o1完整版公开仅10天,Scaling Law新范式就被逆向工程复现了!
Hugging Face官方发文,开源了扩展测试时计算的方法。
用在小小小模型Llama 1B上,数学分数直接超过8倍大的模型,也超过了计算机科学博士生的平均分数(40%)。
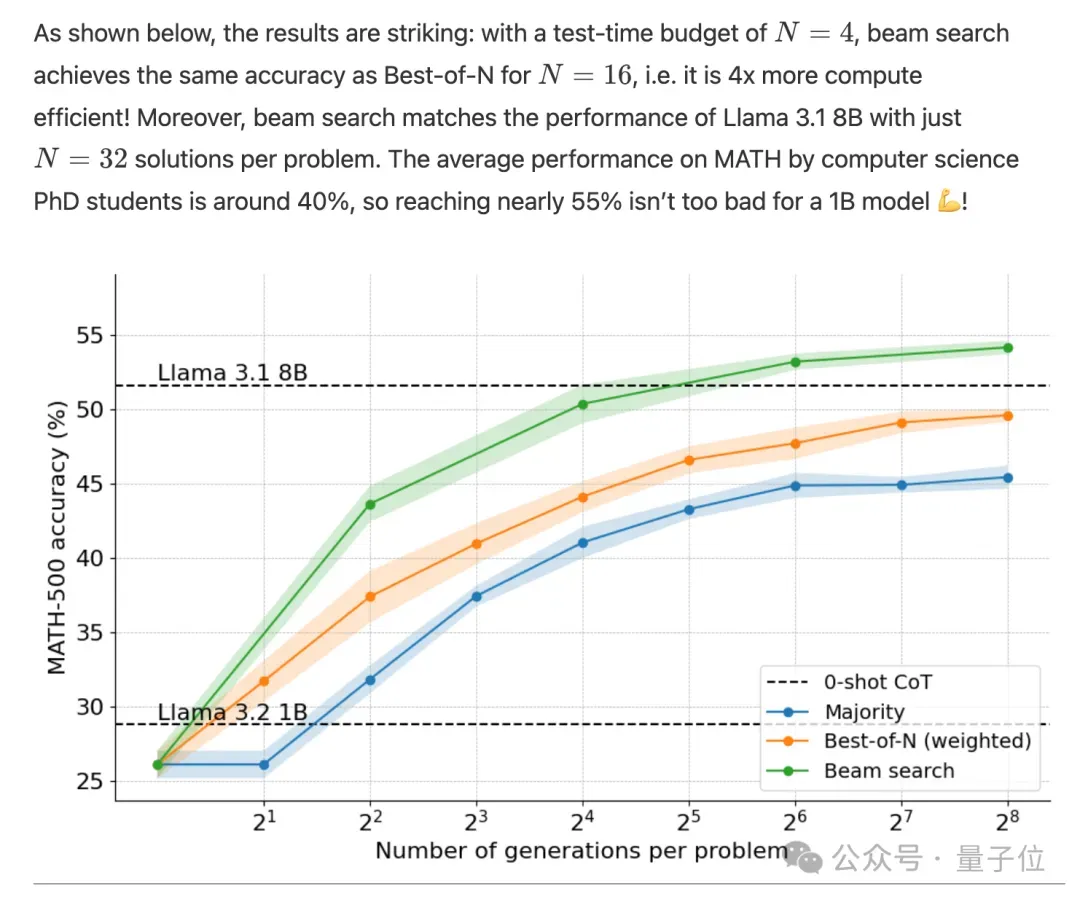
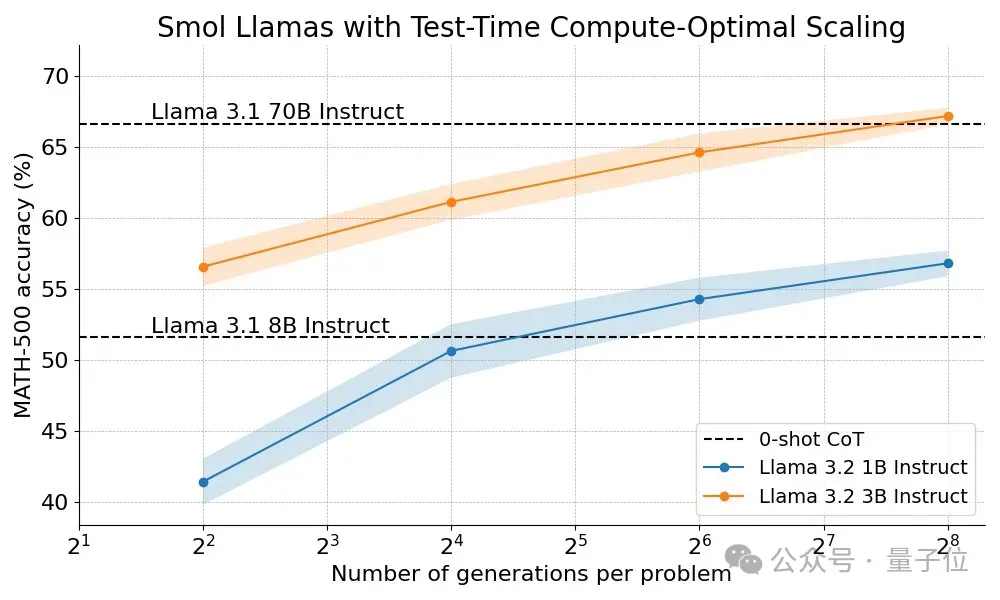
那么用在Llama 3B上呢?进步幅度更大,甚至能和20几倍大的70B模型媲美。
虽然OpenAI o1的配方完全保密,没有发布实现细节或代码,但团队基于DeepMind公布的研究结果,完成了自己的实验。

在DeepMind研究的基础上,Hugging Face团队做出如下改进:
- 多样化验证器树搜索(Diverse Verifier Tree Search),一种简单而有效的方法,可以提高多样性和更高性能,特别是在算力预算充足的情况下。
- 开源轻量级工具包Search and Learn,与推理框架vLLM配合,快速构建搜索策略
