大家好,我是写代码的中年人。在这个人人谈论“Token量”、“百万上下文”、“按Token计费”的AI时代,“Tokenizer(分词器)”这个词频频出现在开发者和研究者的视野中。它是连接自然语言与神经网络之间的一座桥梁,是大模型运行逻辑中至关重要的一环。很多时候,你以为自己在和大模型对话,其实你和它聊的是一堆Token。
今天我们就来揭秘大模型背后的魔法之一:Tokenizer。我们不仅要搞懂什么是Tokenizer,还要了解BPE(Byte Pair Encoding)的分词原理,最后还会带你看看大模型是怎么进行分词的。我还会用代码演示:如何训练你自己的Tokenizer!
注:揭秘大模型的魔法属于连载文章,一步步带你打造一个大模型。
Tokenizer 是什么
Tokenizer是大模型语言处理中用于将文本转化为模型可处理的数值表示(通常是token ID序列)的关键组件。它负责将输入文本分割成最小语义单元(tokens),如单词、子词或字符,并将其映射到对应的ID。
在大模型的世界里,模型不会直接处理我们熟悉的文本。例如,输入:
复制Hello, world!
模型并不会直接理解“H”、“e”、“l”、“l”、“o”,它理解的是这些字符被转换成的数字——准确地说,是Token ID。Tokenizer的作用就是:
把原始文本分割成“Token”:通常是词、词干、子词,甚至字符或字节。
将这些Token映射为唯一的整数ID:也就是模型训练和推理中使用的“输入向量”。
最终的流程是:
复制文本 => Token列表 => Token ID => 输入大模型
每个模型的 Tokenizer 通常都是不一样的,下表列举了一些影响Tokenizer的因素:
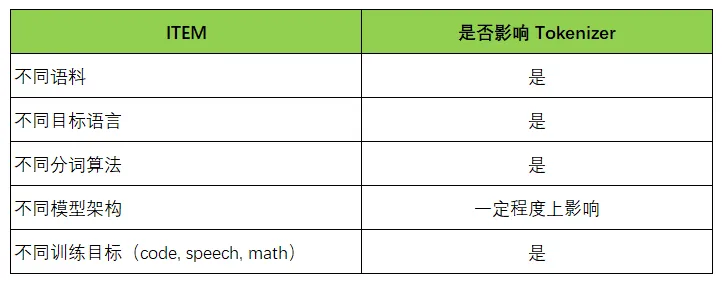
Tokenizer 是语言模型的“地基”之一,并不是可以通用的。一个合适的 tokenizer 会大幅影响:模型的 token 分布、收敛速度、上下文窗口利用率、稀疏词的处理能力。
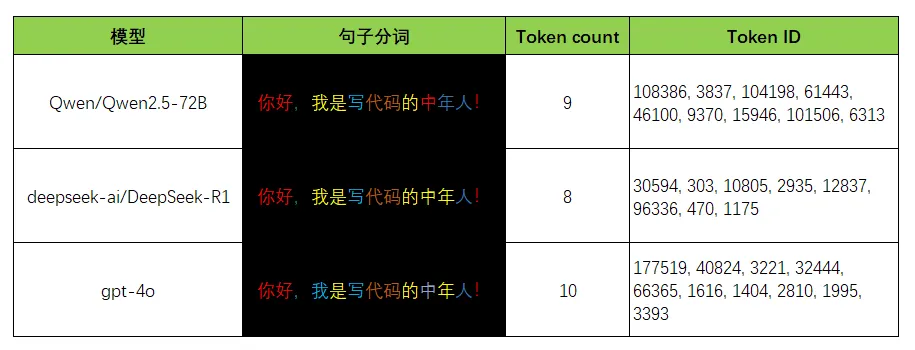
如上图,不同模型,分词方法不同,对应的Token ID也不同。
常见的分词方法介绍
常见的分词方法是大模型语言处理中将文本分解为最小语义单元(tokens)的核心技术。不同的分词方法适用于不同场景,影响模型的词汇表大小、处理未登录词(OOV)的能力以及计算效率。以下是常见分词方法的介绍:
01 基于单词的分词
原理:将文本按空格或标点分割为完整的单词,每个单词作为一个token。
实现:通常结合词汇表,将单词映射到ID。未在词汇表中的词被标记为[UNK](未知)。
优点:简单直观,token具有明确的语义。适合英语等以空格分隔的语言。
缺点:词汇表可能很大(几十万到百万),增加了模型的参数和内存。未登录词(OOV)问题严重,如新词、拼写错误无法处理。对中文等无明显分隔的语言不适用。
应用场景:早期NLP模型,如Word2Vec。适合词汇量有限的特定领域任务。
示例:文本: "I love coding" → Tokens: ["I", "love", "coding"]
02 基于字符的分词
原理:将文本拆分为单个字符(或字节),每个字符作为一个token。
实现:词汇表只包含字符集(如ASCII、Unicode),无需复杂的分词规则。
优点:词汇表极小(几十到几百),内存占用低。无未登录词问题,任何文本都能被分解。适合多语言和拼写变体。
缺点:token序列长,增加模型计算负担(如Transformer的注意力机制)。丢失单词级语义,模型需学习更复杂的上下文关系。
应用场景:多语言模型(如mBERT的部分实现)。处理拼写错误或非标准文本的任务。
示例:文本: "I love" → Tokens: ["I", " ", "l", "o", "v", "e"]
03 基于子词的分词
原理:将文本分解为介于单词和字符之间的子词单元,常见算法包括BPE、WordPiece和Unigram LM。子词通常是高频词或词片段。
实现:通过统计或优化算法构建词汇表,动态分割文本,保留常见词并拆分稀有词。
优点:平衡了词汇表大小和未登录词处理能力。能处理新词、拼写变体和多语言文本。token具有一定语义,序列长度适中。
缺点:分词结果可能不直观(如"playing"拆为"play" + "##ing")。需要预训练分词器,增加前期成本。
常见子词算法
01 Byte-Pair Encoding (BPE)
原理:从字符开始,迭代合并高频字符对,形成子词。
应用:GPT系列、RoBERTa。
示例:"lowest" → ["low", "##est"]。
02 WordPiece
原理:类似BPE,但基于最大化语言模型似然选择合并。
应用:BERT、Electra。
示例:"unhappiness" → ["un", "##hap", "##pi", "##ness"]。
