随着预训练的大型文本到图像扩散模型的发展,越来越多的企业和个人开发者开始探索如何通过少量样本对这些模型进行定制化,以生成特定的对象或风格。
但这种定制化过程面临着一个严峻的挑战:当训练样本数量有限时,模型往往会过度拟合训练数据的背景和位置信息,导致生成的图像缺乏多样性和灵活性。
为了解决这一难题,来自 AIRI 和 HSE 大学的研究团队提出了一种名为 T-LoRA 的新框架,旨在通过单张图像对扩散模型进行定制化,同时避免过度拟合的问题。

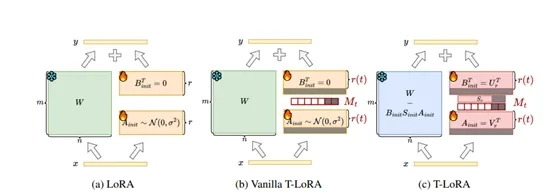
T-LoRA框架的核心在于动态调整模型在不同时间步的训练能力,以及通过一种特殊的方式初始化模型的参数,从而确保模型在训练过程中能够更好地学习和生成新的图像。
在扩散模型中,生成图像的过程可以想象成是从一片噪声中逐步恢复出目标图像的过程。这个过程被分成多个时间步,每个时间步都对应着不同程度的噪声。在早期时间步高噪声阶段,模型主要负责生成图像的大致轮廓和形状;而在后期时间步低噪声阶段,模型则专注于细节的完善。
T-LoRA的一个关键创新是动态调整模型在不同时间步的训练能力。在高噪声阶段,T-LoRA 会减少模型对训练数据的依赖;而在低噪声阶段后期时间步,则会增加模型对训练数据的依赖。这样做的目的是在高噪声阶段避免模型过度记忆训练图像的背景和位置信息,从而提高生成图像的多样性和灵活性;而在低噪声阶段,模型可以更好地学习和复现目标图像的细节。
为了实现这一点,T-LoRA 引入了一种掩码机制,可以根据当前的时间步动态调整模型的参数更新。在高噪声阶段,模型的参数更新会受到限制,而在低噪声阶段,模型的参数更新则会更加自由。这种动态调整的方式就像是给模型的训练过程安装了一个“调节阀”,使其在不同的时间步有不同的学习强度。
除了动态调整训练能力,T-LoRA 还引入了一种特殊的参数初始化方法,称为正交初始化。参数初始化是模型训练的一个重要环节,它决定了模型的参数在训练开始时的初始值。如果初始化不当,可能会导致模型训练缓慢,甚至无法收敛。
在 T-LoRA 中,正交初始化技术的作用是确保模型在不同时间步的学习过程中,各个参数之间的信息流是相互独立的。这样可以避免参数之间的冗余和相互干扰,提高模型的学习效率和泛化能力。
正交初始化是通过一种特殊的数学方法来实现的。这种方法可以将模型的参数分解成几个相互独立的部分,然后对这些部分进行初始化。这样做的好处是,模型在训练过程中可以更有效地利用这些参数,避免因为参数之间的冗余而导致的训练问题。
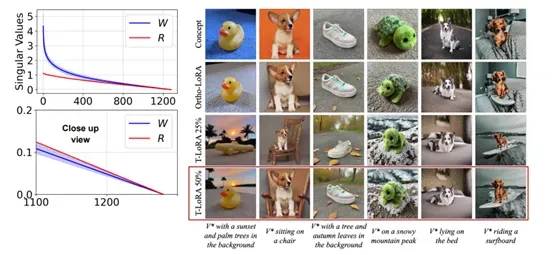
为了验证 T-LoRA 的有效性,研究人员进行了广泛的实验。实验结果显示,T-LoRA 在图像相似度和文本相似度两个指标上均表现出色。与传统的 LoRA 方法相比,T-LoRA 在高秩情况下例如,秩为 64的文本相似度提高了 0.024,而图像相似度仅下降了 0.001。这表明 T-LoRA 在保持图像概念准确性的同时,显著提高了生成图像与文本提示的一致性。
除了单图像实验外,研究人员还评估了 T-LoRA 在多图像定制化任务中的表现。实验结果表明,T-LoRA 在多图像情况下同样优于 LoRA 和 OFT 等方法。特别是在使用两张图像进行训练时,T-LoRA 的文本相似度比 LoRA 高出 0.031,而图像相似度仅下降了 0.001。
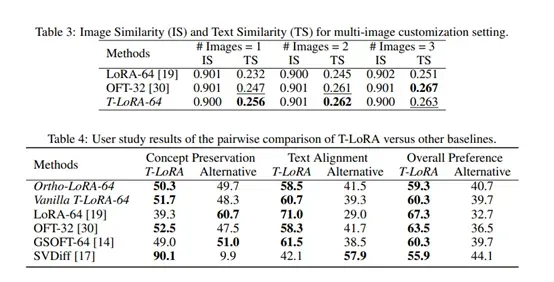
为了全面评估 T-LoRA 的性能,研究人员还进行了用户研究。结果显示,用户更倾向于选择T-LoRA 生成的图像,认为这些图像在保持概念准确性的同时,更好地符合文本提示的要求。具体来说,在概念准确性方面,T-LoRA 的用户偏好率达到 59.3%;在文本一致性方面,用户偏好率达到 60.3%;在整体偏好方面,用户偏好率达到 60.3%。


