近年来,随着人工智能从感知智能向决策智能演进,世界模型 (World Models)逐渐成为机器人领域的重要研究方向。世界模型旨在让智能体对环境进行建模并预测未来状态,从而实现更高效的规划与决策。
与此同时,具身数据也迎来了爆发式关注。因为目前具身算法高度依赖于大规模的真实机器人演示数据,而这些数据的采集过程往往成本高昂、耗时费力,严重限制了其可扩展性和泛化能力。尽管仿真平台提供了一种相对低成本的数据生成方式,但由于仿真环境与真实世界之间存在显著的视觉和动力学差异(即 sim-to-real gap),导致在仿真中训练的策略难以直接迁移到真实机器人上,从而限制了其实际应用效果。因此如何高效获取、生成和利用高质量的具身数据,已成为当前机器人学习领域的核心挑战之一。
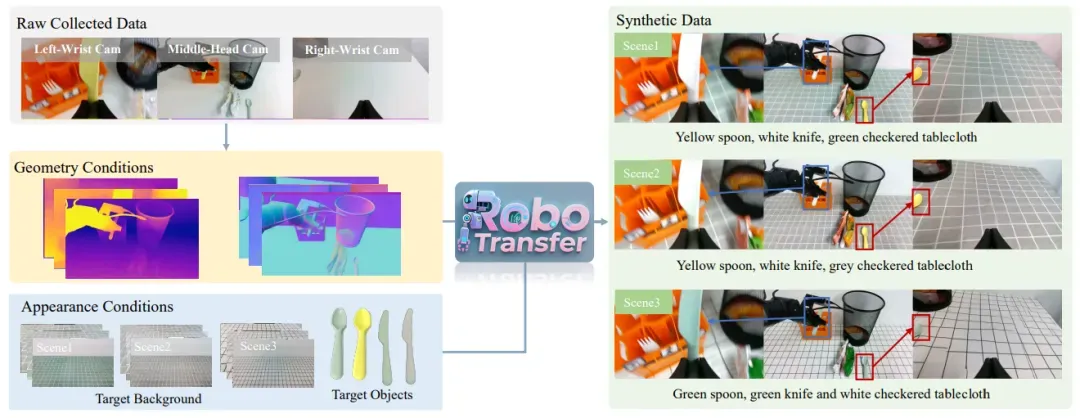
近日,地平线、极佳科技与中国科学院自动化研究所等单位提出 RoboTransfer,基于扩散模型的视频生成框架,可以用于扩充机器人策略模型的训练数据。得益于合成数据的多样性,下游策略模型能够在新场景下取得 251% 的显著提升,大幅提升策略模型的泛化性,为具身智能的通用性与泛化性奠定了坚实的基础。

