揭秘Fathom-DeepResearch:让小模型也能做深度研究的秘密武器

- 论文链接:https://arxiv.org/pdf/2509.24107v1
- 代码链接:https://github.com/FractalAIResearchLabs/Fathom-DeepResearch
一、研究背景:为什么我们需要更聪明的搜索助手?
想象一下,你想了解一个复杂的问题,比如"某个体育赛事的历史背景和相关人物",你会怎么做?可能需要在搜索引擎上反复查询,打开无数网页,然后自己整理信息。现在的大语言模型虽然很聪明,但在处理这类需要深度调研的任务时,还是有点力不从心。
这篇论文要解决的核心问题就是:如何让小型语言模型(只有40亿参数)也能像人类研究员一样,通过联网搜索、多轮推理,最终生成一份详实的研究报告?
目前的开源系统面临几个痛点:
- 训练数据不够硬核:现有的数据集(如TriviaQA)问题太简单,模型甚至不用搜索就能答对
- 工具调用不稳定:模型在多轮搜索中容易"失控",要么重复调用同一个搜索,要么乱调用
- 缺乏综合能力:大多数系统只擅长回答封闭式问题(有标准答案的),但对开放式探索性问题(需要综合多方信息)表现不佳
 图片
图片
作者的核心贡献可以概括为三个关键创新:
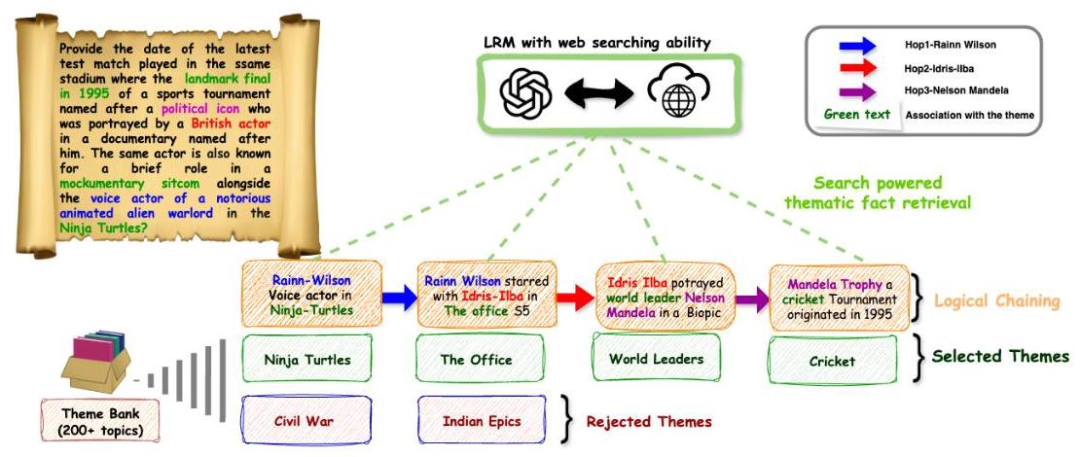
- DuetQA数据集:通过多智能体自我对弈生成了5000个高质量问答对,每个问题都必须通过实时搜索才能回答(不能靠模型的记忆蒙混过关)
- RAPO算法(奖励感知策略优化):这是对现有强化学习算法GRPO的改进,解决了多轮工具调用时训练不稳定的问题,让模型能稳定地进行超过20次工具调用
- 可控的步骤级奖励机制:不仅奖励"答对了",还细致地评估每一步搜索是否有价值——是探索新信息还是在重复无用功,从而引导模型形成更高效的搜索策略
二、相关工作:站在巨人的肩膀上
论文梳理了当前深度搜索领域的几类工作:
闭源商业系统 如OpenAI的DeepResearch、Google的Gemini等,表现强劲但不开源,普通研究者无法复现和改进。
