论文信息:
-论文标题:SpatialViz-Bench: An MLLM Benchmark for Spatial Visualization
-论文链接:https://arxiv.org/abs/2507.0761
作者介绍:本文是由中科院自动化所张海峰教授团队和伦敦大学学院汪军教授团队合作完成。第一作者为王斯婷,现就读于中科院自动化所,研究方向是多模态大语言模型、面向物理交互的世界模型,第二作者为裴旻楠,现就读于中科院自动化所,研究方向是三维视觉算法的高性能计算,第三作者为孙罗洋,现就读于中科院自动化所,研究方向是高效大语言模型。本文的通讯作者为爱丁堡大学博士后邓程,中科院自动化所张海峰教授,伦敦大学学院汪军教授。
多模态大模型(MLLM)如今已经能“看懂”世界,但它们能像人类一样“想象”世界吗?当被问及“将这个纸盒展开是什么样子?”或“这个齿轮转动,另一个会怎样?”,模型是否真的在脑海中进行了空间构建和操纵?
“A mental model is an internal representation of external reality: that is, a way of representing reality within the mind. Such models are hypothesized to play a major role in cognition, reasoning and decision-making.”
这是维基百科对mental model的定义
长期以来,MLLM 的空间可视化(Spatial Visualization)能力——即在心中构想和操作视觉图像的能力——在很大程度上被忽视了。现有的评测基准大多依赖于网上的 IQ 测试题或数学竞赛题,这不仅存在严重的“数据污染”风险,也无法系统性地诊断模型究竟在哪个环节出了问题。
为了解决这一难题,一项新研究推出了 SpatialViz-Bench,这是首个基于认知科学、并采用“程序化生成”方法构建的空间可视化综合基准。
这项评测覆盖了 27 个主流 MLLM。结果是残酷的:即便是最强的 Gemini-2.5-pro,其准确率也仅有 44.66%,与人类的 82.46% 相去甚远。研究还揭示了一个反直觉的现象:被广泛用于提升性能的 CoT(思维链)提示,在许多开源模型上反而导致了性能严重下降。
图1展示了空间可视化的两个阶段(感知可见线索Þ推理不可见关系);左下方雷达图显示了 SOTA 模型与人类(Human)之间的巨大性能鸿沟;右下方表格对比了与其他基准的任务覆盖范围。
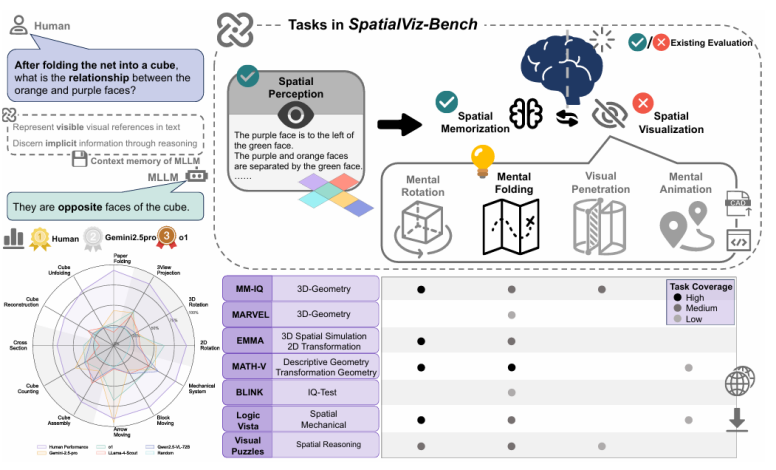
图1:SpatialViz-Bench概览。
一、 MLLM 的“阿喀琉斯之踵”:能感知,难想象
目前,大多数多模态基准(如 VQA)主要评估 MLLM 对可见信息的推理能力。例如,图片中有什么?它们在什么位置?