03 Unigram Language Model
原理:通过语言模型优化选择最优子词集合,允许多种分割路径。
应用:T5、ALBERT
应用场景:几乎所有现代大模型(如BERT、GPT、T5)。多语言、通用NLP任务。
示例:文本: "unhappiness" → Tokens: ["un", "##hap", "##pi", "##ness"]
04 基于SentencePiece的分词
原理:一种无监督的分词方法,将文本视为字符序列,直接学习子词分割,不依赖语言特定的预处理(如空格分割)。支持BPE或Unigram LM算法。
实现:训练一个模型(.model文件),包含词汇表和分词规则,直接对原始文本编码/解码。
优点:语言无关,适合多语言和无空格语言(如中文、日文)。统一处理原始文本,无需预分词。能处理未登录词,灵活性高。
缺点:需要额外训练分词模型。分词结果可能不够直观。
应用场景:T5、LLaMA、mBART等跨语言模型。中文、日文等无明确分隔的语言。
示例:文本: "こんにちは"(日语:你好) → Tokens: ["▁こ", "ん", "に", "ち", "は"]
05 基于规则的分词
原理:根据语言特定的规则(如正则表达式)将文本分割为单词或短语,常结合词典或语法规则。
实现:使用工具(如Jieba for Chinese、Mecab for Japanese)或自定义规则进行分词。
优点:分词结果符合语言习惯,语义清晰。适合特定语言或领域(如中文分词)。
缺点:依赖语言特定的规则和词典,跨语言通用性差。维护成本高,难以处理新词或非标准文本。
应用场景:中文(Jieba、THULAC)、日文(Mecab)、韩文等分词。特定领域的专业术语分词。
示例:文本: "我爱编程"(中文) → Tokens: ["我", "爱", "编程"]
06 基于Byte-level Tokenization
原理:直接将文本编码为字节序列(UTF-8编码),每个字节作为一个token。常结合BPE(如Byte-level BPE)。
实现:无需预定义词汇表,直接处理字节序列,动态生成子词。
优点:完全语言无关,词汇表极小(256个字节)。无未登录词问题,适合多语言和非标准文本。
缺点:序列长度较长,计算开销大。语义粒度低,模型需学习复杂模式。
应用场景:GPT-3、Bloom等大规模多语言模型。处理原始字节输入的任务。
示例:文本: "hello" → Tokens: ["h", "e", "l", "l", "o"](或字节表示)。
从零实现BPE分词器
子词分词(BPE、WordPiece、SentencePiece)是现代大模型的主流,因其在词汇表大小、未登录词处理和序列长度之间取得平衡,本次我们使用纯Python,不依赖任何开源框架来实现一个BPE分词器。
我们先实现一个BPETokenizer类:
复制import json
from collections import defaultdict
import re
import os
class BPETokenizer:
def __init__(self):
self.vocab = {} # token -> id
self.inverse_vocab = {} # id -> token
self.merges = [] # List of (token1, token2) pairs
self.merge_ranks = {} # pair -> rank
self.next_id = 0
self.special_tokens = []
def get_stats(self, word_freq):
pairs = defaultdict(int)
for word, freq in word_freq.items():
symbols = word.split()
for i in range(len(symbols) - 1):
pairs[(symbols[i], symbols[i + 1])] += freq
return pairs
def merge_vocab(self, pair, word_freq):
bigram = ' '.join(pair)
replacement = ''.join(pair)
new_word_freq = {}
pattern = re.compile(r'(?<!\S)' + re.escape(bigram) + r'(?!\S)')
for word, freq in word_freq.items():
new_word = pattern.sub(replacement, word)
new_word_freq[new_word] = freq
return new_word_freq
