想象一下,你正在训练一个未来的家庭机器人。你希望它能像人一样,轻松地叠好一件衬衫,整理杂乱的桌面,甚至系好一双鞋的鞋带。但最大的瓶颈是什么?不是算法,不是硬件,而是数据 —— 海量的、来自真实世界的、双手协同的、长程的、多模态的高质量数据。
想象一下,你正在训练一个未来的家庭机器人。你希望它能像人一样,轻松地叠好一件衬衫,整理杂乱的桌面,甚至系好一双鞋的鞋带。但最大的瓶颈是什么?不是算法,不是硬件,而是数据 —— 海量的、来自真实世界的、双手协同的、长程的、多模态的高质量数据。
因此为了整个具身智能探索加速,开源集合成为了大家的共同选择,从谷歌 Open-X Embodiment、智元 AgiBot Digital World,到智源 RoboCOIN 与它石智航的 World In Your Hands,都在试图构建更庞大、更完善的数据集合,并开源给到全行业。
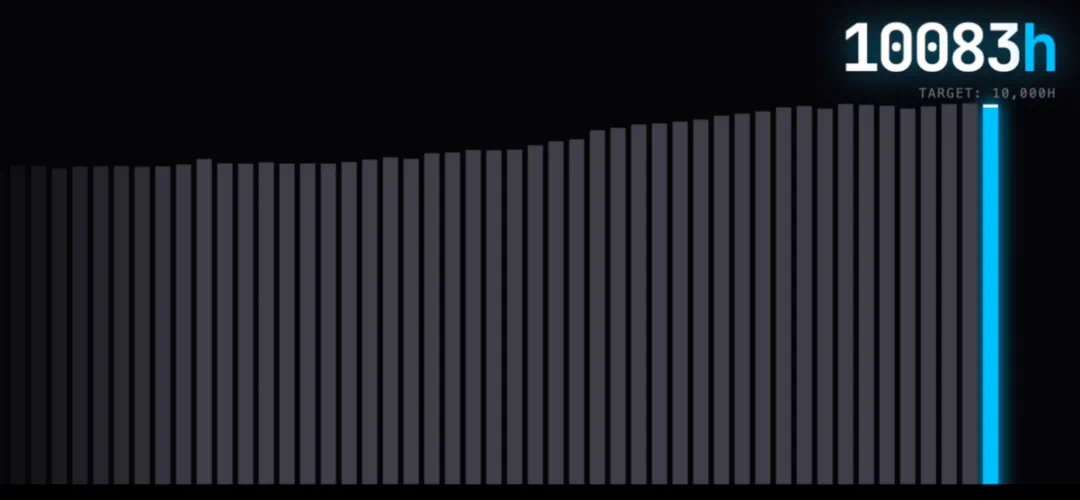
但在 1 月 6 日,有一家公司将这件事做到新高度,进行了超过 1 万小时、接近百万 clips 的具身数据集合开放,这是行业最大规模、也是泛化程度最高的开源数据集合,它就是简智机器人的 “10Kh RealOmni-Open DataSet”。
 (下载地址为:https://huggingface.co/datasets/genrobot2025/10Kh-RealOmin-OpenData,其他数据正在陆续上传。国内也与阿里魔搭、百度百舸合作,方便国内用户下载。)
(下载地址为:https://huggingface.co/datasets/genrobot2025/10Kh-RealOmin-OpenData,其他数据正在陆续上传。国内也与阿里魔搭、百度百舸合作,方便国内用户下载。)这批数据集合和之前不同点在哪儿?
总体规模大,这个体量甚至已经超越很多具身公司自己所储备的数据,而在量大的同时,这个数据集合还期望它更加“实用”。
首先需要它具备足够强的 “技能深度”,在简智开源数据集合中,没有选择去发散的扩充技能数量,而是聚焦在 10 个常见家庭任务集合中,从而对应每一项技能都有超过 1 万 Clips 规模的数据覆盖,这使得其不只是总体规模的最大,也是单个技能的行业最多。
其次是质量、模态的要求,这决定这些数据是否真正能被模型消化理解,而画面的超大 FOV、清晰的画质是基础,保证可以全方位录制到周围的环境和人的操作细节,简智这次数据集合的像素达到 “1600*1296”“30fps” 的水平;
在这之上轨迹的精度是数据质量的关键,厘米级的轨迹精度对人来说可能足够精细,但对于机器人来说则需要达到毫米级别,因此简智这次开源数据对比行业,一方面具备了大多数不具备的轨迹信息,同时通过高精度 IMU 硬件和云端重建与还原,进一步将轨迹提升到亚厘米级别。而在模态上,作为夹抓类的技能采集,夹抓的开合角度、位移也都在集合中包含。

