
深入思考:每个任务平均进行 23 步推理,自主梳理并解决需求;
主动搜索:每个任务,平均规划 74 个关键词,找到 206 个网址,由模型判断并筛选出信息质量最高的前 3.2% 内容,剔除冗余、低质信息;
调用工具,交付结果:自主调用浏览器、代码等工具,处理原始数据、自动生成分析结论,端到端完成交付。
为了保证输出的质量和信息覆盖度,Kimi-Researcher 采用异步执行方式,用更多时间逐步推理、检索和撰写内容。

用户最终将收到 2 个交付成果。
一份信息详实、可溯源的深度研究报告
报告的平均长度在万字以上;
平均引用约 26 个高质量、可溯源的信源;
所有引用都内嵌在正文中,点击即可跳转,并高亮原文,便于验证与追溯。
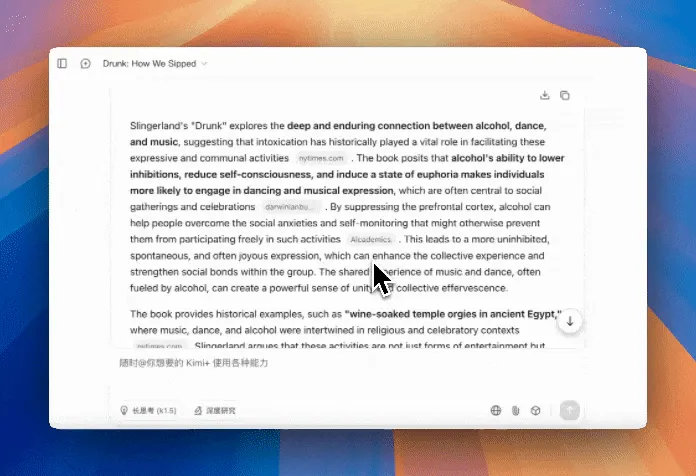
一个可交互、可分享的动态可视化报告
结构化排版、思维导图,让趋势、异常等重要信息一眼可见;
无需阅读全文,也能迅速把握整体结构与核心结论;
支持在线生成链接并分享,方便展示。

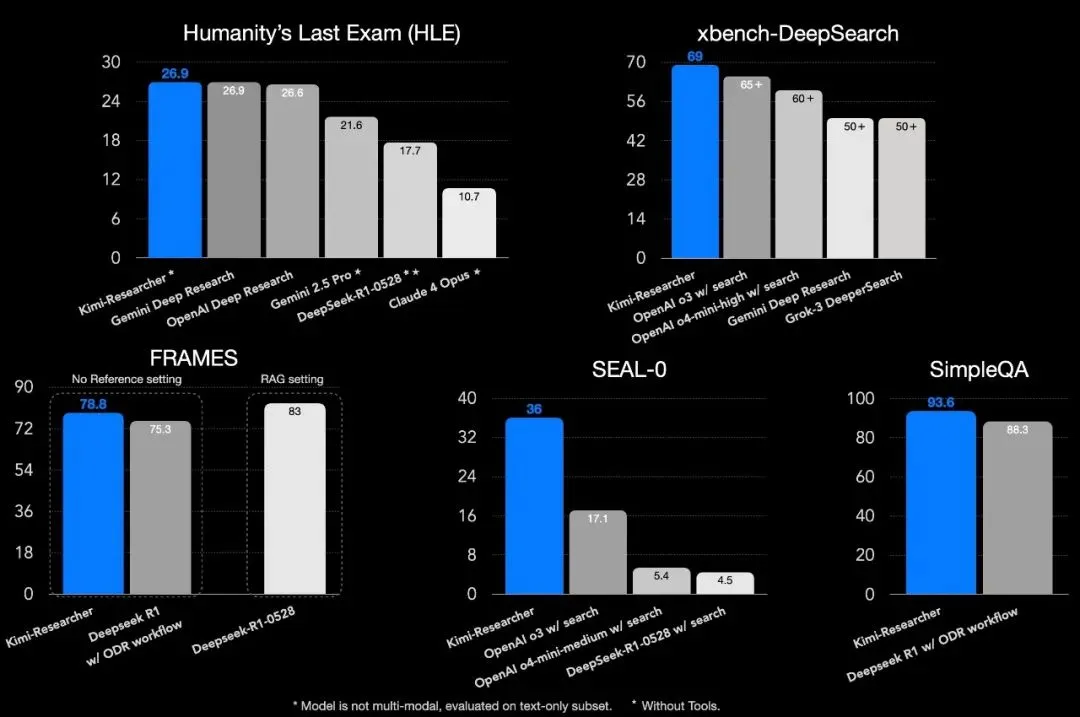
官方宣布,在专为 AI 设计的高难度 benchmark“人类最后一次考试(Humanity's Last Exam,HLE)”中,Kimi-Researcher 在完全零结构、无流程设计的设置下,得分如下:
Pass@1 准确率:26.9%
Pass@4 准确率:40.17%
这一表现超过了 Claude 4 Opus(10.7%)、Gemini 2.5 Pro(21.6%),略高于 OpenAI Deep Research(26.6%),和 Gemini-Pro 的 Deep Research Agent(26.9%)打平,是目前已知最高水平之一。在红杉中国发布的 xbench 基准测试中 —— 一套对齐真实任务场景的 AI 能力评估体系,Kimi-Researcher 在 DeepSearch 任务中取得 69% 的平均通过率,领先该榜中其他模型。