在60个主流基准测试中拿下38项第一!
字节发布轻量级多模态推理模型Seed1.5-VL,仅用532M视觉编码器+200亿活跃参数就能与一众规模更大的顶尖模型掰手腕,还是能带图深度思考的那种。
相关技术报告也第一时间公开了。

整体而言,虽然是“以小博大”,但新模型在复杂谜题推理、OCR、图表理解、3D空间理解等方面表现出色。
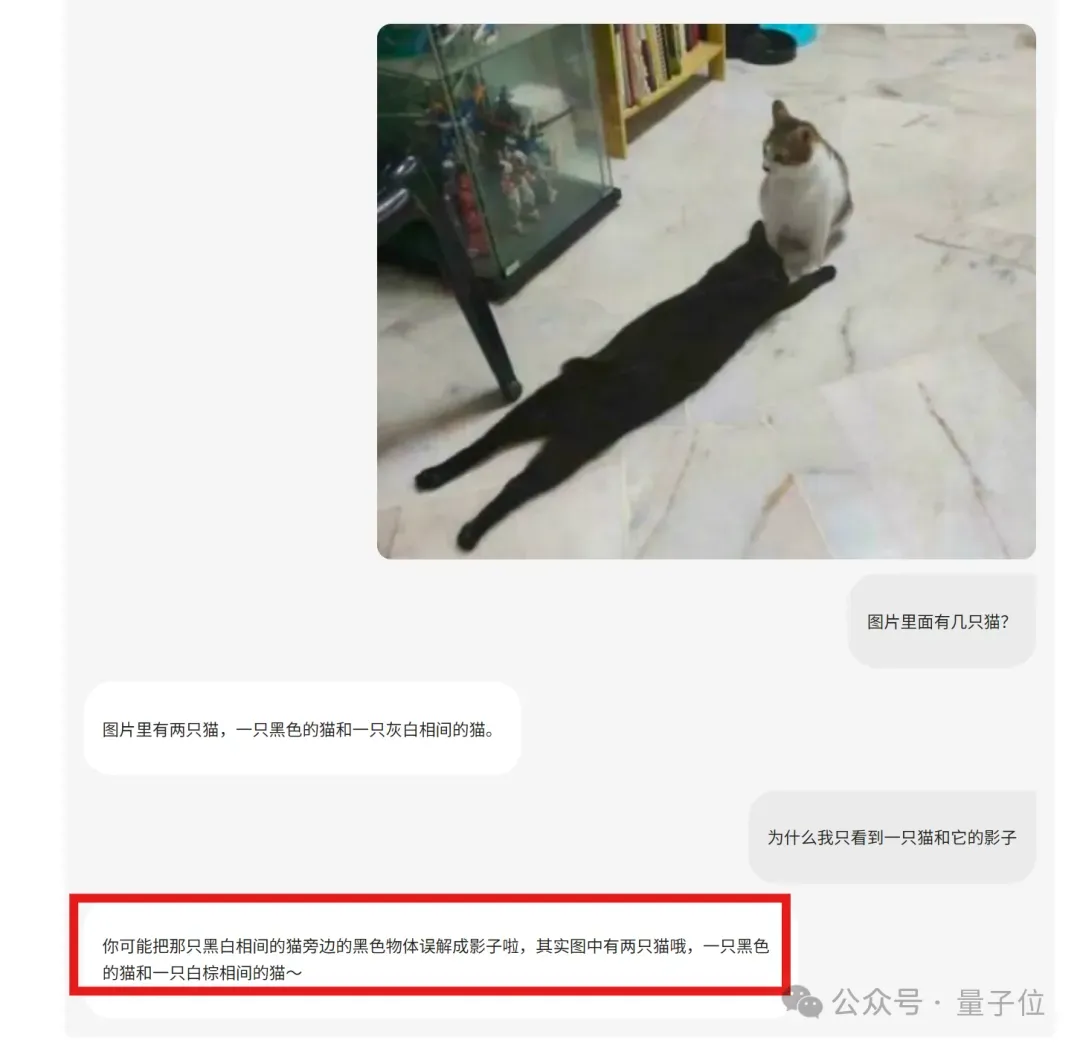
比如猜下图中有几只猫,人眼很容易误将地上的黑猫当成影子:
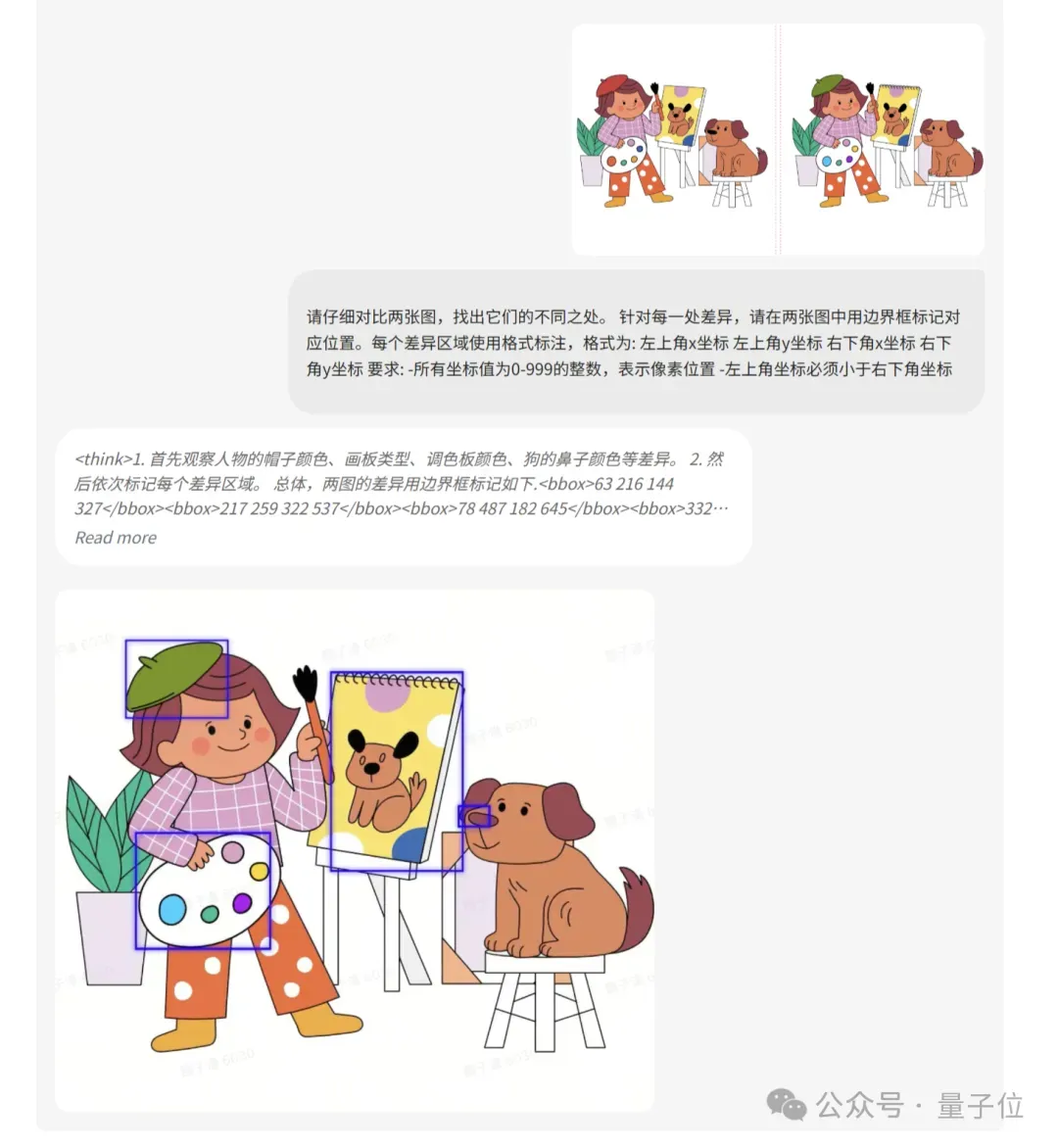
还能用来玩“看图找茬”,速度和准确率双双胜于人类:
同时也能用来解答复杂推理谜题,考公党有福了(bushi~

当然,以上也基于其强大的OCR识别能力。即便是长度惊人、中英混杂的消费小票,也能分分钟转换成表格。

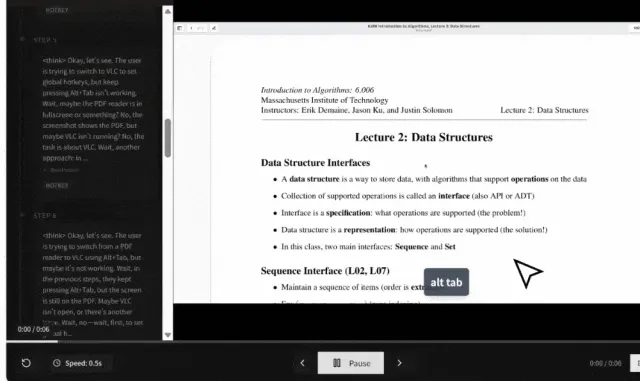
