
大家好,我是写代码的中年人。
上一篇我们实现了一个“无可训练参数”的注意力机制,让每个词都能“看看别人”,计算出自己的上下文理解。
虽然实现起来不难,但它只是个“玩具级”的注意力,离真正的大模型还差了几个“亿”个参数。今天,我们来实现一个可训练版本的自注意力机制,这可是 Transformer 的核心!
01、什么叫“可训练”的注意力?
在大模型里,注意力机制不是写死的,而是学出来的。
为了让每个词都能“智能提问、精准关注”,我们需要三个可训练的权重矩阵:
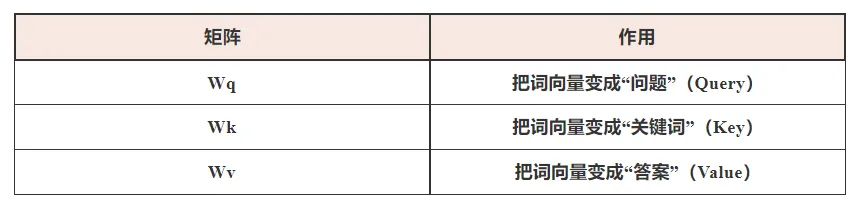
每个词自己造问题,然后去问别的词,看看谁最“对味”,然后决定听谁的意见。
为什么自注意力机制(Self-Attention)中需要三个可训练的权重矩阵,也就是常说的:
Wq:Query 权重矩阵
Wk:Key 权重矩阵
Wv:Value 权重矩阵
这个设计最早出现在 2017 年 Google 的论文《Attention is All You Need》中,也就是Transformer架构的原始论文。这三个矩阵的引入不是随便“拍脑袋”的设计,而是有明确动机的:

# ONE
这段论文奠定了 Transformer 的注意力计算基础。Transformer 后续所有的 Multi-Head Attention、Encoder-Decoder Attention,都是基于这个 Scaled Dot-Product Attention 构建的。
02、我是谁?我在哪?我要关注谁?