测试时计算扩展策略
目前扩展测试时计算主要有两种策略:自我优化和搜索。
在自我优化中,模型识别和纠正后续迭代中的错误来迭代优化自己的输出或“想法”。
团队认为虽然此策略对某些任务有效,但通常要求模型具有内置的自我优化机制,这可能会限制其适用性。
搜索方法侧重于生成多个候选答案并使用验证器选择最佳答案。
搜索策略更灵活,可以适应问题的难度。Hugging Face的研究主要聚焦于搜索方法,因为实用且可扩展。
其中验证器可以是任何东西,从硬编码到可学习的奖励模型,这里将重点介绍可学习的验证器。
具体来说,研究涉及三种搜索策略:
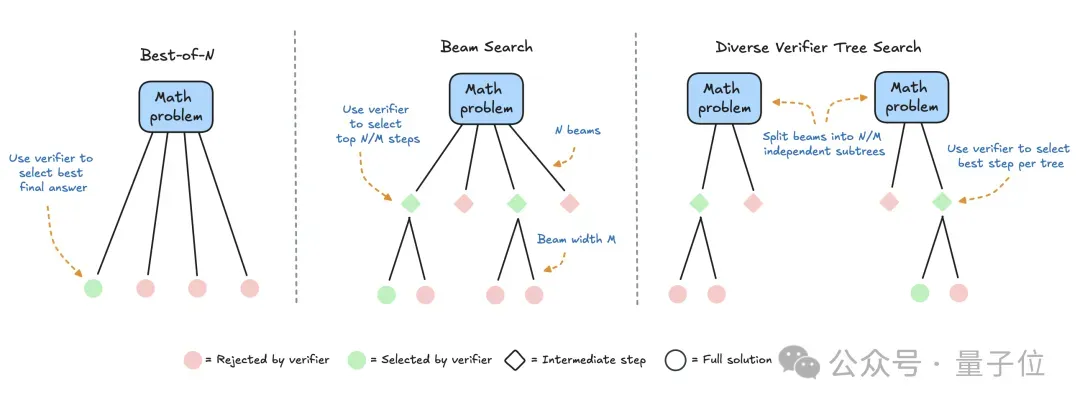
- Best-of-N
为每个问题生成多个响应,并使用奖励模型为每个候选答案分配分数。选择分数最高的答案(或加权变体),这种方法强调答案质量而不是频率。
- Beam search
一种探索解决方案空间的系统搜索方法,通常与过程奖励模型 (PRM) 相结合,以优化解决问题中中间步骤的采样和评估。与在最终答案上产生单个分数的传统奖励模型不同,PRM提供一系列分数,推理过程的每个步骤分配一个分数。这种提供精细反馈的能力使PRM非常适合大模型。
