昨天,kim发布了一款“万能型”音频大模型— Kimi-Audio,支持语音识别(ASR)、音频问答(AQA)、音频字幕(AAC)、语音情感识别(SER)、声音事件/场景分类(SEC/ASC)、文本到语音(TTS)、语音转换(VC)和端到端语音对话。
换句话说,它可以听、可以说、可以理解、可以对话,支持实时语音会话,多轮交流。
 图片
图片
一套架构,横扫音频全场景,开源可用。
从学术和工业角度,我认为有两点贡献:
- 模型架构和预训练规模空前——13万小时级别的音频数据+大语言模型初始化,音频和文本信号双线处理,架构极其“融合”。
- 全链路开放+评测工具包——所有代码、模型参数、评测工具全部开源,直接对社区开放,标准化评测彻底解决“无法复现”的老大难问题。
1.模型架构:语音世界的“大一统”
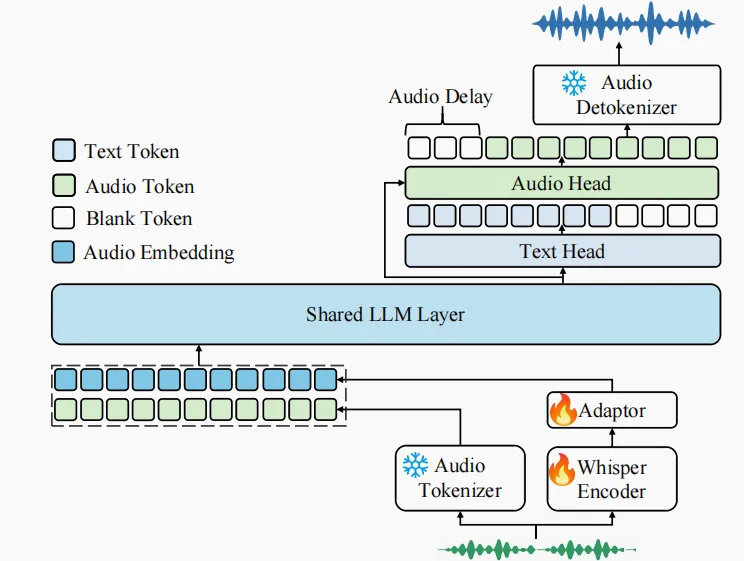 图注:Kimi-Audio技术架构
图注:Kimi-Audio技术架构
Kimi-Audio的核心架构其实就三大块:音频分词器(Tokenizer)、音频大模型(Audio LLM)以及音频反分词器(Detokenizer)。就像把一句话切成一个个字,音频分词器把声音变成一串“音频词”。Kimi用的是12.5Hz采样率(就是每秒拆12.5个“词”),既有“离散语义词”(理解内容),又有“连续声学特征”(保留音色、情感等细节)。说白了,就是既能知道你说了啥,还能尽量还原你怎么说的。
音频大模型的核心是一个“多模态大脑”,一边能处理“音频词”,一边能处理文本词;底层结构和流行的大模型(transformer那一套)一样,但上面分两头:一头专门“写字”输出文本,一头专门“说话”输出音频。这个模型底子其实是个现成的文本大模型(Qwen2.5 7B),直接“嫁接”了音频输入输出的能力,兼容性强,省了很多训练资源。
音频反分词器就是把模型输出的“音频词”重新拼成声音。“分块+流式”方案,就是把长音频切成一小块一小块,每块单独快速合成,然后拼起来,减少延迟,体验更丝滑。还做了“look-ahead”机制,就是每块合成时偷偷看一点后面的内容,让拼接更自然,不断句。