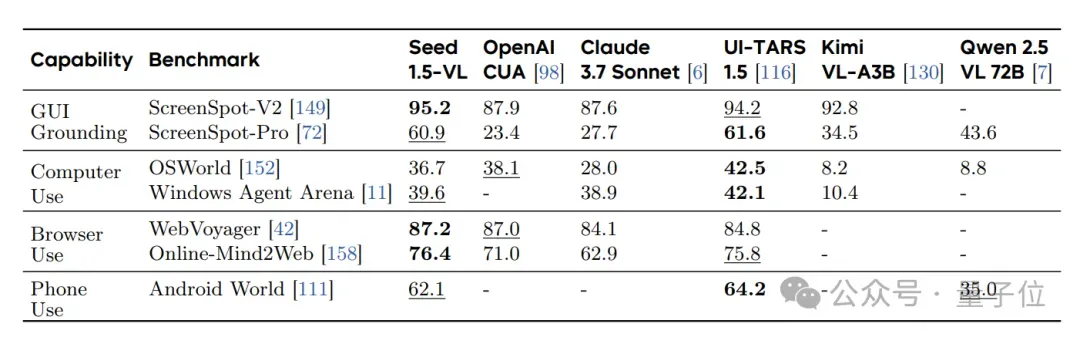
除此之外,新模型还擅长处理Agent任务。它在GUI界面操作和游戏场景中,显著优于OpenAI的CUA和Claude 3.7等模型。
那么它是如何做到的呢?
532M视觉编码器 + 20B混合专家语言模型
通过深扒技术报告,背后关键主要在于模型架构和训练细节。
据介绍,Seed1.5-VL由以下三个核心组件组成:
- SeedViT:用于对图像和视频进行编码;
- MLP适配器:将视觉特征投射为多模态token;
- 大语言模型:用于处理多模态输入并执行推理。
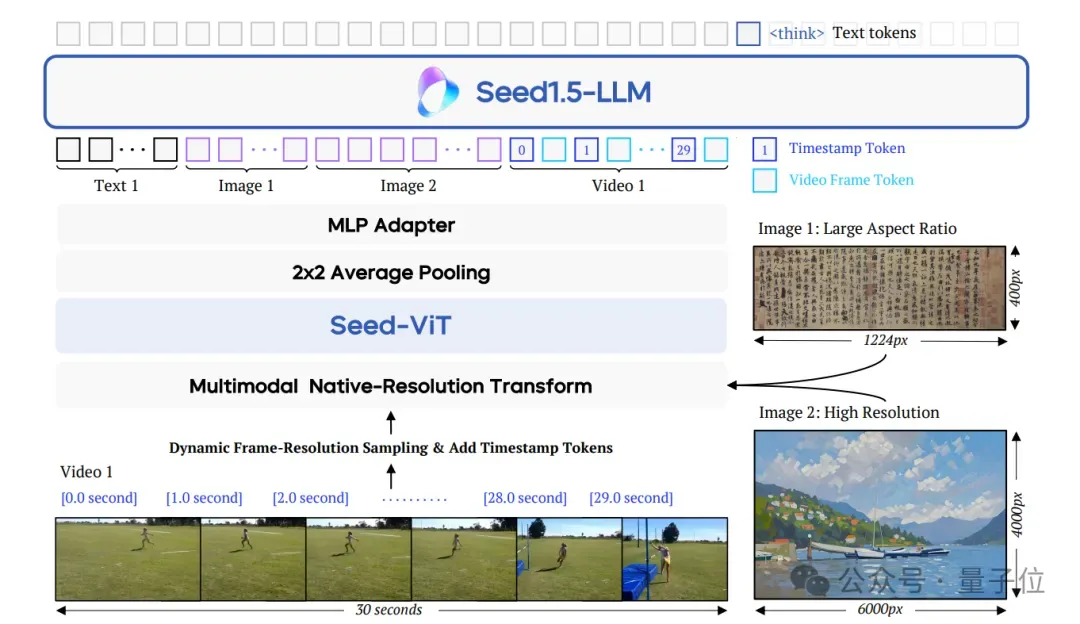
模型支持多种分辨率的图像输入,并通过原生分辨率变换(native-resolution transform)确保最大限度保留图像细节。