开源尝试 包括WebSailor、Jan-Nano、ZeroSearch等模型,虽然做出了努力,但在复杂任务上与闭源系统还有明显差距。这些系统普遍存在的问题是:
- 训练数据质量不高,很多问题可以通过简单的一两次搜索解决
- 强化学习训练不稳定,模型容易学坏(比如疯狂重复调用工具但不产生有用结果)
- 缺乏对长链推理的有效控制机制
现有数据集的局限 像HotpotQA、2WIKI这类多跳问答数据集,虽然标榜"多跳推理",但实际上很多问题可以通过模型的内部知识直接回答,或者只需要访问维基百科就够了。真实世界的搜索场景要复杂得多——信息分散在各种网站上,存在噪音,需要交叉验证。
 图片
图片
三、核心方法:两阶段训练+智能奖励设计
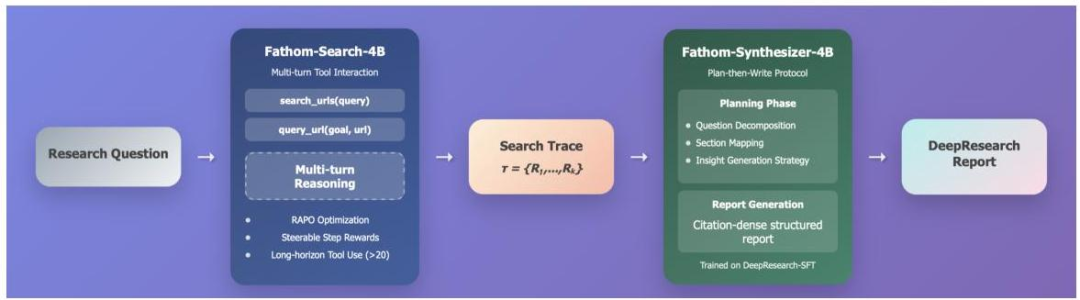
Fathom-DeepResearch系统由两个核心模型组成:
3.1 Fathom-Search-4B:会搜索的推理模型
这个模型的任务是像侦探一样在互联网上寻找证据。它有两个工具:
search_urls(网页搜索):输入查询词,返回相关网页列表及摘要query_url(定向提取):打开某个网页,根据特定目标提取有用信息
训练分两个阶段进行:
Stage 1:学会基本的搜索能力在DuetQA数据集上训练10个epoch,使用RAPO算法。这个阶段的重点是让模型学会:
- 正确使用工具(格式规范)
- 能够通过搜索找到答案
- 避免训练崩溃(GRPO容易出现的问题)
训练目标函数结合了格式奖励和答案准确性:
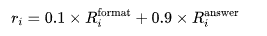
Stage 2:学会高效的长链推理继续训练2个epoch,但这次使用了可控的步骤级奖励。这个阶段的数据混合了DuetQA、数学推理数据和MuSiQue多跳问答。
关键创新在于奖励函数的设计。系统会用GPT-4.1给每个工具调用打标签:
对于search_urls:
- UNIQUESEARCH(探索新信息):搜索之前没见过的实体或事实