def train(self, corpus, vocab_size, special_tokens=None):
if special_tokens is None:
special_tokens = ['[PAD]', '[UNK]', '[CLS]', '[SEP]', '[MASK]']
self.special_tokens = special_tokens
for token in special_tokens:
self.vocab[token] = self.next_id
self.inverse_vocab[self.next_id] = token
self.next_id += 1
word_freq = defaultdict(int)
for text in corpus:
words = re.findall(r'\w+|[^\w\s]', text, re.UNICODE)
for word in words:
word_freq[' '.join(list(word))] += 1
while len(self.vocab) < vocab_size:
pairs = self.get_stats(word_freq)
if not pairs:
break
best_pair = max(pairs, key=pairs.get)
self.merges.append(best_pair)
self.merge_ranks[best_pair] = len(self.merges) - 1
word_freq = self.merge_vocab(best_pair, word_freq)
new_token = ''.join(best_pair)
if new_token not in self.vocab:
self.vocab[new_token] = self.next_id
self.inverse_vocab[self.next_id] = new_token
self.next_id += 1
def encode(self, text):
words = re.findall(r'\w+|[^\w\s]', text, re.UNICODE)
token_ids = []
for word in words:
tokens = list(word)
while len(tokens) > 1:
pairs = [(tokens[i], tokens[i + 1]) for i in range(len(tokens) - 1)]
merge_pair = None
merge_rank = float('inf')
for pair in pairs:
rank = self.merge_ranks.get(pair, float('inf'))
if rank < merge_rank:
merge_pair = pair
merge_rank = rank
if merge_pair is None:
break
new_tokens = []
i = 0
while i < len(tokens):
if i < len(tokens) - 1 and (tokens[i], tokens[i + 1]) == merge_pair:
new_tokens.append(''.join(merge_pair))
i += 2
else:
new_tokens.append(tokens[i])
i += 1
tokens = new_tokens
for token in tokens:
token_ids.append(self.vocab.get(token, self.vocab['[UNK]']))
return token_ids
def decode(self, token_ids):
tokens = [self.inverse_vocab.get(id, '[UNK]') for id in token_ids]
return ''.join(tokens)
def save(self, output_dir):
os.makedirs(output_dir, exist_ok=True)
with open(os.path.join(output_dir, 'vocab.json'), 'w', encoding='utf-8') as f:
json.dump(self.vocab, f, ensure_ascii=False, indent=2)
with open(os.path.join(output_dir, 'merges.txt'), 'w', encoding='utf-8') as f:
for pair in self.merges:
f.write(f"{pair[0]} {pair[1]}\n")