在视频处理方面,团队提出了一种动态帧分辨率采样策略(dynamic frame-resolution sampling strategy),能够根据需要动态调整采样帧率和分辨率。
此外,为了增强模型的时间信息感知能力,在每帧图像之前引入了时间戳标记(timestamp token)。
这些设计让模型能够高效处理各种多模态数据,包括文本、图像和视频等。
而基于上述架构,团队接着开始了模型训练。
首先,团队使用了3万亿个多样化且高质量的多模态标注,这些数据是根据模型需要发展的特定能力来组织和分类的。
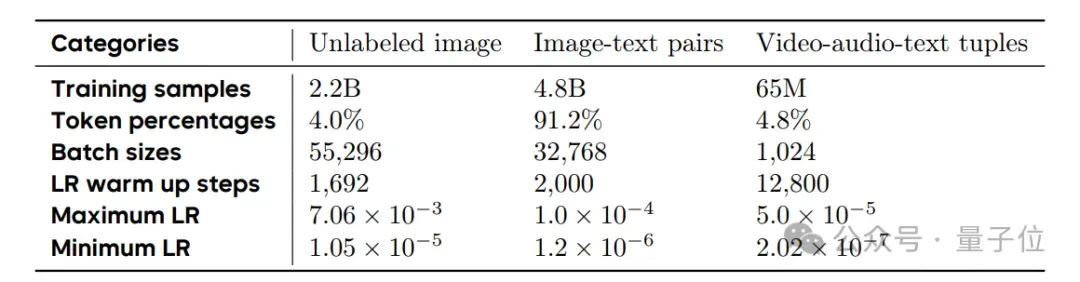
其预训练过程分为三个阶段:
- 阶段0:仅训练MLP适配器,以对齐视觉编码器和语言模型;
- 阶段1:训练所有模型参数,重点是掌握视觉定位和OCR能力;
- 阶段2:增加数据多样性,扩展序列长度,以适应视频理解和复杂推理任务。
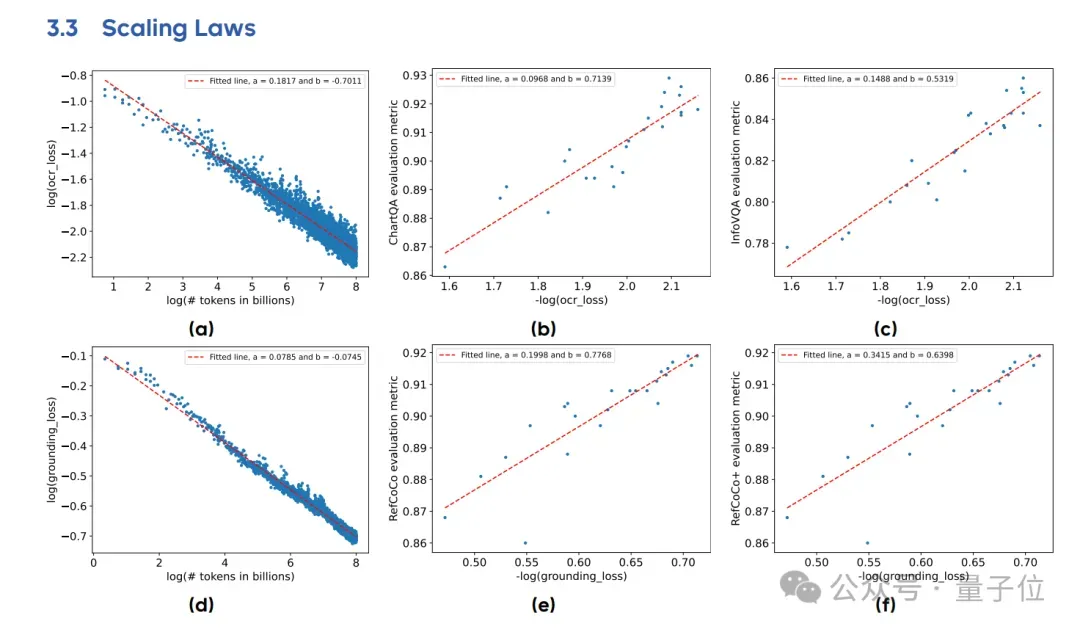