其实自注意力就是一种带可训练权重的加权平均机制,它做了三件事:
把每个词向量分别变成三个形态:Query(查询)、Key(键)、Value(值);
计算 Query 和所有 Key 的相似度(注意力权重);
用这个权重加权 Value 向量,得出最终的输出向量。每个词都在用“自己的 Query”去看“别人的 Key”,然后决定“我到底该关注谁”。
如果我们想理解这些内容,最好以代码的形式来逐步理解:
复制上面的代码执行后输出:
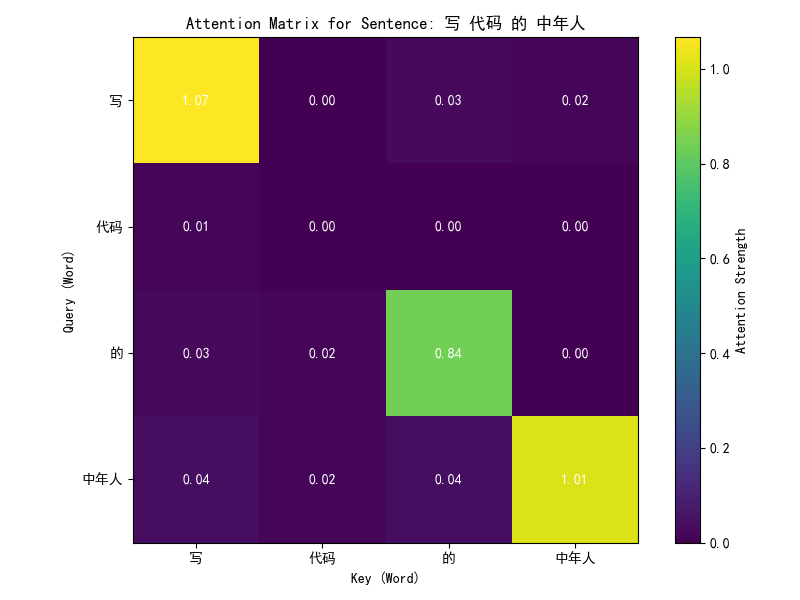
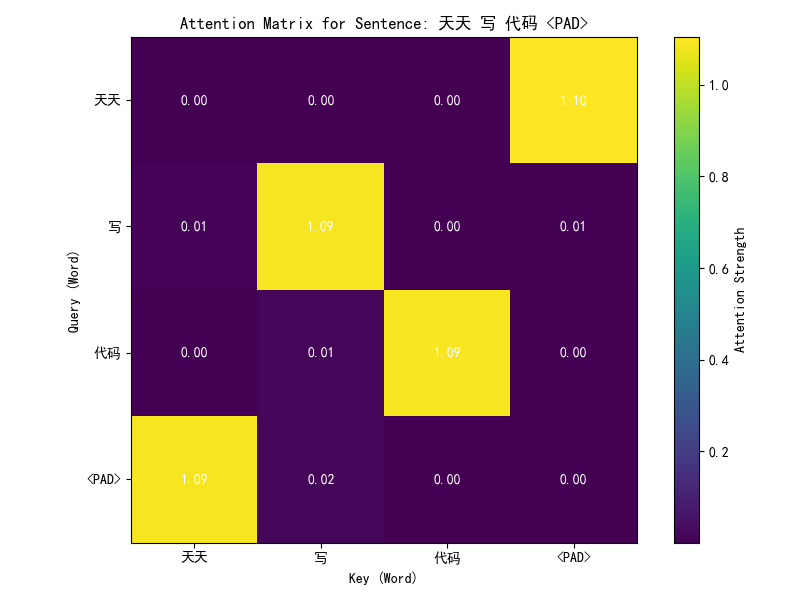
代码详解:
这段代码实现了一个简单的自注意力(Self-Attention)模型,并通过一个模拟的中文数据集进行训练,展示自注意力机制如何捕捉句子中词语之间的关系。以下是代码的详细解释,以及对自注意力机制的深入分析。
这段代码的核心目标是:实现自注意力模块:通过定义一个SelfAttention类,实现自注意力机制,模拟Transformer模型中的核心组件。训练模型:使用一个简单的中文词汇数据集,训练自注意力模型,使其学习词语之间的注意力分布。可视化注意力权重:通过绘制注意力矩阵,直观展示模型如何关注句子中不同词语之间的关系。
代码主要分为以下几个部分:数据集构建:构造一个小型中文词汇表和两个短句,模拟自然语言处理任务。模型定义:实现自注意力模块,包含查询(Query)、键(Key)、值(Value)的线性变换和注意力计算。训练过程:通过优化模型,使其输出尽可能接近输入(一种简单的自监督学习任务)。可视化:绘制注意力矩阵,展示模型对不同词语的关注程度。
