
大家好,我是肆〇柒。在长篇小说和叙事文本的理解领域,一个核心挑战始终存在:如何让AI系统像人类一样,不仅捕捉离散的线索,还能构建和更新对复杂情节线和动态演变的角色关系的连贯理解?传统检索增强生成(Retrieval-Augmented Generation, RAG)方法虽然在长上下文处理中扮演重要角色,但其"无状态"的单步检索过程往往导致对矛盾证据的整合失败,产生浅层理解。本文将介绍一种创新性的解决方案——ComoRAG,一种受认知科学启发的记忆组织式RAG系统,它通过模拟人类大脑的前额叶皮层功能,实现了状态式推理。
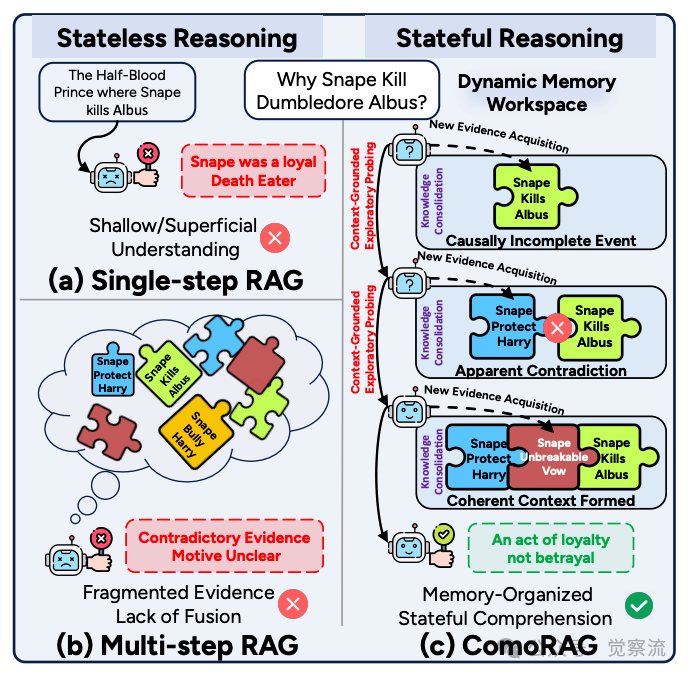
RAG推理范式比较
如上图所示,单步RAG(a)和多步RAG(b)均属于"无状态推理"(Stateless Reasoning)范畴,它们的推理过程不依赖于或无法有效利用先前的探索状态。而ComoRAG(c)则实现了"有状态推理"(Stateful Reasoning),其推理状态是持续演化的。这种根本区别构成了ComoRAG解决叙事理解挑战的理论基础。
从"背叛"到"忠诚":叙事理解的挑战
长叙事理解的核心挑战在于其错综复杂的情节线和纠缠交织、且常常动态演变的角色与实体关系。与简单的多跳问答不同,叙事理解需要的是一种动态认知综合能力——持续构建和修订对情节、角色及其演变动机的全局心智模型。
这种能力在经典叙事问题"Snape为何杀死Dumbledore?"中体现得淋漓尽致。在《哈利·波特》系列中,斯内普教授(Snape)长期以来一直被描绘成一个阴险、偏爱斯莱特林学院、并处处与主角哈利·波特作对的反派角色。然而,在故事的最终章,他却做出了一个震惊所有人的举动:在邓布利多教授(Dumbledore)身患绝症、力量衰弱之时,亲手杀死了他。
这个行为在当时看来是彻头彻尾的背叛,与他此前作为"忠诚食死徒"的形象相符。但要真正理解这一行为,读者必须整合贯穿整个系列的、看似矛盾的线索:首先,邓布利多早已知道自己命不久矣;其次,他与斯内普之间曾立下过一个名为"不可饶恕咒约"(Unbreakable Vow)的魔法契约,这使得斯内普无法违抗他的命令;最后,也是最关键的,斯内普内心深藏着对哈利母亲莉莉的忠诚与爱,这份情感驱使他一生都在暗中保护哈利。
这些线索的真实意义只有在故事完结、所有信息揭晓后才能完全调和。因此,"Snape为何杀死Dumbledore?"这个问题的答案,并非一个简单的事实,而是一个需要将"表面的背叛"重构为"深层次的忠诚"的认知过程。这正是"状态式推理"的明确定义:它要求系统不仅链接静态证据,还需维护一个动态的叙事记忆,随新发现不断更新,形成连贯的上下文理解。与多跳问答中静态路径不同,状态式推理要求系统能够像人类一样,随着阅读进程不断修正和丰富对故事的理解。