- 多样化的验证器树搜索 (DVTS)
新开发的Beam search变体,它将初始Beam拆分为独立的子树,然后使用PRM做贪婪扩展。这种方法可以提高解决方案的多样性和整体性能,尤其是在测试时算力预算较大的情况下。
实验设置:3种搜索策略PK
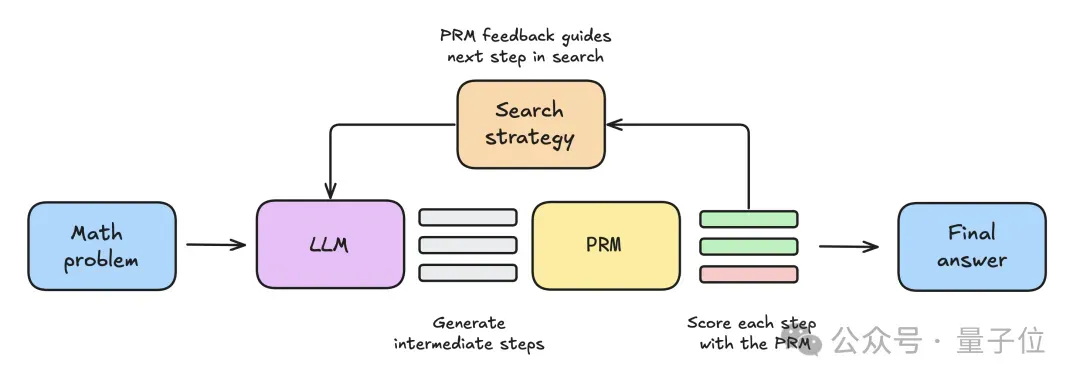
- 首先将数学问题提供给大模型,生成N个中间步骤。
- 每个步骤都由PRM评分,估计每个步骤最终能得出正确答案的概率。
- 给定的搜索策略使用这些步骤和PRM分数,来选择应该进一步探索哪些方向,生成下一轮中间步骤。
- 搜索策略终止后,PRM将对最终候选解决方案进行排名,以生成最终答案。
为了比较各种搜索策略,研究中使用了以下开放模型和数据集:
语言模型,Llama-3.2-1B-Instruct作为主要实验对象,因为轻量级模型可以快速迭代,并且在数学基准测试中性能不饱和
流程奖励模型,使用了Llama3.1-8B-PRM-Deepseek-Data,与语言模型同属一个系列,且在测试中给出了更好的结果。