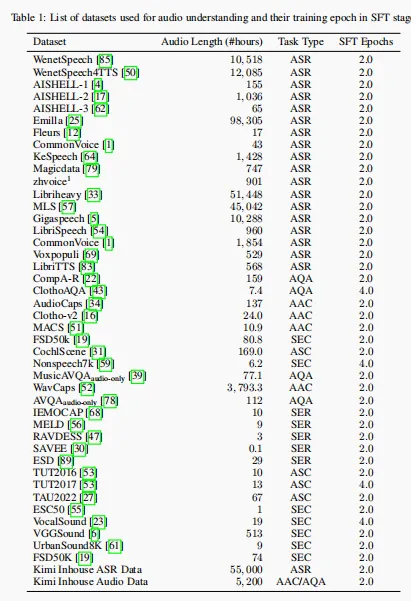
2.数据管线:1300万+小时音频,流水线级别的数据清洗
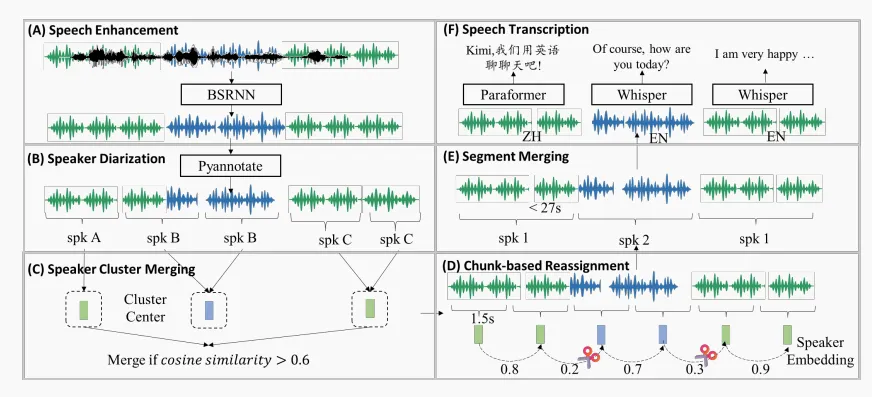 图注:数据处理流程图
图注:数据处理流程图
Kimi-Audio这波,采用的预训练音频数据高达1300万+小时,涵盖语音、音乐、环境声,各种应用场景全覆盖。
那这么多音频怎么处理?报告中说,Kimi团队搞了个自动化大流水线,从原始音频到高质量“带标注”的数据,大致分几步:
- 语音增强:先用AI降噪,把环境杂音、回声处理掉。但为了不丢失真实世界的多样性,训练时一半用原声,一半用降噪后的。
- 说话人分割(Diarization):用PyAnnote工具给每段音频“数人头”,谁说了哪段切清楚。还专门写了合并/细分/优化的后处理流程,确保每个说话段准确且长度合理。
- 转写+打标:用Whisper大模型自动识别英文,用FunASR的Paraformer-Zh识别中文,还根据时间戳智能加标点,保证后续训练能用。
据说,除了公开数据,还加了自家ASR数据,音频理解/问答数据。
 图片
图片
3.训练方式:任务多、策略细,兼容音频和文本智能
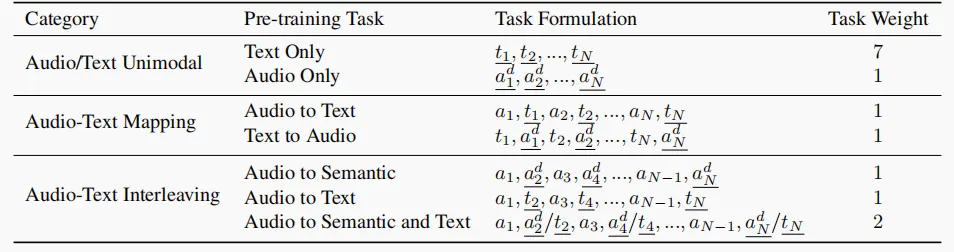
Kimi-Audio的训练分两步:万能预训练→精细指令微调。
万能预训练采用音频+文本混合学,一边学“纯文本”(用MoonLight数据),一边学“纯音频”,再加上“音频对文本”“文本对音频”的互转任务,最后还有“音频-文本交错混合”的难度提升;
精细指令微调中任务全靠“自然语言指令”分流,不用人为切换,直接靠“你说什么任务,我就做什么”,且每种任务都生成多种随机指令,训练时反复调换,模型抗干扰强。
4.各项指标“遥遥领先”
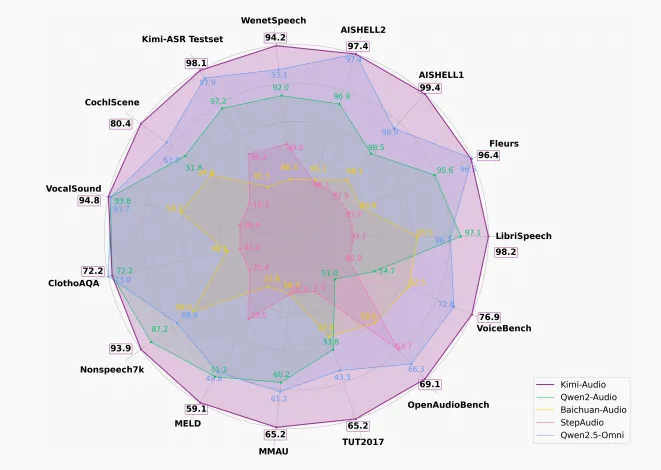 Kimi-Audio与以往音频语言模型在各类基准测试上的表现对比
Kimi-Audio与以往音频语言模型在各类基准测试上的表现对比