值得一提的是,团队在预训练阶段观察到了——
大多数子类别的数据训练损失与训练标记数量之间遵循幂律关系,即训练损失随着训练标记数量的增加而减少。
此外,某一子类别的训练损失与该类别对应的下游任务评估指标之间呈现对数线性关系(例如:评估指标 ∼ log(训练损失))的趋势,尤其在局部区域内尤为显著。
后者意味着,可以通过训练损失来一定程度上预测模型在下游任务上的表现。
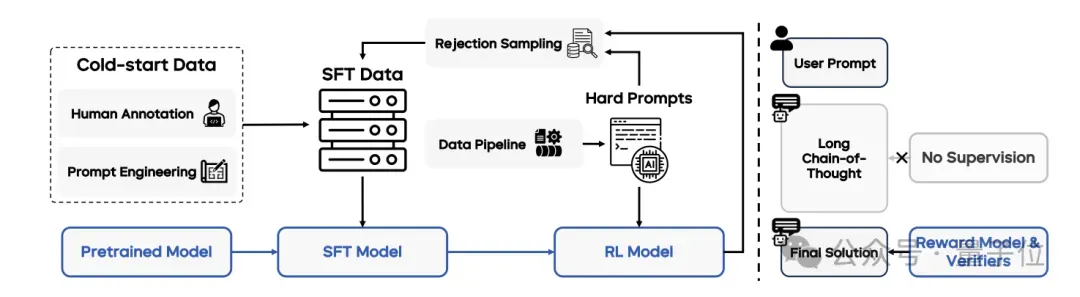
接下来团队又进行了后训练,使用了监督微调和强化学习等技术。
其一,使用高质量的指令数据对模型进行微调,包括一般指令和长链推理(Long CoT)数据;
其二,结合人类反馈和可验证奖励信号,通过PPO算法进行训练,以提高模型的对齐能力和推理能力。
需要注意的是,团队在后训练采用了结合拒绝采样(rejection sampling)和在线强化学习(online reinforcement learning)的迭代更新方法。
他们构建了一条完整的数据pipeline,用于收集和筛选复杂提示,以增强后训练阶段的数据质量。
并且在强化学习过程中,监督信号通过奖励模型和规则验证器(rule verifiers)仅作用于模型生成的最终输出结果。
也就是说,团队特意避免对模型的详细链式思维推理(chain-of-thought reasoning)过程进行监督。
最后,为了支持大规模预训练和后训练,团队还开发了一系列优化技术:
- 混合并行化:针对视觉编码器和语言模型的不同特点,采用不同的并行策略;
- 工作负载平衡:通过贪心算法重新分配视觉数据,平衡GPU工作负载;
- 并行感知数据加载:减少多模态数据的I/O开销;
- 容错机制:使用MegaScale框架实现容错,确保训练的稳定性。
这些技术显著提高了训练吞吐量,并降低了硬件成本。
60项测试中拿下38项SOTA
那么其实际表现如何呢?