with open(os.path.join(output_dir, 'tokenizer_config.json'), 'w', encoding='utf-8') as f:
config = {
"model_type": "bpe",
"vocab_size": len(self.vocab),
"special_tokens": self.special_tokens,
"merges_file": "merges.txt",
"vocab_file": "vocab.json"
}
json.dump(config, f, ensure_ascii=False, indent=2)
def export_token_map(self, path):
with open(path, 'w', encoding='utf-8') as f:
for token_id, token in self.inverse_vocab.items():
f.write(f"{token_id}\t{token}\t{' '.join(token)}\n")
def print_visualization(self, text):
words = re.findall(r'\w+|[^\w\s]', text, re.UNICODE)
visualized = []
for word in words:
tokens = list(word)
while len(tokens) > 1:
pairs = [(tokens[i], tokens[i + 1]) for i in range(len(tokens) - 1)]
merge_pair = None
merge_rank = float('inf')
for pair in pairs:
rank = self.merge_ranks.get(pair, float('inf'))
if rank < merge_rank:
merge_pair = pair
merge_rank = rank
if merge_pair is None:
break
new_tokens = []
i = 0
while i < len(tokens):
if i < len(tokens) - 1 and (tokens[i], tokens[i + 1]) == merge_pair:
new_tokens.append(''.join(merge_pair))
i += 2
else:
new_tokens.append(tokens[i])
i += 1
tokens = new_tokens
visualized.append(' '.join(tokens))
return ' | '.join(visualized)
def load(self, path):
with open(os.path.join(path, 'vocab.json'), 'r', encoding='utf-8') as f:
self.vocab = json.load(f)
self.vocab = {k: int(v) for k, v in self.vocab.items()}
self.inverse_vocab = {v: k for k, v in self.vocab.items()}
self.next_id = max(self.vocab.values()) + 1
with open(os.path.join(path, 'merges.txt'), 'r', encoding='utf-8') as f:
self.merges = []
self.merge_ranks = {}
for i, line in enumerate(f):
token1, token2 = line.strip().split()
pair = (token1, token2)
self.merges.append(pair)
self.merge_ranks[pair] = i
config_path = os.path.join(path, 'tokenizer_config.json')
if os.path.exists(config_path):
with open(config_path, 'r', encoding='utf-8') as f:
config = json.load(f)
self.special_tokens = config.get("special_tokens", [])函数说明:
__init__:初始化分词器,创建词汇表、合并规则等数据结构。
get_stats:统计词频字典中相邻符号对的频率。
merge_vocab:根据符号对合并词频字典中的token。
train:基于语料库训练BPE分词器,构建词汇表。
encode:将文本编码为token id序列。
decode:将token id序列解码为文本。