传统RAG方法在处理这类问题时面临"无状态"局限性。单步检索往往只能获取片段化证据,无法整合矛盾信息。以"Snape杀死Dumbledore"为例,单步RAG可能检索到"Snape是忠诚食死徒"和"Snape杀死Dumbledore"的证据,却无法将这些与"Snape保护Harry"的矛盾证据融合,导致错误推断。
状态式推理的明确定义:"有状态的推理"可不是把一堆静态证据串起来就完事了;它得跟上故事线的节奏,不断更新自己的"记忆",新线索一冒出来就立刻刷新。这一定义强调了叙事理解不仅需要链接静态证据,还需维护一个动态的叙事记忆,随新发现不断更新,形成连贯的上下文理解。与多跳问答中静态路径不同,状态式推理要求系统能够像人类一样,随着阅读进程不断修正和丰富对故事的理解。
传统RAG方法在处理这类问题时面临"无状态"局限性。单步检索往往只能获取片段化证据,无法整合矛盾信息。以《哈利·波特》"Snape杀死Dumbledore"为例,单步RAG可能检索到"Snape是忠诚食死徒"和"Snape杀死Dumbledore"的证据,却无法将这些与"Snape保护Harry"的矛盾证据融合,导致错误推断。
推理阻塞机制的关键作用:ComoRAG通过"推理阻塞"(reasoning impasse)机制解决了这一挑战。当Try-Answer无法形成确定答案时,系统发出Failure Signal,这标志着系统遭遇了"推理阻塞"(reasoning impasse)。正是这个信号,触发了元认知循环,开始主动探索新证据路径。这一机制使系统能够从"因果不完整事件"(Snape杀死Albus)逐步发展到"表面矛盾"(发现Snape保护Harry),最终形成"逻辑一致上下文"(理解这是因不可饶恕咒约而采取的忠诚行动)。这种演化过程正是人类理解复杂叙事的自然方式。
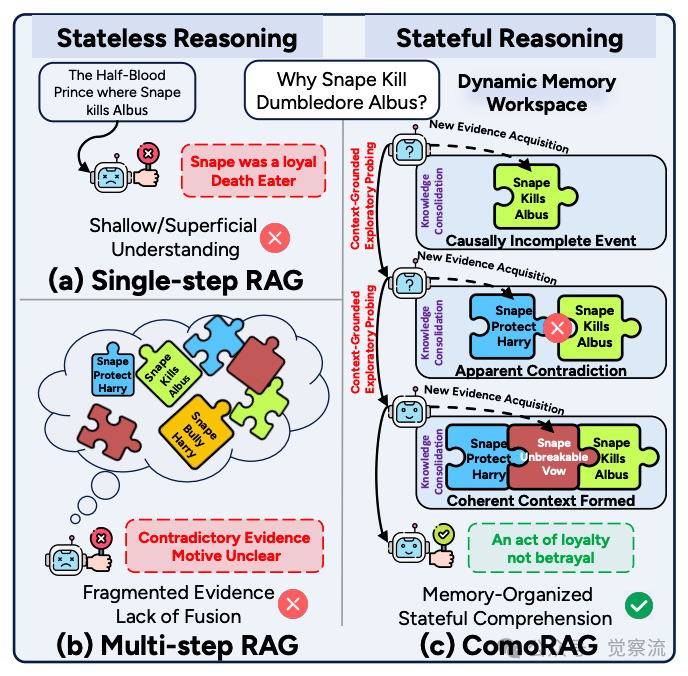
如上图所示,三种RAG推理范式的对比清晰展示了ComoRAG的独特优势。单步RAG(a)仅提供浅层理解,无法整合矛盾证据;多步RAG(b)虽获取更多证据但缺乏连贯推理,仍导致"动机不明";而ComoRAG(c)通过动态记忆工作区整合碎片证据,形成连贯上下文,最终得出"忠诚而非背叛"的正确理解。这一认知启发的设计实现了从静态检索到状态式认知推理的范式转变,为长叙事理解开辟了新路径。
问题定义
