AI 时代,智能体对短期对话的处理能力已不再是难题。真正的挑战是让智能体在数百步的探索中依然保持清晰的推理与稳健的决策。
传统的强化学习框架在几十步内尚能应付,但一旦任务延展至数百步,奖励稀疏、历史冗长、策略崩塌便接踵而至。
为了应对这些挑战,来自卡内基梅隆大学、香港大学等机构的研究者提出了 Verlog ,试图打破这一困境。
具体而言,Verlog 是一个多轮强化学习框架,专为具有高度可变回合(episode)长度的长时程(long-horizon) LLM-Agent 任务而设计。
它在继承 VeRL 和 BALROG 的基础上,并遵循 pytorch-a2c-ppo-acktr-gail 的成熟设计原则,引入了一系列专门优化手段,从而在任务跨度从短暂交互到数百回合时,依然能够实现稳定而高效的训练。
以往的框架(如 VeRL 和 RAGEN)能够较好地处理约 10 回合的任务,verl-agent 则可扩展至 50 回合。而 Verlog 则被设计用于超过 400 回合的环境,使其在复杂的长期决策任务中具备独特优势。
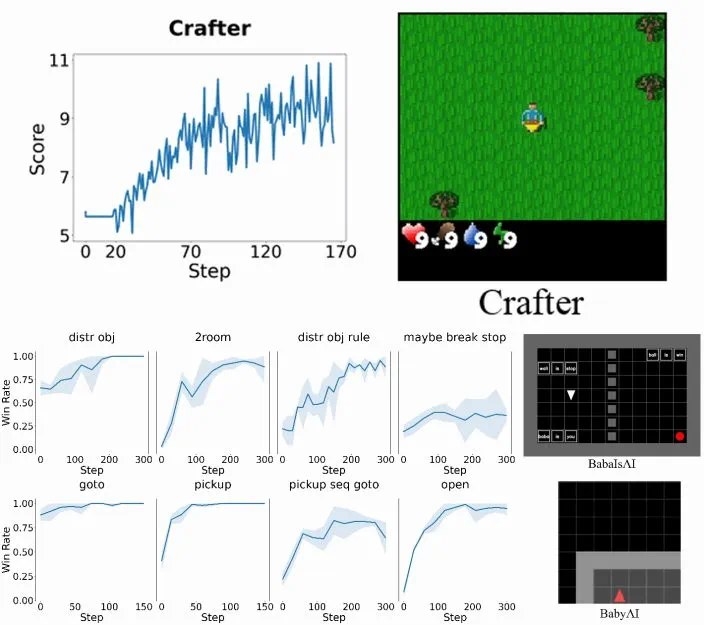
这一能力已在 BabyAI、BabaIsAI 和 Crafter 等高难度领域得到验证。以 Crafter 为例,其回合长度范围在 70 到 400 步之间,平均约为 190 步。在这些充满挑战的环境中,Verlog 都能够开箱即用地展现出强劲的性能。

博客地址:https://blog.ml.cmu.edu/2025/09/15/verlog-a-multi-turn-rl-framework-for-llm-agents/
项目主页:https://agentic-intelligence-lab.org/2025/08/15/technical-post.html
方法介绍
基础模型
在模型方面,本文基于 Qwen-2.5 的 Instruct 变体(Qwen-2.5-3B/7B-Instruct)构建。
这样做主要有两个原因:
一是,它可以与 BALROG 无缝集成(BALROG 是一个旨在评估 Instruct 模型在一系列基准测试中零样本性能的框架);
其次,它允许研究者可以直接使用基准测试提示,而无需太多修改。

BabyAI 使用的提示模板
记忆机制
本文不是将整个轨迹全部放入上下文窗口中,而是仅保留最新的 n + 1 个回合。
这样做带来的影响是,对于 3B 参数的 Qwen 模型,性能在 n = 1 或 2 时达到峰值,而当 n 增加到 4 或 8 时性能下降。
作者推测,模型性能下降的原因是 3B 模型在处理长上下文方面的能力有限,例如,当 n = 8 时,提示词长度约为 4600 个 token。
不过,这一趋势是否适用于更大规模的模型,仍待研究。
Dual Discounting GAE 算法
为了鼓励智能体在更少的环境步数内完成任务,本文将 token 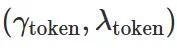 与 step
与 step 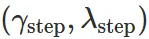 进行了解耦。并设置如下参数:
进行了解耦。并设置如下参数:
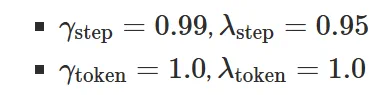
此外,本文 GAE 是递归计算的:
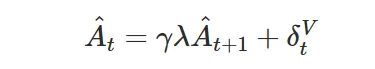
其中,

递归从最后一轮的最后一个 token 开始,向后进行。处理完最后一轮的所有 token 后,移至倒数第二轮的最后一个 token,并继续递归执行此过程。在此过程中,所有状态 token 都会被跳过。

实验结果
该研究在三个颇具挑战性的基准上测试了 Verlog:包括 Crafter、BabyAI 和 BabaIsAI。实验模型包括 Qwen2.5-Instruct 。
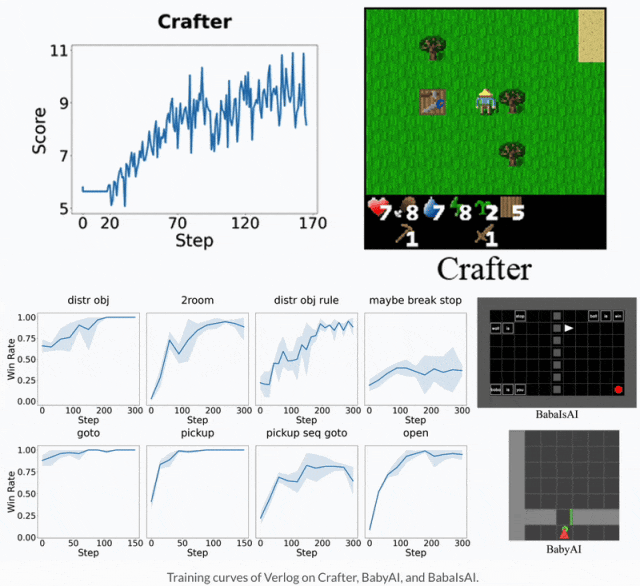
在 Crafter 环境中,本文使用 8 张 H100(82GB 显存)GPU 对 Qwen2.5-7B-Instruct 模型训练了大约 36 小时。此外,针对 BabyAI 与 BabaIsAI 环境,本文采用 4 张 A40(48GB 显存)GPU 对 Qwen2.5-3B-Instruct 模型训练约 24 小时。
三个实验环境表明,Verlog 展现出稳定的训练能力,不管是在长周期、稀疏奖励,还是在可变 episode 长度条件下。这也证明了该框架能自然适应从短周期到超长周期多回合任务的规模化训练。
总结
Verlog 针对在构建长时程、多回合任务的 LLM Agent 时面临的若干核心工程挑战,提出了系统性的解决方案,包括:
长交互历史的处理:通过记忆机制和回合级抽象来管理历史信息。
稀疏奖励下的训练稳定性:结合 dual-discounting GAE 和价值函数预训练来增强稳定性。
轨迹长度可变的管理:通过固定回合批处理(fixed-turn batching)和自举式价值估计来处理变长轨迹。
提升动作有效性:利用针对性的提示工程和默认动作替换,使训练过程中 >95% 的动作均为有效动作。
作者表示,Verlog 的定位是一个灵活的研究平台,目的是推动长时程 LLM-Agent 强化学习的发展。