语音识别方面,LibriSpeech英文测试集,Kimi-Audio的错误率(WER)只有1.28%,比Qwen2.5-Omni的2.37%还低一截。AISHELL-1中文:WER 0.60%,比上一代模型低一半。此外多场景、多语种、多环境,Kimi-Audio基本都是榜首。
音频理解方面,Kimi-Audio在MMAU、MELD、VocalSound、TUT2017等公开集上,分数都是最高。比如MMAU的“声音理解”类,Kimi-Audio得分73.27,超过其它竞品。
音频对话&音频聊天方面,VoiceBench的多项任务,Kimi-Audio都是第一,平均得分76.93。
语音对话表达方面,采用人类主观打分,在速度控制、情感表达、同理心等多个维度,Kimi-Audio都能做到接近GPT-4o的效果,平均得分3.9(满分5分)。
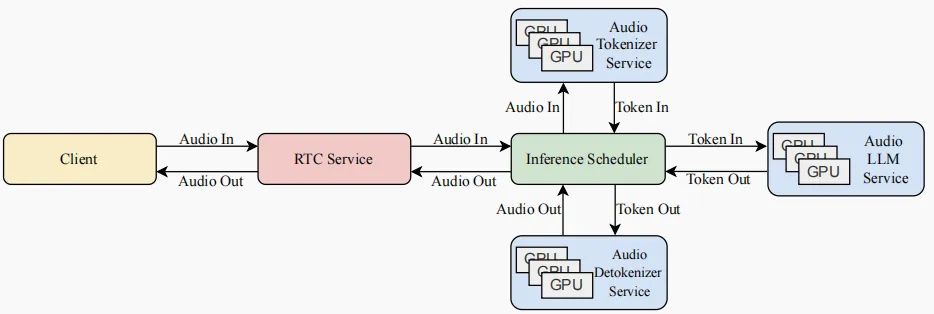
Kimi-Audio中用于实时语音到语音对话的生产部署工作流程
5.one more thing
官方也坦诚地提到,当前Kimi-Audio音频大模型还存在三大挑战:
- “转录”信息有限,描述性理解还需加强,现在模型对音频的理解,大多还停留在“你说了什么”(转写),但很多声音里“怎么说、什么情绪、什么场景”更重要。
- 音频“语义+细节”融合的表示还不够完美:纯语义Token容易丢细节,纯声学Token又缺理解,如何把“内容”和“感觉”都融在一套表达里,是下一个技术突破点。
- 无法摆脱ASR/TTS依赖:目前大部分音频大模型,底层还是靠ASR(语音识别)和TTS(语音合成)撑着,实际上就是在拼装已有的技术。
论文地址:github.com/MoonshotAI/Kimi-Audio/blob/master/assets/kimia_report.pdf
模型地址:huggingface.co/moonshotai/Kimi-Audio-7B-Instruct
repo地址:github.com/MoonshotAI/Kimi-Audio