叙事理解与多跳问答(Multi-hop Question Answering, QA)有着本质区别。多跳QA寻求在固定事实间建立静态路径,而叙事理解则需要持续构建和修订对情节、角色及其演变动机的全局心智模型。以"Snape为何杀死Dumbledore?"为例,正确理解需要整合跨书线索——Dumbledore的绝症、不可饶恕咒约和Snape隐藏的忠诚——这些线索的真实意义只有在回顾时才能完全调和。这种能力正是"状态式推理"的核心:不仅需要链接静态证据,还需维护一个动态的叙事记忆,随新发现不断更新,形成连贯的上下文理解。
人类认知过程为解决这一挑战提供了关键启示。前额叶皮层(Prefrontal Cortex, PFC)执行一种称为"元认知调节"(Metacognitive Regulation)的复杂推理过程。这一过程不是单一行动,而是新证据获取与知识整合之间的动态交互。在这一过程中,目标导向的记忆探查(goal-directed memory probes)驱动新证据获取,随后将新发现与过去信息整合,构建不断演化的连贯叙事。这种迭代循环使PFC能够持续评估理解状态并调整策略。
现有RAG方法在应对这一挑战时存在明显局限。单步RAG方法(如RAPTOR和HippoRAGv2)虽然增强了检索索引,但仍依赖单次静态检索,导致浅层理解。例如,RAPTOR通过聚类和摘要文本块在不同细节层次上检索;HippoRAGv2模仿人类海马体构建知识图谱实现单步多跳推理。然而,这些方法无法解决"Snape保护/欺凌Harry"等矛盾证据的整合问题。
多步RAG方法(如IRCoT、Self-RAG和MemoRAG)提供了更有希望的方向,但其检索步骤通常是相互独立的,缺乏贯穿明确叙事进展的连贯推理,导致碎片化证据和无状态理解。由于缺乏动态记忆,多步检索无法整合矛盾证据,无法理解角色行为的演变,最终无法得出正确答案。
推理阻塞的触发机制:ComoRAG的关键创新在于其能够检测推理阻塞并触发元认知循环。当Try-Answer无法确定答案时,系统发出Failure Signal,启动Self-Probe生成新的探索性查询。这一机制解决了叙事理解中从"因果不完整"到"逻辑一致"的转变需求,使系统能够像人类一样,通过动态交互逐步构建完整理解。推理阻塞不仅是一个失败信号,更是系统深入探索叙事线索的契机,驱动系统从表面理解走向深度认知。
ComoRAG架构解析
ComoRAG的核心创新在于其认知启发的架构设计,该设计直接模仿前额叶皮层的功能机制,由三个概念支柱构成:层次化知识源、动态记忆工作区和元认知控制循环。
层次化知识源:三维度认知框架
ComoRAG首先构建了一个层次化知识索引,从三个互补的认知维度建模原始文本,类似于PFC如何从大脑不同区域整合不同类型的记忆。