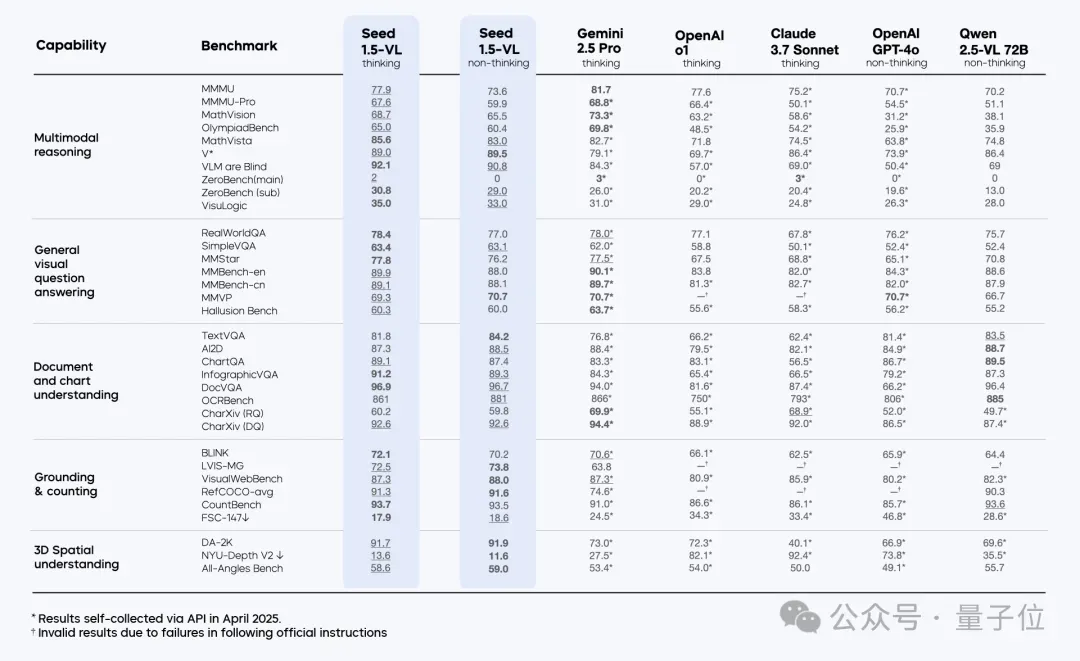
实验结果显示,新模型在60项公开基准测试中取得了38项新SOTA,其中包括19项视频基准测试中的14项,以及7项GUI智能体任务中的3项。
部分测试结果如下:
单拎出多模态智能体任务来看,它在多个GUI任务上,优于OpenAI的CUA和Claude 3.7等现有模型。
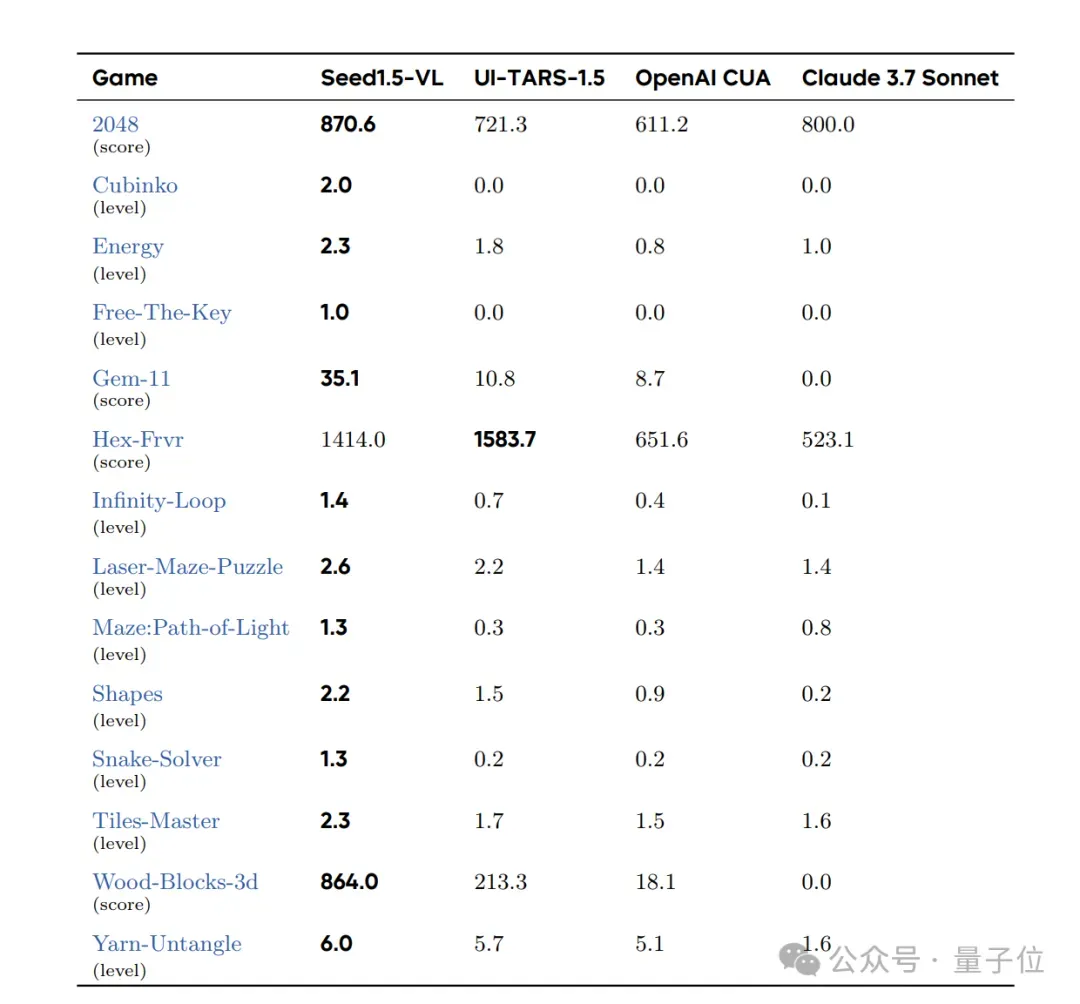
在多个游戏中,它也展现出强大的推理和决策能力。
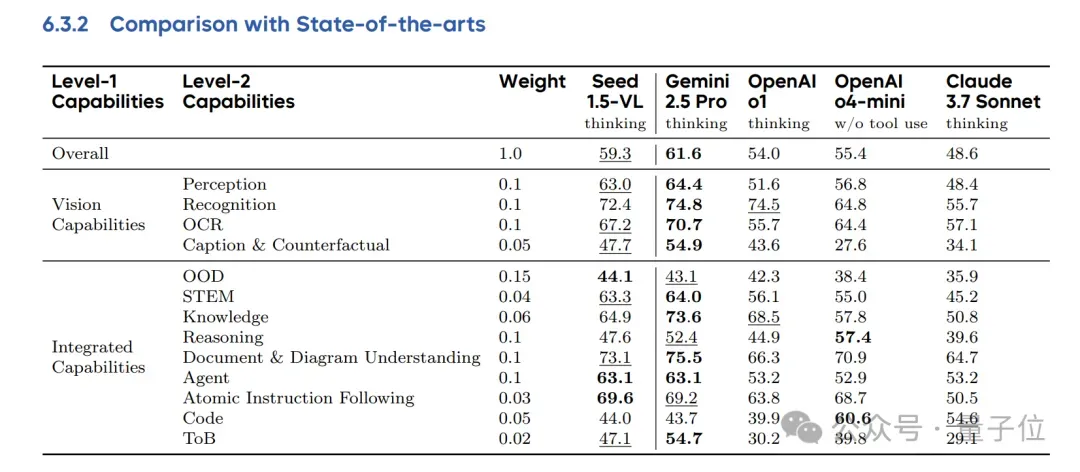
与此同时,在内部测试中,新模型尤其在视觉推理、文档理解、3D空间理解等方面表现出色。
