单图像3D重建,即从单一视角的二维图像中恢复出三维物体的形状和结构,是计算机视觉领域的一项基础且极具挑战的难题。
学术界和工业界主要探索了两种不同的技术路线:基于回归的建模方法和生成式建模方法。基于回归的方法能够高效地推断出可见表面,但在处理遮挡区域时却力不从心,常常导致表面和纹理估计不准确。
而生成式方法虽然通过建模分布更好地处理了不确定性区域,却存在计算成本高昂、生成结果与可见表面对齐不佳等问题。
著名开源大模型平台Stability-AI开源了一个创新模型SPAR3D,通过融合上面两种传统的方法同时规避局限性,仅需0.7秒就能将单图实时完成3D重建。

开源地址:https://github.com/Stability-AI/stable-point-aware-3d
Huggingface:https://huggingface.co/stabilityai/stable-point-aware-3d
SPAR3D的架构一共使用了点采样和网格化两大阶段:点采样阶段的核心是点扩散模型,它能够根据输入图像生成包含XYZ坐标和RGB颜色信息的稀疏点云。该阶段基于DDPM框架,包含正向过程和反向过程。正向过程向原始点云添加高斯噪声,而反向过程中的去噪器则学习如何从含噪点云中恢复出噪声。
在推理时,采用DDIM采样器生成点云样本,并借助分类器自由引导(CFG)来提升采样保真度。去噪器的设计采用了类似Point-E的Transformer架构,将含噪点云线性映射为点标记,同时利用DINOv2编码输入图像作为条件标记,然后将条件标记和点标记拼接起来输入到Transformer中,以预测每个点上添加的噪声。
此外,为了降低网格化阶段逆渲染的不确定性,该阶段还直接生成了反照率点云,作为网格化阶段的输入,从而减少了逆渲染的歧义,稳定了分解学习过程。
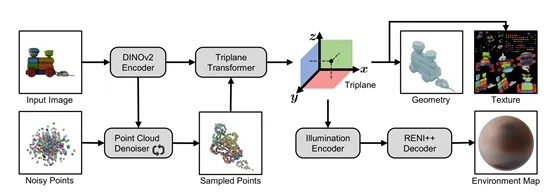
网格化阶段的目标是从输入图像和点云中生成带有纹理的网格。其骨干网络是一个大型的三平面Transformer,能够从图像和点云条件中预测三平面特征。基于三平面特征,可以估计出物体的几何形状、纹理和照明,以及从图像特征中估计金属度和粗糙度。
几何形状和材质在训练过程中输入到可微渲染器中,以便利用渲染损失来监督模型。三平面Transformer由点云编码器、图像编码器和Transformer主干网络三个子模块组成。点云编码器使用简单的Transformer编码器将点云编码为点标记,图像编码器则采用DINOv2生成局部图像嵌入。
三平面Transformer遵循PointInfinity和SF3D的设计,通过计算分离的双流设计生成高分辨率的三平面。在表面估计方面,通过浅层MLP查询三平面以产生密度值,并利用可微Marching Tetrahedron(DMTet)将隐式密度场转换为显式表面。
同时,还使用两个MLP头一起预测顶点偏移和表面法线,以减少Marching Tetrahedron引入的伪影,使表面更加平滑。对于材质和照明估计,执行逆渲染并联合估计材质(反照率、金属度和粗糙度)和照明。
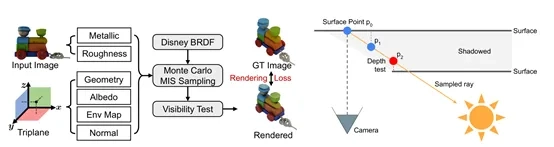
基于RENI++的学习型照明先验构建照明估计器,通过学习编码器将三平面特征映射到RENI++的潜在空间中,从而估计输入图像中的环境照明。反照率的估计方式与几何形状类似,通过浅层MLP预测每个3D位置的反照率值。
对于金属度和粗糙度,则采用概率方法通过Beta先验进行估计,并用AlphaCLIP替换SF3D中的CLIP编码器,以解决物体大小变化时的不稳定性问题。可微渲染器根据预测的环境图、PBR材质和几何表面渲染图像。使用可微网格光栅化器和可微着色器,着色器中采用标准的简化Disney PBR模型,并进行蒙特卡洛积分。
此外,为了更好地模拟通常被忽略的自遮挡现象,实现了可见性测试以改进阴影建模,灵感来源于实时图形技术,将可见性测试作为屏幕空间方法,利用光栅化器生成的深度图进行建模。
为了评估SPAR3D的性能,研究人员在GSO和Omniobject3D数据集上进行了实验。结果显示,SPAR3D在多个评估指标上都显著优于其他回归或生成式基线方法。例如,在GSO数据集上,SPAR3D的CD值为0.120,[email protected]为0.584,PSNR为18.6,LPIPS为0.139,而其他方法如Shap-E、LN3Diff、LGM等的相应指标均不如SPAR3D。
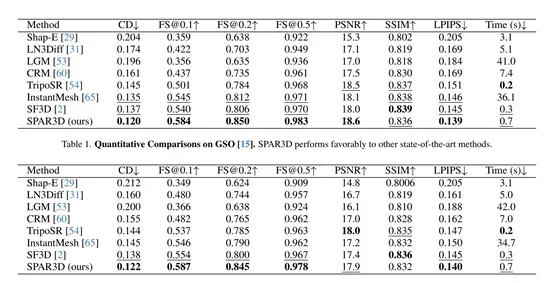
在OmniObject3D数据集上,SPAR3D同样展现出优异的性能,CD值为0.122,[email protected]为0.587,PSNR为17.9,LPIPS为0.140。这些定量比较结果充分证明了SPAR3D在几何形状和纹理质量方面的卓越性能。