而在技能方面,单手在实际场景中可以完成的任务优先,因此难得是在数据集中,99.2% 都是 “双手、长程任务”,这也让它变得更落地 —— 以第一批数据为例,平均 clips 长度为 1min37s。这意味着,它记录的不是一张张静态快照,而是从 “拿起散乱 T 恤” 到 “叠放整齐” 的完整过程,是动作逻辑与因果的连续学习。
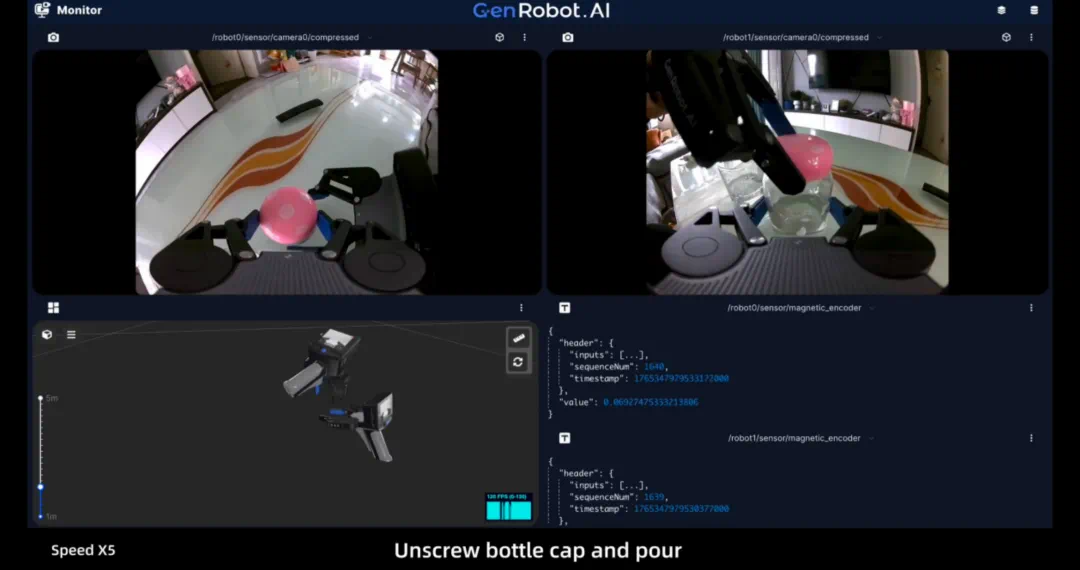
最后则是在相同技能下,数据的场景、目标泛化上需要足够丰富,人员的操作要足够自然,而非单一场景的重复、动作僵硬重复,这样才能让模型在真实的生活中,应对家庭环境、目标类型千变万化。简智这批数据来自 3000 个真实的家庭规模采集,以叠衣服为例,不同的衣服种类、平铺的位置等多重因素变量都包含在其中,弥补了传统 “数采工厂” 方案过于单一的问题。

为什么有底气开源这么大批量数据?
在这些大规模、高质量、泛化程度高数据的背后,其实一套完整的 “数据生产链条”,在这方面简智也有自己的一套方法论,完成从采集设备到云端平台,再到数据的二次迭代的闭环,这也使得简智在 2 个月时间内就积累了近百万小时规模的数据。

这其中,Gen DAS Gripper 是能完成简智规模化采集的首要触点,它相比传统的数据采集、UMI 等方案来看,可以更容易、快速地部署,不需要做任何的场地布置;同时全栈自研的 ISP 图像处理、CMOS 传感器,保证图像高质量、清晰。
同时可以做到基于车规级 IMU、双手设备同步,实现双手技能的高精度坐标对齐,异构数据时间误差小于 1ms。
在设备端,具备超强压缩能力:将数据体积压缩至原大小的 2%,同时打通在线上传通道,实现分钟级快速上传,大幅提升数据流转效率。
Gen Matrix 则是中枢数据平台,它将收集后数据进行高精准的轨迹还原、对齐、清洗处理:将众多分散设备数据收集,超强轨迹还原、环境重建能力,轨迹真值误差小于 1cm,并将异构数据进行同步与清洗,保证数据质量,并具备自动化标注、切片等进阶能力,可以高并发处理海量数据源。这在具身行业也是领先的数据平台基建。
Gen ADP(AI Data Pipeline)则是规模化、自动化数据产线,它是将 DAS 的数据完成自动化的脉搏。它将标注、加工流程自动化,让高质量数据的产出像流水一样持续、高速,2h 内完成采集与处理全过程。目前据简智公开信息,已经完成百万小时规模数据累计,并且每天以接近万小时规模增长。
开源是一件需要持续做、加速做的事情
具身智能的未来,建立在高质量数据的基石之上。在今天来看,大家对于数据的格式、规范还尚不成熟,这大大的影响了模型方案的进步速度,因此开源数据持续、加速推进,能快速填补数据鸿沟、统一技术标准、降低研发门槛、推动生态协同与自主可控,最终加速具身智能从实验室走向规模化落地。
10Kh RealOmni-Open DataSet 的开放,不仅是一份海量数据资源,更是一种通过共享加速创新的可能性。简智团队后续将继续加强数据基建建设,推出更多行业有益的数据、服务,形成 “数据共享 — 模型优化 — 场景落地 — 数据反哺” 的正向循环。