- 论文题目:RoboTransfer:Geometry-Consistent Video Diffusionfor Robotic Visual Policy Transfer
- 论文链接:https://arxiv.org/pdf/2505.23171
- 项目主页:https://horizonrobotics.github.io/robot_lab/robotransfer/
模仿学习(Imitation Learning)已成为机器人操作领域的重要方法之一。通过让机器人 “模仿” 专家示教的行为,可以在复杂任务中快速构建有效的策略模型。然而,这类方法通常依赖大量高质量的真实机器人演示数据,而数据采集过程成本高、周期长,严重制约了其扩展性和泛化能力。
为了解决上述问题,本项工作提出了 RoboTransfer ,一种基于扩散模型(diffusion model)的视频生成框架,旨在实现高质量的机器人操作场景数据合成。不同于传统的仿真方法或现有生成模型,RoboTransfer 融合了多视角几何信息,并对场景中的关键组成成分(如背景、物体属性等)实现了显式控制。具体而言,RoboTransfer 通过引入跨视角特征交互机制以及全局深度图与法向图作为条件输入,确保生成视频在多个视角下的几何一致性。此外,该框架支持细粒度的编辑控制,例如更换背景、替换目标物体等,从而能够灵活地生成多样化、结构合理的视觉数据。
实验结果表明,RoboTransfer 能够生成具有高几何一致性和视觉质量的多视角视频序列。此外,使用 RoboTransfer 合成数据训练的机器人视觉策略模型,在标准测试任务中表现出显著提升的性能:在更换前景物体的场景下取得了 33.3% 的成功率相对提升,在更具挑战性的场景下(同时更换前景背景)更是达到了 251% 的显著提升。
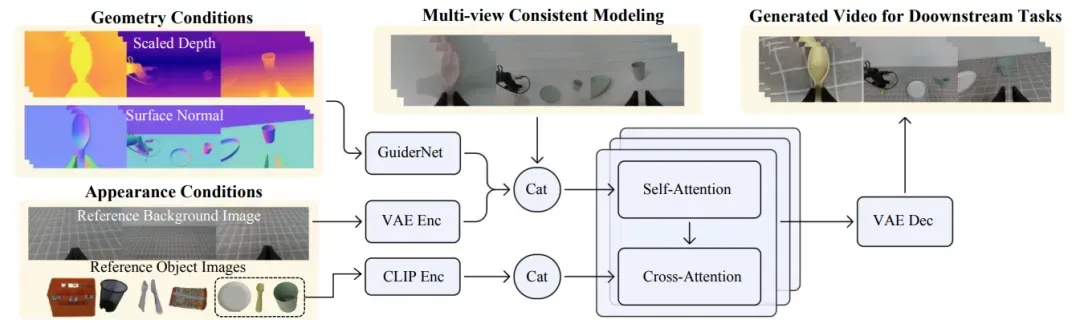
RoboTransfer 的整体框图如下,为了在视频生成过程中保证多视角之间的一致性,RoboTransfer 引入了多视角一致性建模机制,使得生成过程能够联合不同视角的信息进行推理,从而提升生成结果的空间连贯性与视觉合理性。
此外,在控制条件的设计方面,RoboTransfer 通过将控制信号解耦为几何信息与外观(纹理)信息两个部分,实现了对生成内容的细粒度控制。具体来说,在几何控制方面,采用深度图(depth map)和表面法向图(surface normal map)等具有强结构约束的表示方式,来引导生成视频中物体的三维空间结构,确保在不同视角下生成内容的几何一致性。而在外观控制方面,模型利用参考背景图像和目标物体的参考图像作为输入条件,这些图像经过编码后能够有效保留原始场景的色彩、纹理以及上下文信息,从而在生成过程中维持物体外观的细节还原能力。
在实验部分,RoboTransfer 证明可以通过 real-to-real,以及 sim-to-real 两种方式实现数据增广,并训练下游的策略模型提升其性能。
- real-to-real 数据增广基于真机采集的真实视频数据,可从中提取结构化信息作为控制条件,通过调整背景桌面与前景物体的控制参数,实现新场景数据的合成。如下图所示,左侧为真实采集的数据及其对应的结构化信息,右侧为合成结果,实验表明 RoboTransfer 能够灵活地实现背景桌布的替换。



改变前景:下图所示第一行为真机采集数据,第二行为深度图,第三行为法向图,第四行为前景物体的控制条件,第五行为合成数据,第六行为背景桌布控制条件。以下实验结果表明 RoboTransfer 可以实现对前景物体外表编辑的功能,丰富生成数据的多样性,提升策略模型的训练质量。


- sim-to-real 数据增广RoboTransfer 不仅可以改变真机数据的前景和背景,还可以实现对仿真数据的重新渲染。利用仿真数据中的结构化信息以及真实场景的物体和背景作为控制条件,RoboTransfer 可以将仿真数据的转化为逼真的真实数据,极大地降低 sim-to-real 之间的 gap,为通用机器人的训练提供了一个新的范式。以下是两个不同的仿真场景重新渲染的实验结果,左侧是叠碗,右侧是放置杯子,其中第一行为仿真采集数据,第二行为深度图,第三行为法向图,第四行为合成数据,第五行为背景参考图。


- 对比实验结果与其他 SOTA 方法的对比可以发现,RoboTransfer 在时序一致性以及多视角之间的一致性上都要显著优于其他方法。


定量实验的实验结果如下表所示,实验表明对于生成数据的前背景增广可以显著提升策略模型在新场景下的成功率,其中对于前背景完全改变的新场景,前背景的数据增广能够让策略模型获得 251% 的性能提升。

表 1 数据增广对于策略模型在不同 setting 下的提升
总体来说,该方法构建了数据处理流程,可以生成包含几何和外观控制条件的三元组数据,以训练基于扩散模型的机器人数据合成框架 RoboTransfer。实验和评估结果显示,RoboTransfer 能够生成具有多视角一致、几何一致的数据,并且可以根据参考图像修改前景和背景纹理。生成的数据用于训练机器人操作策略,从而显著提升了策略模型的泛化能力。