光看测试结果可能还不够,我们最后也来简单实测一下。
比如玩最近很火的“看图找地理位置”,随意一张游客照也能正确推理识别。
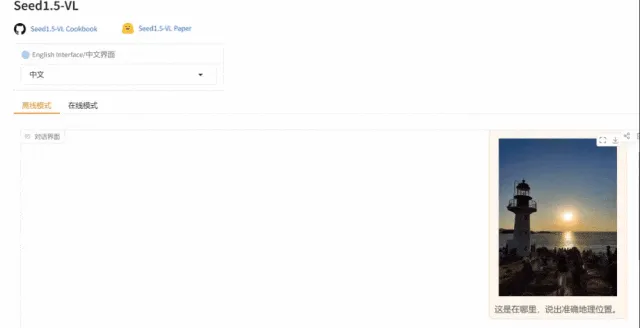
鉴于图中有灯塔这种可能容易暴露地标的元素,我们再换张难度更高的。

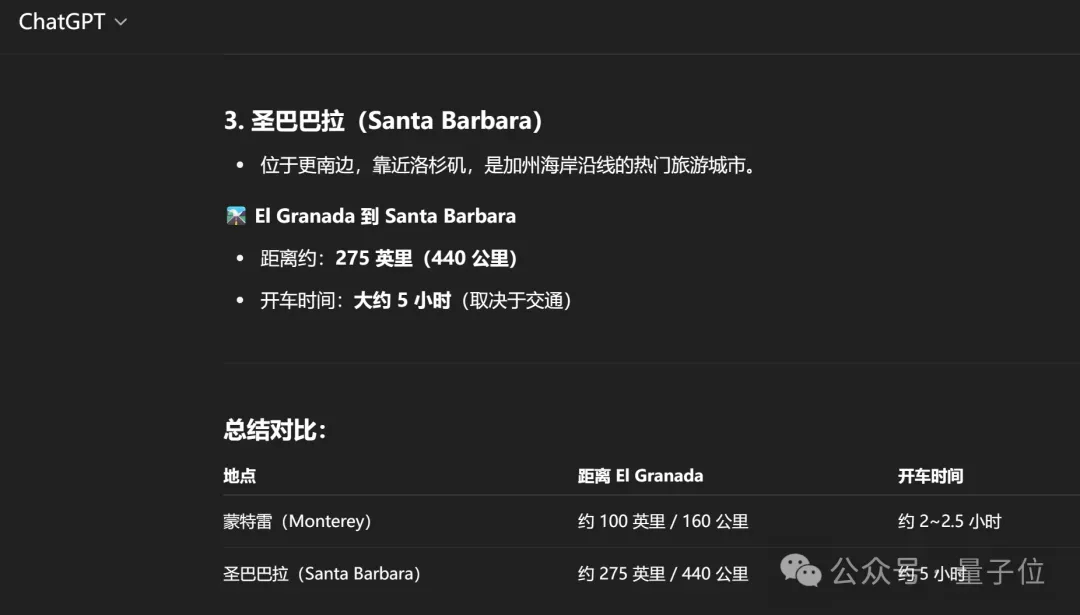
在无明显标识的情况下,o3曾因猜出的位置距离正确答案(加州埃尔格拉纳达附近的一家露天酒吧里)仅相差200-300公里而出圈。
而Seed1.5-VL最后的答案是加州沿海地区(比如蒙特雷县、圣巴巴拉周边的小镇):