- REDUNDANTSEARCH(重复搜索):和之前的查询高度相似
对于query_url:
- EXPLORATION(探索):第一次访问某个网页
- VERIFICATION(验证):交叉验证已有信息(允许有限次数)
- REDUNDANTQUERY(冗余查询):超过验证次数限制的重复查询
基于这些标签,奖励函数变成:

3.2 RAPO:让训练不再崩溃的秘密

回放缓冲:为每个问题维护一个"最佳答案库"。如果某次训练所有尝试都失败了,就从库里抽一个成功案例混进去,避免方差归零。
 图片
图片
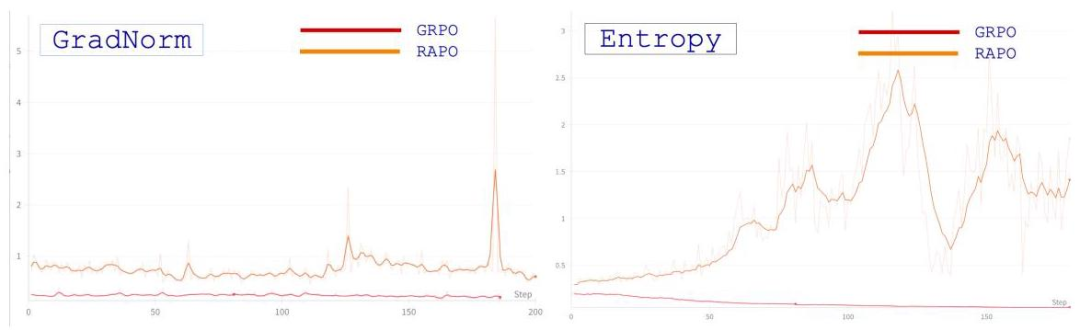
从图中可以看到,GRPO的熵值和梯度范数快速下降(意味着模型失去探索能力),而RAPO能保持稳定的训练信号。
3.3 Fathom-Synthesizer-4B:会写报告的综合模型
第二个模型的任务是把搜索轨迹变成一份可读的研究报告。它采用"先规划后撰写"的策略:
规划阶段(在标签内,用户看不到):
- 问题分解:把大问题拆成若干子问题
- 证据映射:将搜索到的每个网址和内容对应到相关章节
- 洞察策略:规划如何从证据中提炼观点
撰写阶段(生成实际报告):
- 执行摘要:总览全文
- 主体章节:按照分解的子问题组织,每个关键论断都标注引用来源
- 引用列表:列出所有引用的网址
训练数据(DeepResearch-SFT)从GPT-5蒸馏而来,包含2500个开放式问题及其完整的规划+报告对。为了处理长文本,使用YaRN技术将Qwen3-4B的上下文窗口从40K扩展到65K。
 图片
图片
四、实验效果:小模型也能打败大模型
4.1 深度搜索任务上的表现
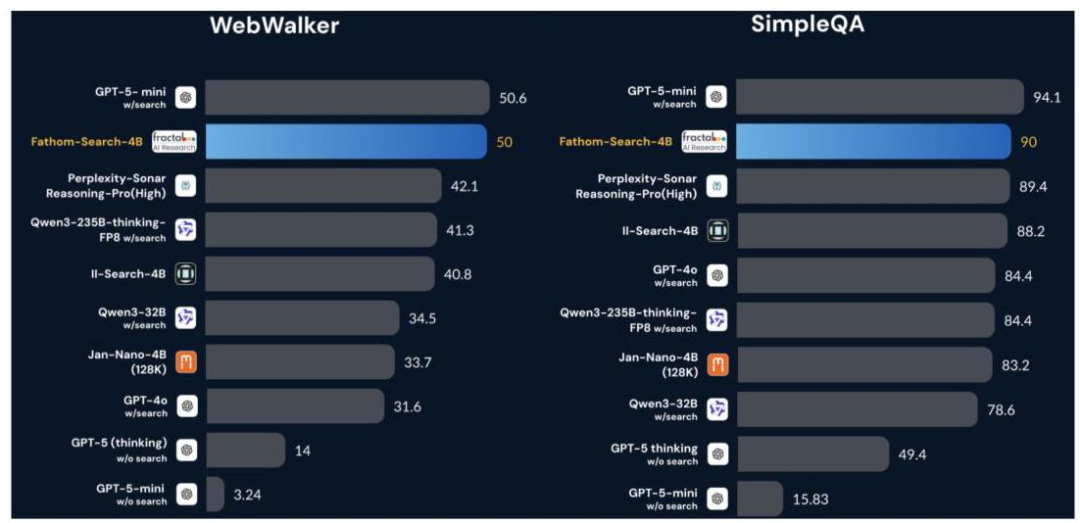
在五个主流深度搜索基准测试上(SimpleQA、FRAMES、WebWalker、Seal0、MuSiQue),Fathom-Search-4B取得了开源模型中的最佳成绩:
SimpleQA(真实世界问答):90.0%准确率,超过了所有开源竞争对手,甚至比GPT-4o(搜索版)还高5.6个百分点