数据集,使用MATH基准测试的子集MATH-500,该子集由OpenAI发布,数学问题横跨7个科目,对人类和大多数模型来说都有挑战性。
实验结果:动态分配策略达到最优
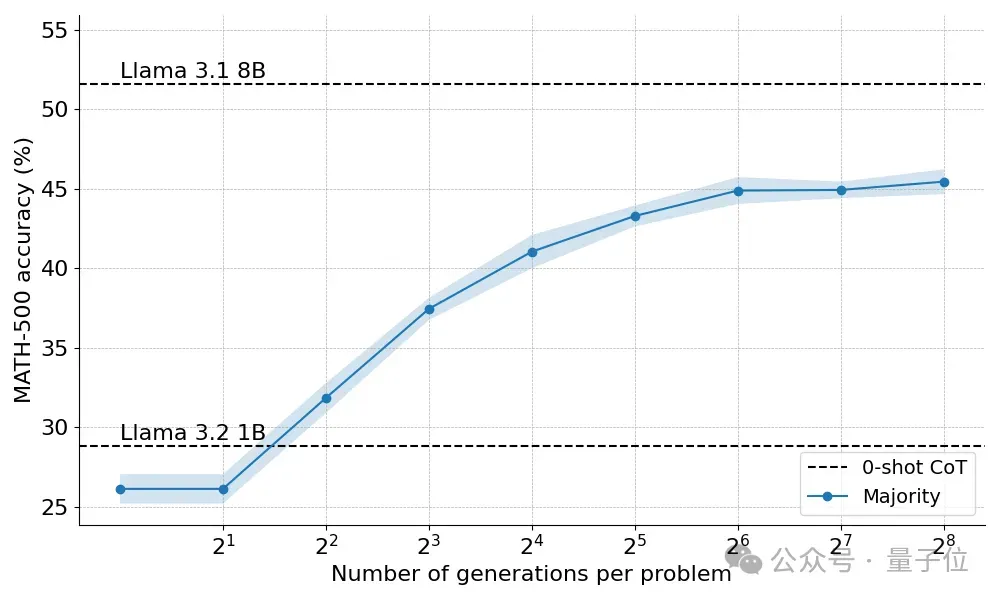
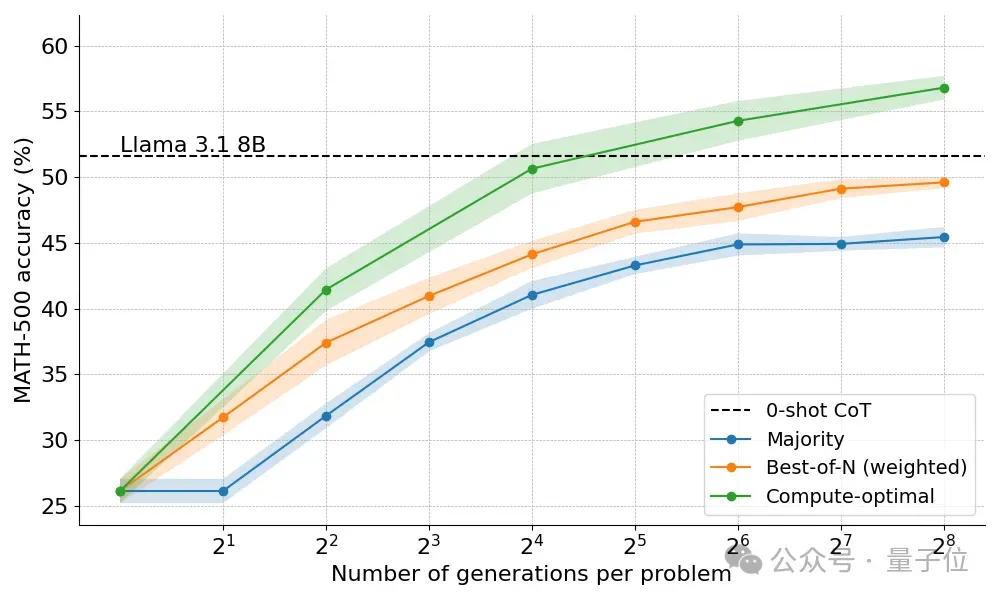
首先,多数投票策略比贪婪解码基线有显著改进,收益在大约N=64后趋于稳定。
团队认为,之所以出现这种限制,是因为多数投票难以解决需要细致入微推理的问题,或者解决几个答案错到一块去的任务。
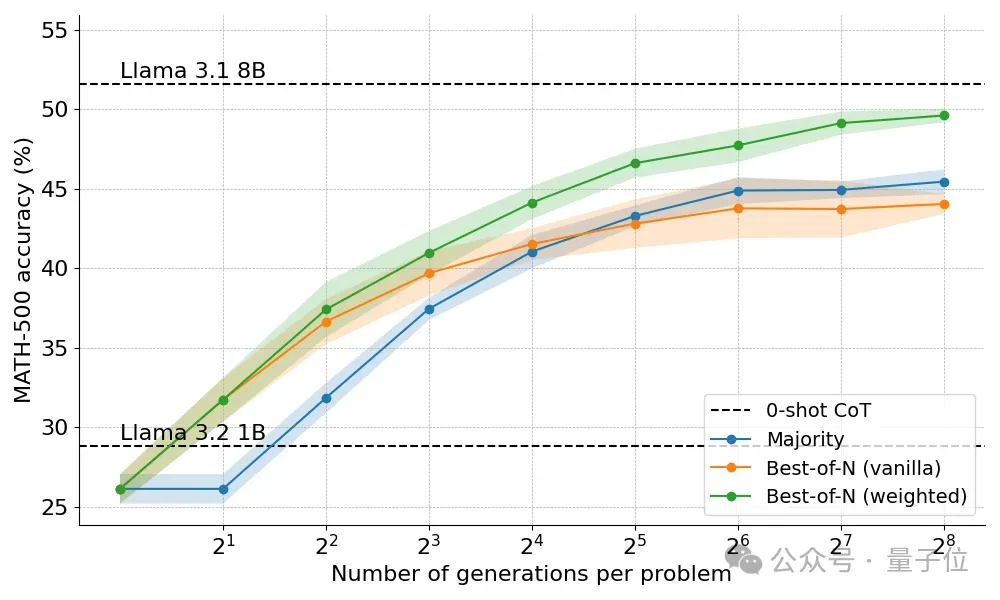
奖励模型加入后的策略,表现均有提高。
Best-of-N策略分为两种变体,原版(Vanilla)不考虑答案之间的一致性,加权版(Weighted)汇总所有结果相同的答案,并选择总分数最高的。
结果发现加权版始终优于原版,特别是在算力预算大的时候更明显,因为确保了频率较低但质量较高的答案也能获选。