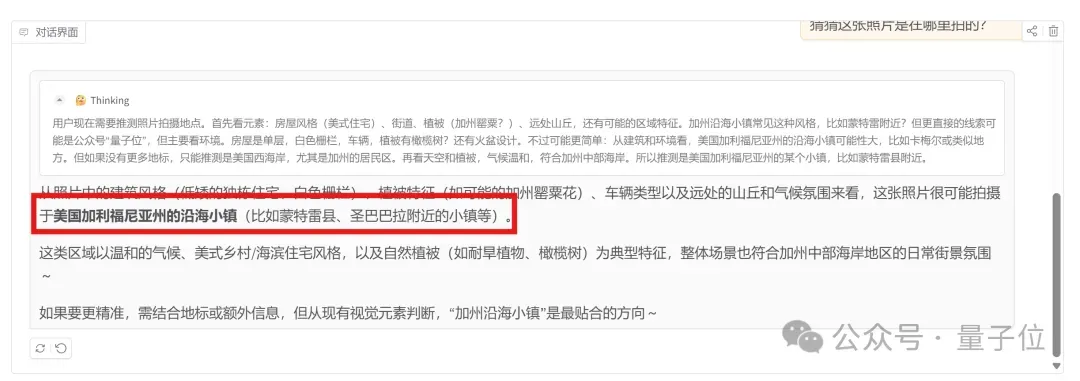
这两个地点距离正确位置分别为160公里和440公里,和o3的表现已经相当接近。
不过最后需要提醒,团队表示新模型仍存在一些局限性,尤其是在细粒度视觉感知、三维空间推理以及复杂组合搜索任务方面。
目前新模型可在Hugging Face在线体验,欢迎大家评论区分享讨论~
在线体验:https://huggingface.co/spaces/ByteDance-Seed/Seed1.5-VL论文:https://arxiv.org/abs/2505.07062GitHub:https://github.com/ByteDance-Seed/Seed1.5-VL