真实层(Veridical Layer):作为事实证据基础,真实层由直接的原始文本块组成,类似于人类记忆中对事实细节的精确回忆。为确保推理可追溯至源证据,系统指示LLM为每个文本块生成知识三元组(subject-predicate-object)。这些三元组参与每次检索,强化查询与对应文本块的匹配,已被证明能有效提升检索准确性(类似HippoRAG方法)。真实层为叙事理解提供了坚实的事实基础,是解决"Snape杀死Dumbledore"等复杂问题的关键起点。
语义层(Semantic Layer):为捕捉超越长距离上下文依赖的主题和概念联系,语义层采用GMM驱动的聚类算法,递归总结语义相似的文本块,形成层次摘要树。这一设计借鉴了RAPTOR的工作,使框架能够检索超越表面层次的概念信息。语义层使系统能够理解"Snape的忠诚"这一抽象概念,而非仅停留在具体事件层面。
情节层(Episodic Layer):前两层提供了事实细节和高级概念的视角,但缺乏对叙事中至关重要的时序发展或情节进展的捕捉。情节层通过滑动窗口摘要机制重构情节线和故事弧线,捕获按时间线连续或因果相关事件的序列叙事发展。窗口大小根据文档长度动态调整:

情节层使系统能够理解"Snape保护Harry"与"Snape杀死Dumbledore"之间的时间顺序和因果关系,这是解决叙事矛盾的关键。
动态记忆工作区:状态式推理的核心
动态记忆工作区是ComoRAG实现状态式推理的核心,它包含记忆单元,作为元认知调节进行连贯多步探索和推理的桥梁。

元认知控制循环:认知启发的推理引擎
元认知控制循环是ComoRAG的心脏,完全实现了元认知调节的概念。它由监管过程(Regulatory Process)和元认知过程(Metacognitive Process)组成,形成一个闭环的演化推理状态系统。


这五个操作——从Self-Probe生成新探针,到Tri-Retrieve获取证据,Mem-Encode形成记忆,Mem-Fuse整合新旧知识,Try-Answer尝试解答,再到Mem-Update更新记忆池——共同构成了一个完整的、自我迭代的认知循环。当Try-Answer失败时,系统会利用更新后的记忆池再次启动Self-Probe,从而形成一个不断演化的推理状态闭环,如下图所示。
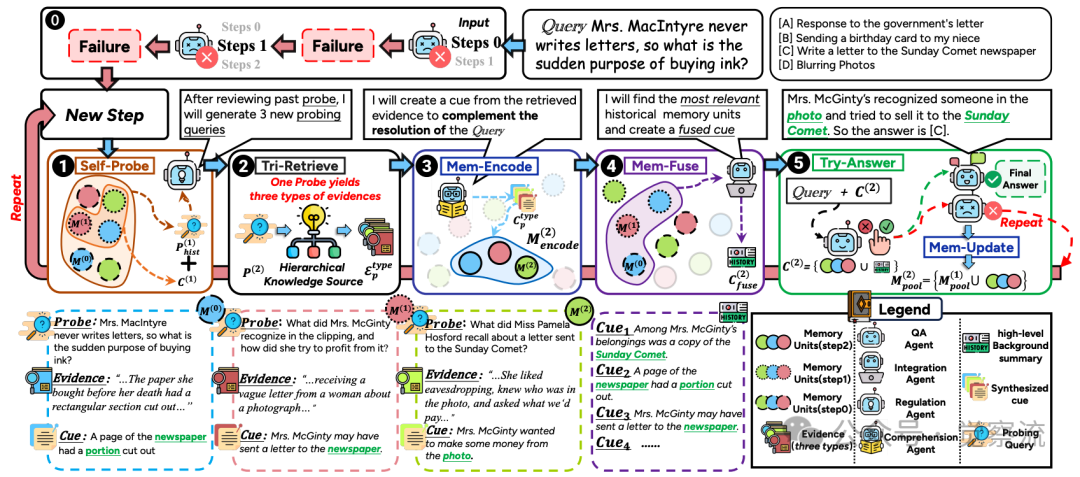
ComoRAG架构示意图