但在现实世界的复杂任务中,比如建筑设计、外科手术辅助或机器人操作,仅仅“感知”是远远不够的,更需要“想象”。人类可以轻松地在脑海中旋转三维物体、展开折叠的纸张、或预测机械系统的运动,而这正是 MLLM 的能力盲区。
更糟糕的是,我们甚至没有好的工具来衡量这种能力。现有的评测存在两大“原罪”:
1.数据污染风险高: 许多题目来源于公开的 IQ 测试、行政考试和数学竞赛。这些数据很可能已经存在于 MLLM 的预训练数据中,导致评测结果虚高,无法反映模型真实的推理能力。
2.评估体系混乱: 空间可视化任务常常被混杂在“数学推理”或“逻辑推理”的大类下,没有被当作一个独立的核心能力来评估。这使得我们很难诊断模型失败的根源。
二、 SpatialViz-Bench:首个“空间想象力”诊断基准
为了真正“拷问” MLLM 的空间想象力,本文作者们提出了SpatialViz-Bench。它最大的特点是系统性和抗污染性。
1.基于认知科学的四大能力
SpatialViz-Bench 的设计植根于认知科学。它没有采用杂乱的题目拼凑,而是围绕空间可视化的 4 项核心子能力,设计了 12 项针对性任务:
心理旋转 (Mental Rotation): 如 2D/3D 物体旋转、三视图投影。
心理折叠 (Mental Folding): 如纸张折叠、方块展开与重建。
视觉穿透 (Visual Penetration): 如横截面识别、方块计数、组件拼装。
心理动画 (Mental Animation): 如箭头运动、机械系统、带重力的方块移动。

图2:SpatialViz-Bench 包含 12 项任务,覆盖空间可视化的四大核心能力。
2.程序化生成:从源头杜绝“数据污染”
在 12 项任务中,有 11 项是完全程序化生成的。作者使用FreeCAD编写算法,可以源源不断地生成全新的、结构上不同但难度一致的测试题。
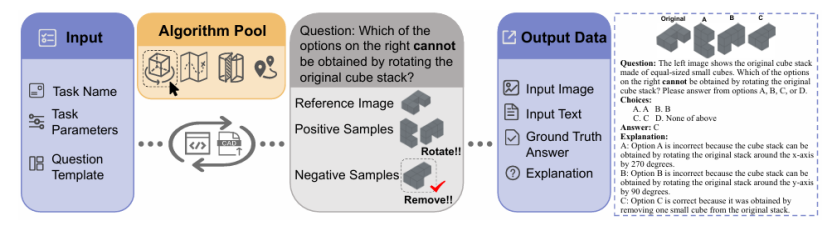
图3:程序化生成管线示意图。
该系统可以自动生成参考图像、正例、负例(干扰项)以及详细的解释。
这种动态生成题目的方法为模型评测带来了三大核心优势:首先,它实现了高可扩展性,能够轻松扩展题库,源源不断地生成上千道全新的题目。其次,由于题库是动态实时更新的,模型无法通过“刷题”或“记忆”来获得高分,从而从根本上保证了评测的长期公平性与可靠性,即抗污染性。最后,这种程序化生成机制赋予了我们可诊断性,能够精确控制任务难度,并系统性地生成具有特定误导性的“干扰项”,这极大地帮助研究人员深入分析模型的错误模式和能力边界。
三、 残酷的真相:SOTA MLLM 集体“翻车”
研究团队在 SpatialViz-Bench 上对 27 个主流 MLLM 进行了零样本(zero-shot)评测。评测结果(如图1雷达图所示)揭示了一个显著的性能鸿沟:目前所有 MLLM 的表现都远低于人类基线(82.46%)。在这一竞赛中,闭源模型处于领跑地位,其中表现最好的是 Gemini-2.5-pro (44.66%) 和 o1 (41.36%)。然而,开源模型与其差距明显,例如表现最佳的开源模型——Qwen2.5-VL-72B-Instruct (35.00%) 和 LLaMA-4-Scout (34.24%)——与顶级的闭源模型仍存在约 10% 的巨大差距(详见表1)。更进一步分析,需要模型进行真正“想象”的核心 3D 任务,例如 3D 旋转、方块展开与重建,成为了名副其实的“重灾区”。在这些任务上,模型的准确率普遍接近随机猜测(25% 左右)。这强有力地表明,尽管 MLLM 在处理 2D 图像方面表现出色,但它们在构建和操作 3D 心理表征方面存在严重的、亟待解决的缺陷。
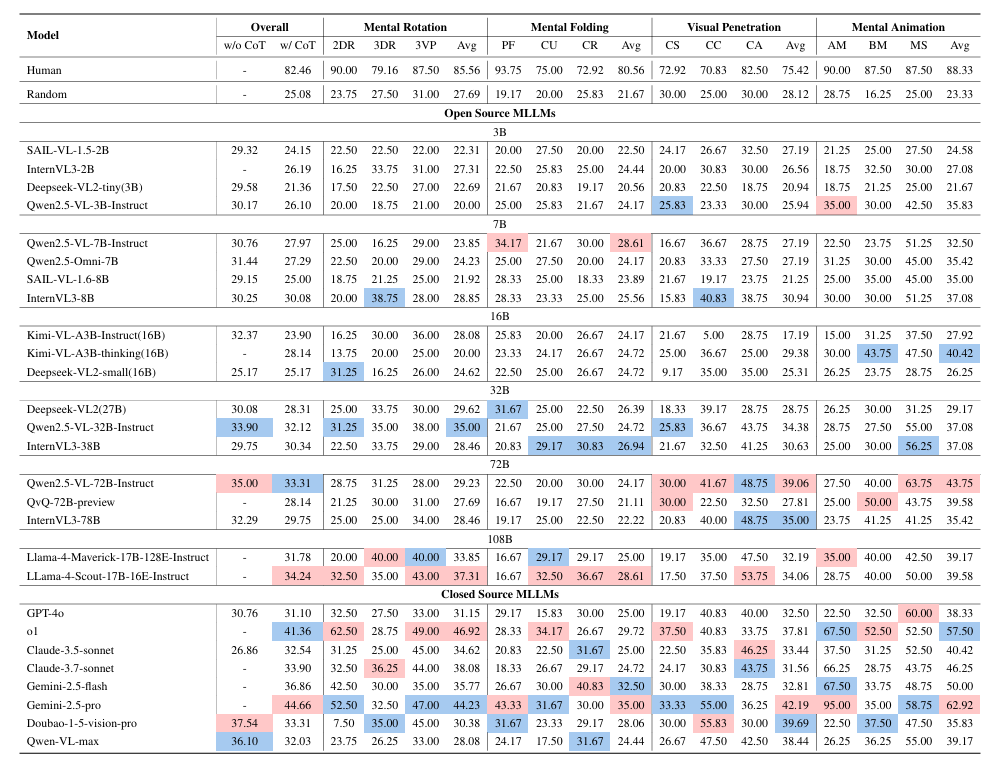
表1:主要模型在 SpatialViz-Bench 上的性能对比
四、 两大反直觉发现:CoT 悖论与“大力未必出奇迹”
在评测中,本文作者发现了两个非常有趣的现象。
发现一:CoT 思维链悖论 —— 提示越多,错得越多?