WebWalker(长链推理):50.0%准确率,比第二名II-Search-4B高出9.2个百分点
FRAMES(多帧推理):64.8%准确率,显著领先
更有意思的是,在一些任务上,这个40亿参数的小模型甚至能接近甚至超越o3这样的超大模型(无搜索版本)。
4.2 通用推理能力依然强劲
为了验证模型没有"偏科"(只会搜索不会推理),作者还在四个通用推理基准上测试了Fathom-Search-4B:
- GPQA-Diamond(研究生级科学问题):60.1%
- MedQA(医学问答):75.4%
- AIME-25(数学竞赛):70.0%
这些成绩证明,模型在获得搜索能力的同时,原有的推理能力没有退化。
 图片
图片
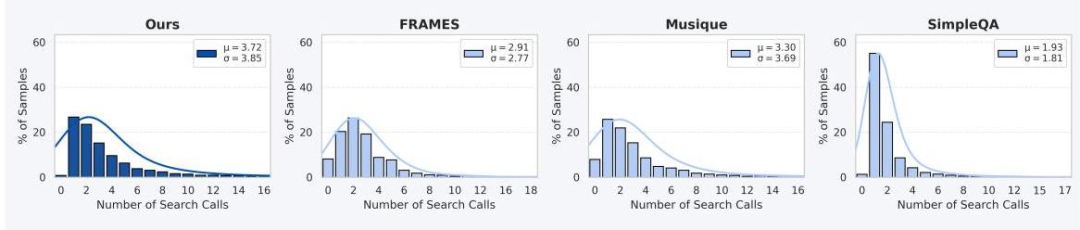
从工具调用分布图可以看出,DuetQA数据集确实更"硬核"——o3模型在这个数据集上平均需要3.3次搜索才能答对,分布呈长尾;而在SimpleQA上平均只需1.9次。这证明了数据集设计的有效性。
4.3 深度研究报告生成
在DeepResearch-Bench(开放式研究报告生成基准)上,Fathom-DeepResearch的整体得分为45.47,超过了Claude-3.7、Perplexity Deep Research、Grok等商业系统,仅次于Gemini-2.5-Pro和OpenAI DeepResearch。
具体指标上:
- RACE综合评分:45.47(考察全面性、深度、可读性)
- 引用准确率:56.1%(保证引用的来源真实可靠)
- 有效引用数:38.3(足够的证据支撑)
考虑到这是一个40亿参数的开源模型,这个成绩相当亮眼。
 图片
图片
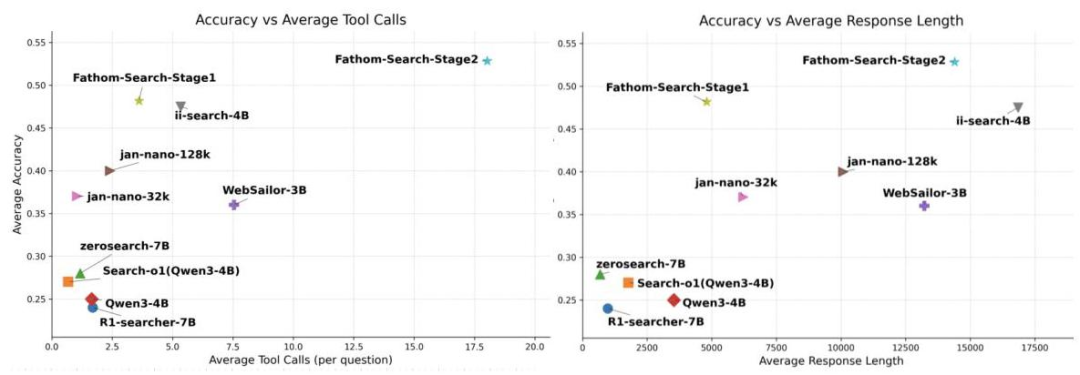
左图展示了准确率与工具调用次数的关系,右图展示了准确率与回答长度的关系。可以看到Fathom-Search-4B(Stage-2)在准确率和效率上都取得了最佳平衡。
4.4 消融实验:每个组件都很重要