上图展示了ComoRAG的工作流程。与传统RAG不同,ComoRAG形成了一个闭环系统:当遇到推理阻塞(Failure)时,系统不是简单地放弃或重复检索,而是通过Self-Probe生成新的探索性探针,Tri-Retrieve获取新证据,Mem-Encode形成记忆单元,Mem-Fuse整合新旧记忆,最终通过Try-Answer尝试解答。这一闭环使系统能够像人类一样,通过迭代探索逐步构建完整理解。
算法伪代码:
为了更精确地描述ComoRAG的完整工作流程,可以参考其核心算法的伪代码实现,如下图所示:

ComoRAG 算法伪代码
该算法清晰地定义了从初始查询到最终答案的完整迭代过程,包括初始检索、失败判断、以及后续由Self-Probe、Tri-Retrieve、Mem-Encode、Mem-Fuse、Try-Answer和Mem-Update构成的闭环元认知循环。
实验结果分析
ComoRAG在四个长叙事理解数据集上进行了全面评估,包括NarrativeQA(58k tokens)、EN.QA(200k+ tokens)、EN.MC(200k+ tokens)和DetectiveQA(100k+ tokens)。所有方法均使用GPT-4o-mini作为LLM骨干,以确保公平比较。
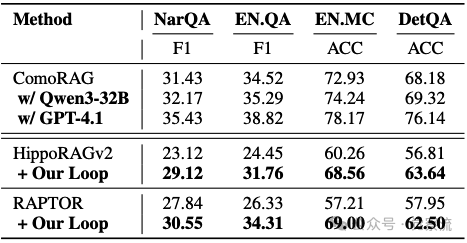
性能对比:实验结果表明,ComoRAG在所有数据集上持续超越强基线,相对提升高达11%。特别是在EN.MC和EN.QA这两个超长上下文数据集上,优势更为明显。即使使用轻量级的0.3B BGE-M3进行检索,ComoRAG也显著优于使用更大嵌入模型的RAG方法。
消融实验:对EN.MC和EN.QA数据集的消融研究结果揭示了各组件的重要性:
- 移除真实层导致性能下降约30%,证实了"Veridical Layer provides the basis for factual-grounded reasoning"
- 移除语义层或情节层导致准确率下降约8%,显示了抽象与叙事流的价值
- 移除元认知过程(禁用记忆工作区)导致F1分数下降22%,准确率下降15%
- 移除监管过程导致准确率下降24%,F1分数下降19%
- 同时移除两者使系统退化为单次解析器,性能大幅下降
这些结果证实了ComoRAG的增强源于记忆整合与动态证据探索的协同作用,而非单一组件的改进。
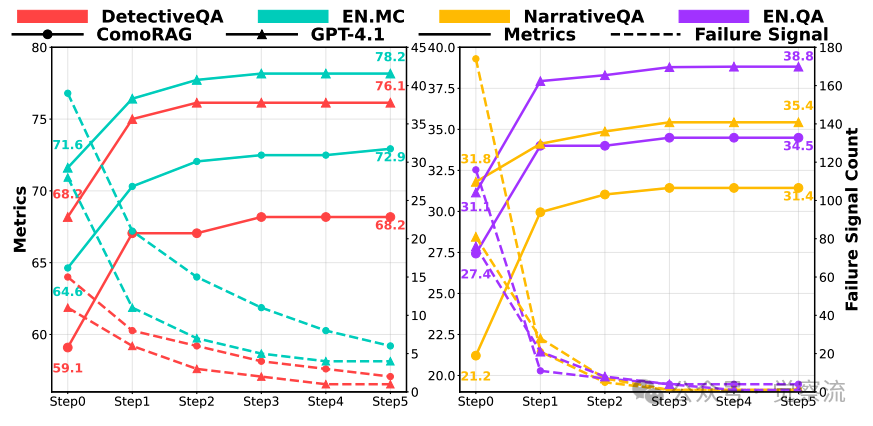
迭代探测带来的性能提升。GPT-4.1 使用更强大的 GPT-4.1 作为 LLM(大型语言模型)智能体参与 ComoRAG 评估(而不是使用 GPT-4o-mini)