03、自注意力机制详解
自注意力机制的核心思想
自注意力是Transformer模型的核心组件,用于捕捉序列中元素(词、字符等)之间的关系。
其核心思想是:
每个输入元素(如词)同时扮演查询(Query)、键(Key)和值(Value)三个角色。通过计算查询与键的相似度,生成注意力权重,决定每个元素对其他元素的关注程度。使用注意力权重对值进行加权求和,生成上下文感知的表示。
数学公式:
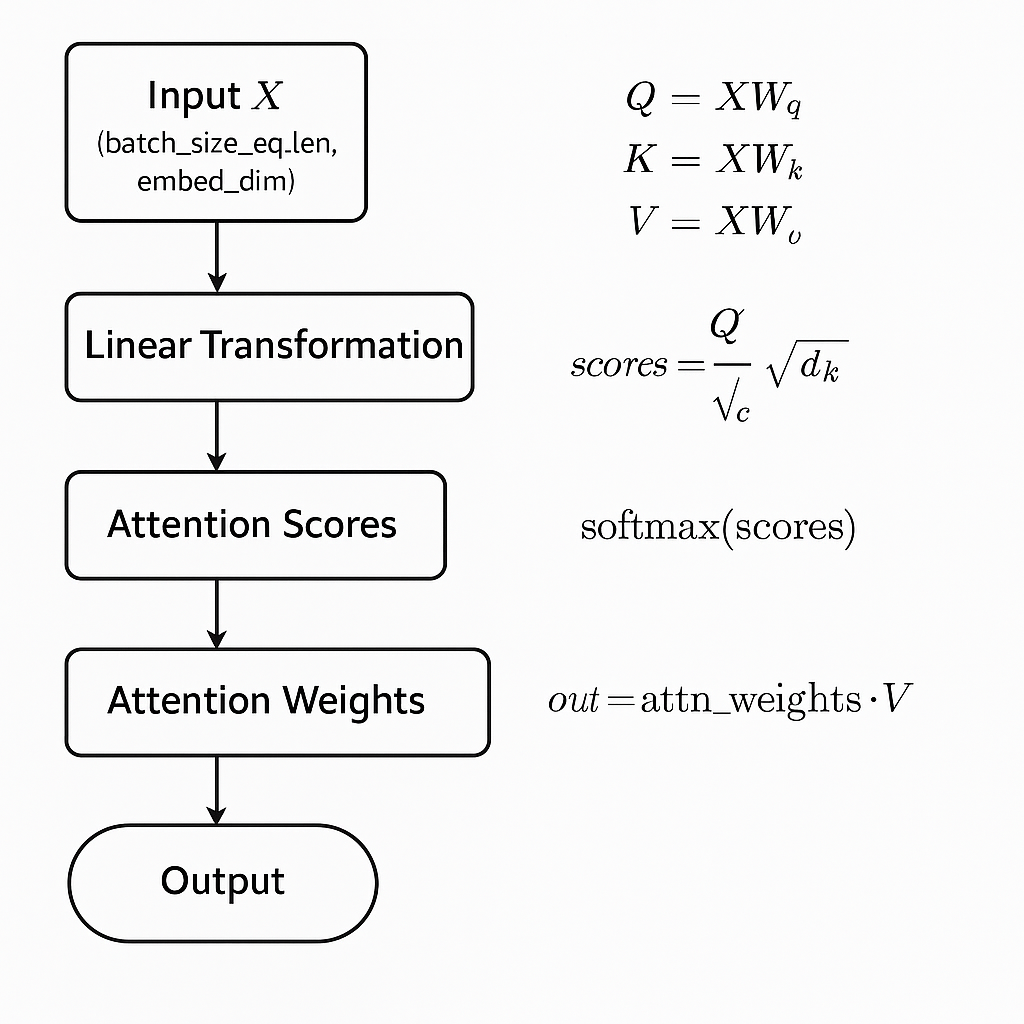
# ONE
训练权重的作用:
在训练过程中,自注意力机制的权重(W_q, W_k, W_v, W_out)通过优化器更新,目标是使模型输出尽可能接近输入(MSE损失)。
具体作用:
学习语义关系:通过调整W_q和W_k,模型学习词之间的语义关联。例如,“写”和“代码”可能有较高的注意力权重,因为它们在语义上相关。
增强表示:通过W_v和W_out,模型生成更丰富的上下文表示,捕捉句子中词语的相互影响。
动态关注:注意力权重是动态计算的,允许模型根据输入内容灵活调整关注重点。
通过深入剖析自注意力机制及其可训练权重的核心作用,我们揭开了大模型处理复杂任务时那份“魔力”的关键一角。自注意力以其独特的方式,让模型能灵活聚焦于输入序列中的重要信息,大幅提升了上下文理解的能力。但这只是开端。在下一章,我们将进一步探讨多头注意力机制,看它如何通过并行处理多组注意力,为模型带来更强的表达力和灵活性。