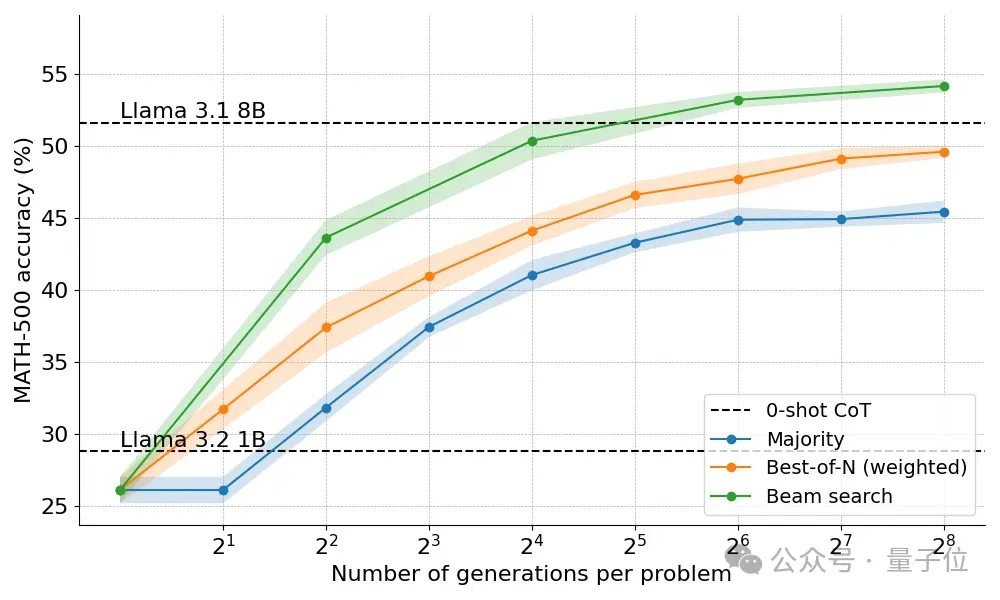
Beam Search策略终于让1B模型表现开始高于8B。
但Beam Search并不是万金油方法,在简单的问题上表现反而不如Best-of-N。
团队通过查看结果树,发现如果一个中间步骤获得了高分,那么整个树就会坍塌到这一步,影响了后续答案的多样性。
最终,DVTS方法改进了答案的多样性,该方法与Beam Search相比有以下不同之处:
- 对于给定的Beam宽度(M)和生成数量N,初始Beam集设定为N/M个独立子树
- 对于每个子树,选择PRM分数最高的步骤
- 生成M个新的下一步,继续选择分数最高的
- 重复这个过程,直到生成EOS token后终止,或达到最大深度
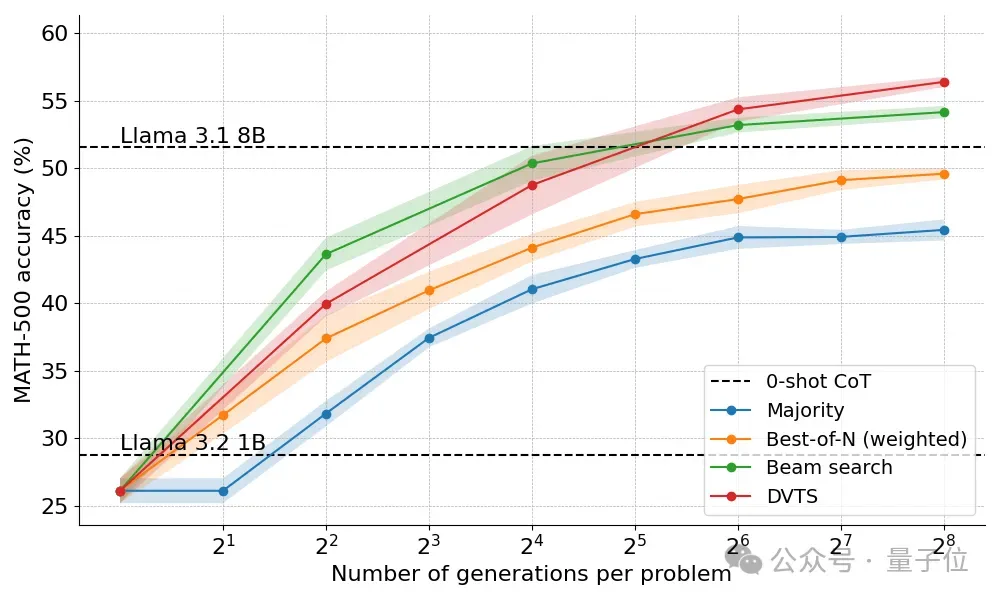
在对问题难度细分后,发现DVTS方法在N比较大时增强了对简单/中等难度问题的性能。
而Beam Search在N比较小时仍然表现最好。
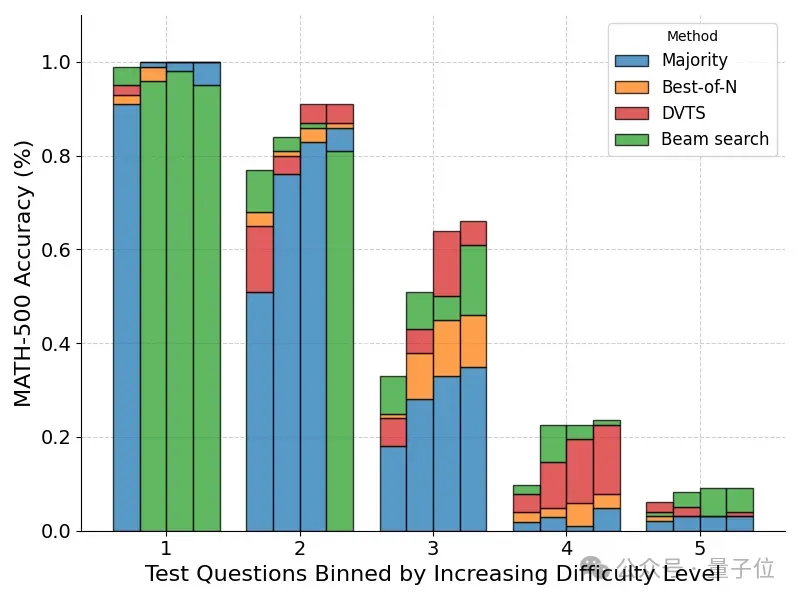
最终基于问题难度动态分配策略的方法可以取得最佳成绩。
最后团队提出,未来这项技术还有更多值得探索的地方:
- 更强大的验证器,提高其稳健性和泛化能力至关重要。
- 最终目标是实现自我验证,目前在实践中仍然难以实现,需要更细致的策略。
- 在生成过程中加入明确的中间步骤或 “想法” ,通过将结构化推理整合到搜索过程中,可以在复杂任务中获得更好的性能。
- 搜索方法可以用于合成数据,创建高质量的训练数据集
- 开放的流程奖励模型目前数量较少,是开源社区可以做出重大贡献的领域
- 目前的方法在数学和代码等领域表现出色,这些问题本质上是可验证的,如何将这些技术扩展到结构性较差或评判标准主观的任务,仍是一个重大挑战。
评论区有网友表示,这种方法更适合本地部署,而不是API调用,因为调用256次3B模型和过程奖励模型,通常会比调用一次70B模型更贵。
也有人建议在Qwen系列模型上尝试,以及指路天工Skywork发布了两个基于Qwen的PRM模型
开源代码:https://github.com/huggingface/search-and-learn