迭代效率的量化分析:如上图显示,性能提升主要发生在前2-3轮循环内,这与研究指出的"大部分改进发生在2到3个周期内"一致。这一发现具有重要实践意义:系统不需要进行过多迭代即可达到最佳性能,平衡了计算效率与推理深度。超过3轮后,性能提升趋于平缓,表明系统已基本整合了关键证据。
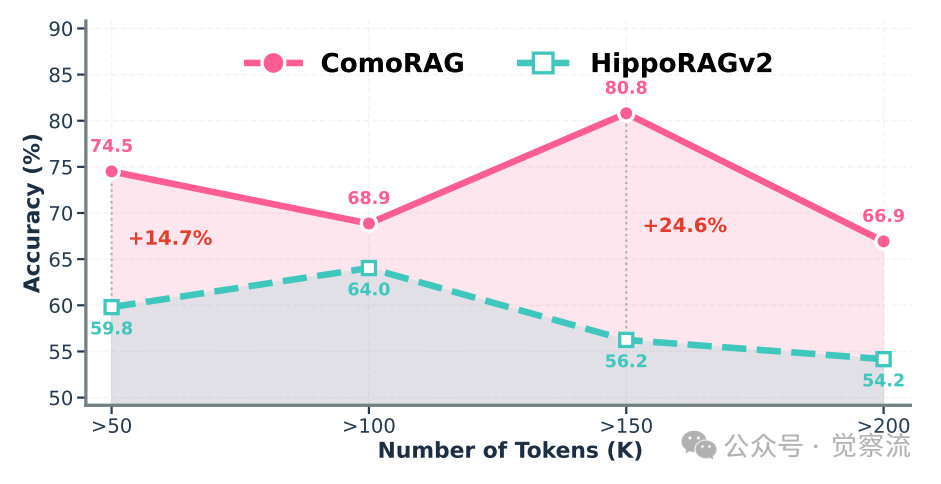
在多选数据集上,不同文档长度的平均准确率。ComoRAG在长文本上下文中比基线模型表现得更加稳健
超长文档性能优势:上图展示了不同文档长度上的平均准确率。ComoRAG对长上下文表现出更强的鲁棒性,而HippoRAGv2随着文档增长性能显著下降。对于超过150k tokens的文档,准确率差距峰值达到+24.6%,突显了状态式多步推理对超长连贯上下文的重要性。这一结果验证了“静态瓶颈”假设,即单步检索在超长文档中的效果有限,而状态式推理能够有效克服这一瓶颈,这突出了在长篇连贯文本中进行查询解析时,状态式多步推理的重要性。
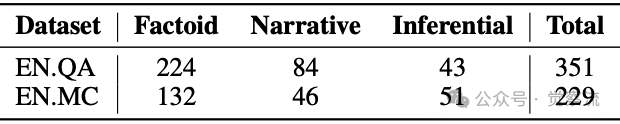
查询类型差异化表现:基于上表的详细数据(EN.QA: 224 factoid, 84 narrative, 43 inferential; EN.MC: 132 factoid, 46 narrative, 51 inferential),以下两图展示了按查询类型分类的性能分析:
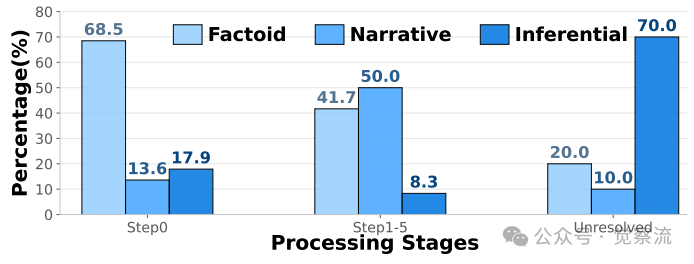
- 事实型查询(如"What religion is Octavio Amber?")占初始解决方案的60%以上,单步检索即可解决
- 叙事型查询(如"Where does Trace choose to live at the end of the novel?")占24-25%,需要理解情节进展
- 推理型查询(如"What is the main reason that Nils first visits Aiden in his apartment?")占12-22%,需要理解隐含动机
按处理阶段划分的已解决问题类型的分布
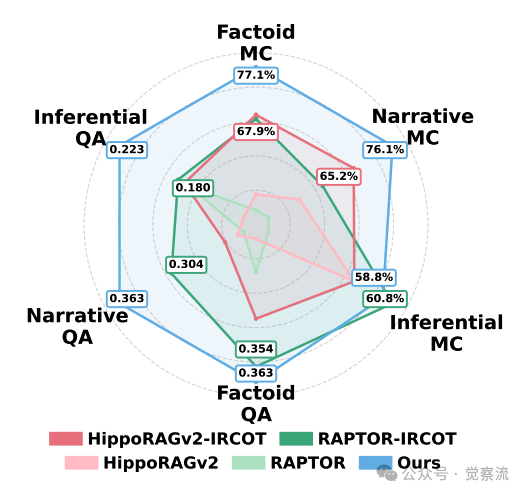
针对不同查询类型的RAG方法性能评估
关键发现是,近50%的问题(叙事型和推理型查询)只能通过元认知循环解决。ComoRAG在这些复杂查询上表现尤为出色,在叙事型查询上实现EN.QA上19%的相对F1提升和EN.MC上16%的准确率增益。这一结果验证了"ComoRAG 尤其擅长处理那些需要整体把握、全局理解的复杂查询"的结论。