save:保存分词器状态到指定目录。
export_token_map:导出token映射到文件。
print_visualization:可视化文本的BPE分词过程。
load:从指定路径加载分词器状态。
加载测试数据进行训练:
复制if __name__ == "__main__":
corpus = load_corpus_from_file("水浒传.txt")
tokenizer = BPETokenizer()
tokenizer.train(corpus, vocab_size=500)
tokenizer.save("./bpe_tokenizer")
tokenizer.export_token_map("./bpe_tokenizer/token_map.tsv")
print("\nSaved files:")
print(f"vocab.json: {os.path.exists('./bpe_tokenizer/vocab.json')}")
print(f"merges.txt: {os.path.exists('./bpe_tokenizer/merges.txt')}")
print(f"tokenizer_config.json: {os.path.exists('./bpe_tokenizer/tokenizer_config.json')}")
print(f"token_map.tsv: {os.path.exists('./bpe_tokenizer/token_map.tsv')}")此处我选择了开源的数据,水浒传全文档进行训练,请注意:训练数据应该以章节分割,请根据具体上下文决定。
文章如下:

在这里要注意vocab_size值的选择:
小语料测试 → vocab_size=100~500
训练 AI 语言模型前分词器 → vocab_size=1000~30000
实际场景调优 → 可实验不同大小,看 token 数、OOV 情况等
进行训练:
我们执行完训练代码后,程序会在bpe_tokenizer文件夹下生成4个文件:
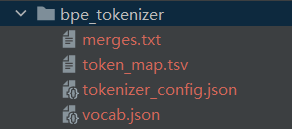
vocab.json:存储词汇表,记录每个token到其id的映射(如{"[PAD]": 0, "he": 256})。
merges.txt:存储BPE合并规则,每行是一对合并的符号(如h e表示合并为he)。
tokenizer_config.json:存储分词器配置,包括模型类型、词汇表大小、特殊token等信息。
token_map.tsv:存储token id到token的映射,每行格式为id\ttoken\ttoken的字符序列(如256\the\th e),用于调试或分析。
我们本次测试vocab_size选择了500,我们打开vocab.json查看,里面有500个词:
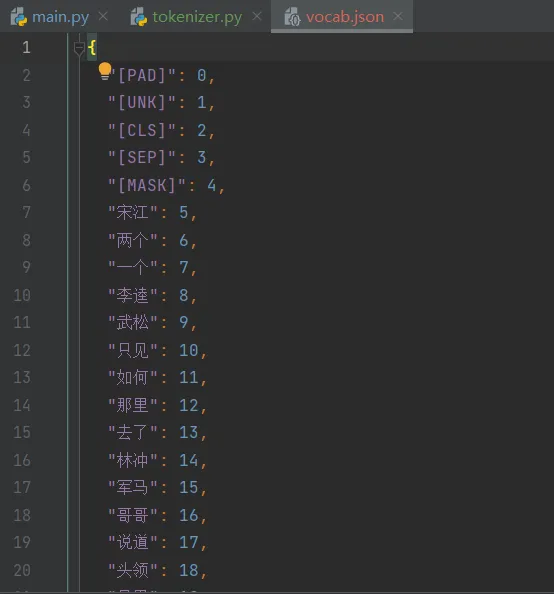
进行测试:
我们执行如下代码进行测试:
复制if __name__ == '__main__':
# 加载分词器
tokenizer = BPETokenizer()
tokenizer.load('./bpe_tokenizer')
# 测试分词和还原
text = "且说鲁智深自离了五台山文殊院,取路投东京来,行了半月之上。"
ids = tokenizer.encode(text)
print("Encoded:", ids)
print("Decoded:", tokenizer.decode(ids))
print("\nVisualization:")
print(tokenizer.print_visualization(text))复制# 输出 Encoded: [60, 67, 1, 238, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 125, 1, 1, 1, 1, 1, 1, 1, 1, 1] Decoded: 且说鲁智深[UNK]离了[UNK][UNK][UNK][UNK][UNK][UNK][UNK][UNK][UNK][UNK]东京[UNK][UNK][UNK][UNK][UNK][UNK][UNK][UNK][UNK] Visualization: 且说 鲁智深 自 离了 五 台 山 文 殊 院 | , | 取 路 投 东京 来 | , | 行 了 半 月 之 上 | 。
我们看到解码后,输出很多[UNK],出现 [UNK] 并非编码器的问题,而是训练语料覆盖不够和vocab设置的值太小, 导致token 没有进入 vocab。这个到后边我们真正训练时,再说明。
BPE它是一种压缩+分词混合技术。初始时我们把句子分成单字符。然后统计出现频率最高的字符对,不断合并,直到词表大小满足预设。