在 LLM 领域,CoT(思维链)提示通常被认为是提升复杂推理任务性能的“万金油”。但在这项研究中,CoT 却成了“毒药”。
作者对比了“直接回答(Direct Answering)”和“CoT”两种提示模式。结果发现,CoT 提示虽然帮助了 GPT-4o和 Claude-3.5-sonnet 等闭源模型,但却让许多开源 MLLM 的性能大幅下降。例如,Kimi-VL-A3B-Instruct 模型在 CoT 模式下,准确率暴跌了近 10%。
这是为什么? 作者推测: 对于那些没有专门针对“长篇视觉推理”进行微调的模型,强制它们生成一步步的解释性文本,反而会干扰它们固有的、可能正确的视觉直觉。换句话说,CoT 生成的文本非但没有起到辅助作用,反而成为了“噪音”和“分心源”。
发现二:错误分析 —— 瓶颈在“感知”,而非“推理”
MLLM 到底错在哪?作者对错误类型进行了详细的手动分类和统计。
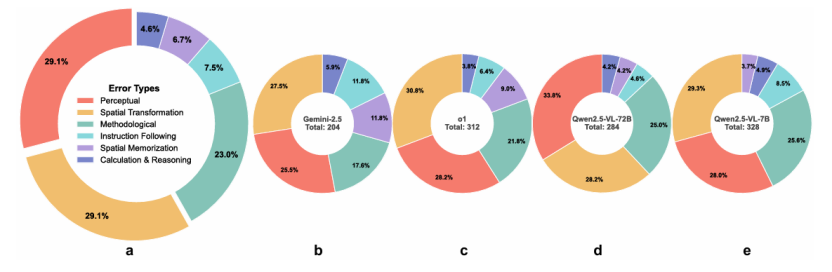
图4:错误类型分布。
总体来看(a),感知错误(Perceptual, 29.1%)和空间变换错误(Spatial Transformation, 29.1%)是最大的两个错误来源,合计占近 60%。结果令人震惊:最大的错误来源(近 60%)是“感知错误”(如没看清颜色、形状)和“空间变换错误”(如搞错旋转、折叠关系)。相比之下,高阶的“计算与推理错误”(7.5%)和“指令遵循错误”(6.2%)占比较低。这说明,MLLM 在空间可视化上的主要瓶颈,并非出在“逻辑推理”上,而是出在更基础的“视觉感知”和“空间表征”上。
更有趣的是,“大力未必出奇迹”。对比 Qwen2.5-VL-7B 和 Qwen2.5-VL-72B(图 4.e 和 4.d),参数量暴涨 10 倍后,虽然在某些错误(如空间记忆)上有所改善,但在最核心的“感知”和“空间变换”这两类错误上,其分布模式几乎一模一样。这揭示了一个残酷的现实:仅仅依靠扩大模型规模,并不能解决 MLLM 在空间推理上的根本性缺陷。
五、 案例研究:Gemini-2.5-pro 也会“抄近道”
为了探究 MLLM 的“思考”方式,作者对 Gemini-2.5-pro 进行了案例分析。

图5:Gemini-2.5-pro 的推理案例。
在(c)机械系统任务中,模型试图调用物理公式,而不是进行心理模拟。分析发现,即使是 Gemini-2.5-pro 这样的顶级模型,其抽象推理能力也远远强于其视觉空间处理能力。最典型的例子是在(图 5.c)的“机械系统”任务中。人类解决这类问题时,会在脑海中“模拟”齿轮的运动。然而,Gemini-2.5-pro 的思考过程显示,它试图默认调用理论物理公式来进行分析计算,而不是执行真正的心理模拟。
这种“捷径”揭示了 MLLM 内部世界模型的本质:它们更像是一个分析和关联知识的“分析脑”,而不是一个能真正模拟物理和空间过程的“模拟脑”。
总结:SpatialViz-Bench 作为首个基于认知科学、并采用程序化生成方法来防止数据污染的基准,为 MLLM 评估提供了一个全新的、亟需的视角。评测结果揭示了当前 MLLM 存在的巨大能力鸿沟,并准确定位了瓶颈所在:并非逻辑不行,而是基础的感知和空间变换能力存在严重缺陷。这些发现为未来 MLLM 的架构设计和训练策略指明了清晰的方向。