模型泛化能力:通过将GPT-4o-mini替换为GPT-4.1,EN.QA的F1分数从34.52提升至38.82,EN.MC的准确率从72.93%提升至78.17%,展示了模型无关的泛化能力。此外,ComoRAG的元认知循环可作为插件无缝集成到现有RAG方法中,与RAPTOR集成带来21%的准确率提升,与HippoRAGv2集成带来8.3%的提升,证明了其模块化和通用性。
案例研究:叙事推理实例
为了深入理解ComoRAG的工作机制,我们分析一个具体案例。该案例选自DetectiveQA数据集,这是一个专门用于评估长篇侦探小说推理能力的基准。在此类任务中,模型需要像侦探一样,从分散在数十万字文本中的微小线索出发,通过逻辑推理,解决一个核心谜题。
案例背景与任务:故事中,Mrs. MacIntyre是一位从不写信的女性。然而,情节中出现了一个关键的反常行为:她突然购买了墨水。这个行为与她一贯的习惯形成了"表面矛盾",构成了一个需要解释的谜团。我们的任务是回答这个核心问题:"Mrs. MacIntyre从不写信,为何突然买墨水?" 选项包括:
[A] 回复政府信件[B] 给侄女寄生日卡[C] 给Sunday Comet报纸写信[D] 模糊照片。
正确解答需要将这个孤立的"买墨水"行为,与故事中其他分散的线索联系起来,构建一个完整的证据链。
初始状态:单步检索仅找到"报纸有部分被剪掉"的模糊线索,不足以形成答案,触发Failure Signal。标准单步RAG只能找到关于“剪报”的模糊线索,这不足以形成一个完整的答案,因此无法确定正确选项。
Step 1:
- Self-Probe生成探针:"What did Mrs. McGinty recognize in the clipping, and how did she try to profit from it?"
- Tri-Retrieve获取证据:Miss Pamela Hosford在Sunday Comet的角色,她回忆收到一封关于照片的模糊信件
- Mem-Encode形成线索:
a.Key Finding: Mrs. McGinty usually had Joe help her reply to letters
b.Key Finding: Mrs. McGinty may have sent a letter to the newspaper
c.仍无法确定具体目的,继续循环
Step 2:
- Self-Probe生成新探针:"What did Miss Pamela Hosford recall about a letter sent to the Sunday Comet, and what might it imply about Mrs. McGinty?"