RAPO vs GRPO:如表3所示,使用RAPO训练的模型在所有任务上都优于GRPO,且平均生成长度更短(5000 vs 9000 tokens),说明RAPO既提升了准确率,又提高了效率。
可控步骤级奖励的作用:如表4所示,引入步骤级奖励后,WebWalker任务的准确率从43.2%提升到50.0%,同时平均生成长度从5500增加到14500 tokens。这说明模型学会了在需要时进行更深入的探索。
 图片
图片
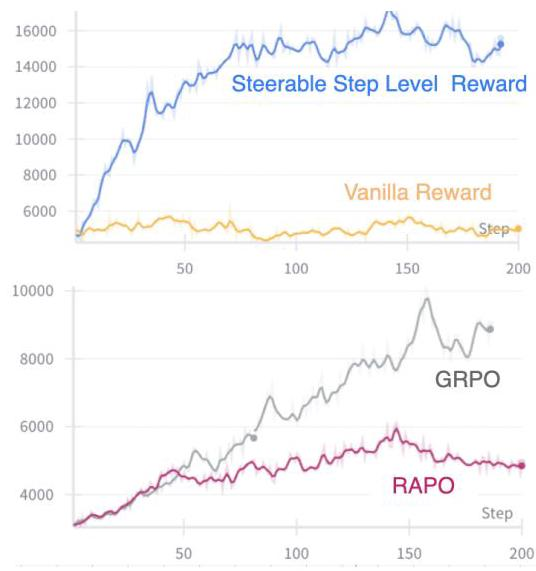
从训练曲线可以看出:
- 使用可控步骤级奖励时,模型的回答长度稳步增长到14000 tokens,说明学会了长链推理
- 使用普通奖励时,长度在6000 tokens就饱和了,无法进一步提升
- RAPO相比GRPO,训练过程更平滑,没有大幅波动
五、论文总结:开源深度研究的新里程碑
这篇论文的核心价值在于:证明了小型语言模型(40亿参数)通过精心设计的训练流程,也能在复杂的深度研究任务上与大型商业模型一较高下。
三个关键要素缺一不可:
- 高质量数据:DuetQA通过多智能体自我对弈,生成了真正需要联网搜索才能回答的问题,避免了模型"走捷径"
- 稳定训练:RAPO算法解决了多轮工具调用场景下的训练不稳定问题,让长链推理成为可能
- 智能奖励:步骤级奖励机制不仅关注最终答案,还细致评估每一步操作的价值,引导模型形成高效的搜索策略
局限性也值得注意:作者坦诚地指出,当前系统在测试时的可扩展性有限——虽然训练时能学会长链推理,但推理时的表现提升有限。此外,同步训练流程在大规模应用时效率不高,未来需要转向异步框架。
从工程实践角度看,这个工作的意义在于:降低了深度研究能力的门槛。以前只有资源雄厚的大公司才能训练出具备这种能力的模型,现在普通研究者和开发者也能在40亿参数规模上实现类似功能。这对于推动AI民主化、加速相关应用落地都有重要价值。
未来的研究方向可能包括:如何进一步提升测试时的可扩展性?如何在更小的模型(比如10亿参数)上实现类似能力?如何让系统更好地处理多模态信息(图表、视频等)?这些都是值得探索的问题。