- Tri-Retrieve获取新证据:她喜欢偷听,知道照片中的人,并询问"we'd pay"
- Mem-Encode形成线索:
a.Key Finding: Mrs. McGinty wanted to make some money from the photo
- Mem-Fuse整合历史线索,形成完整理解
- Try-Answer确定答案:[C] Write a letter to the Sunday Comet newspaper
记忆状态演化路径:系统从初始的"因果不完整事件"(买墨水但不写信)发展到"表面矛盾"(为何买墨水?),最终形成"逻辑一致上下文"(认出照片中的人,想卖故事给报纸)。这一演化过程使系统能够构建完整的证据链:Mrs. McGinty认出照片中的人,想卖故事赚钱,因此需要写信给报纸,这解释了为何通常不写信的她突然购买墨水。
与传统方法的对比:
- 单步RAG:只能获取零散线索,无法形成完整证据链
- 多步RAG:虽获取更多证据但缺乏整合,仍无法解答
- ComoRAG:通过记忆工作区整合碎片证据,形成连贯理解,最终得出正确答案

如上案例研究清晰展示了关键证据(蓝色标记)和关键线索(橙色标记)如何共同支持正确答案。关键证据包括"报纸被剪掉部分"、"Mrs. McGinty认出照片中的人"和"询问报酬";关键线索则是这些证据如何共同指向"写信给报纸"的目的。这种证据-线索的对应关系是ComoRAG成功的关键机制。
实践指南
对于希望在实际应用中采用ComoRAG的盆友,以下关键实践指南值得关注:
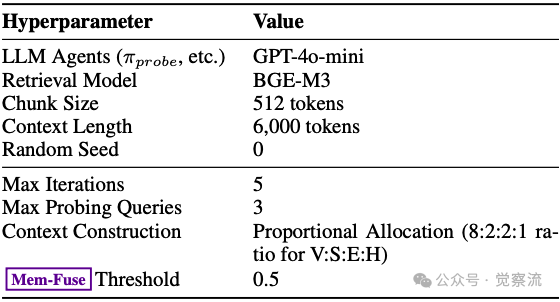
关键超参数配置依据:基于上表的详细设置:
- 最大迭代次数设为5轮:实验表明,大部分改进发生在2到3个周期内,设置5轮作为上限确保系统有足够探索空间,同时避免过度计算
- 每轮生成最多3个探测查询:平衡效率与全面性,避免冗余同时确保多角度探索
- 上下文长度限制为6k tokens:与所有RAG基线一致,适应主流LLM的上下文窗口
- 证据比例分配采用8:2:2:1(真实性证据:语义证据:情景证据:历史证据):这一比例基于消融实验,"真实层为基于事实的推理提供了基础",而其他层提供必要的抽象和叙事流补充
- "Mem-Fuse阈值"设为0.5:表示转发到Integration Agent进行记忆融合的证据比例,这一设置平衡了新旧证据的权重
与现有RAG系统的集成方法:ComoRAG的核心优势在于其模块化设计。实践者可以:
1. 保留原有索引结构:继续使用RAPTOR的语义摘要树或HippoRAGv2的知识图谱
2. 替换推理引擎:将ComoRAG的元认知循环作为插件替换原RAG系统的推理引擎
3. 增加记忆工作区:在现有系统中添加动态记忆池组件,存储和整合历史探索
具体集成步骤为:"将ComoRAG的元认知循环作为插件集成到现有RAG框架中,保留原有索引结构但增加记忆工作区组件,使系统能够跟踪和整合多轮推理状态"。如下表实验结果证实,这种集成方式与RAPTOR结合带来21%的准确率提升,与HippoRAGv2结合带来8.3%的提升。
适用场景判断:ComoRAG特别适合需要全局情节理解的叙事型查询,如文学分析、侦探小说推理或长篇法律文档解析。对于简单事实型查询,传统单步RAG可能已足够。资源考量方面,ComoRAG的计算成本略高于单步RAG(主要来自多轮推理),但显著低于处理全上下文的LLM,提供了性能与效率的良好平衡。特别适合处理200k+ tokens的长文档,其中对于超过15万token的长文档,准确率优势达到峰值,高出 24.6个百分点。
未来发展
ComoRAG的成功为RAG领域开辟了多个有前景的未来方向:
模型无关的泛化能力扩展:实验证明,与更强LLM(如GPT-4.1)集成可进一步提升性能。未来可探索优化轻量级模型上的表现,降低计算成本,使状态式推理更广泛可用。素材中数据显示,使用GPT-4.1作为LLM代理可将EN.MC准确率从72.93%提升至78.17%,表明以更强的大模型作为骨干智能体,可全面提升整个认知闭环的推理水平。
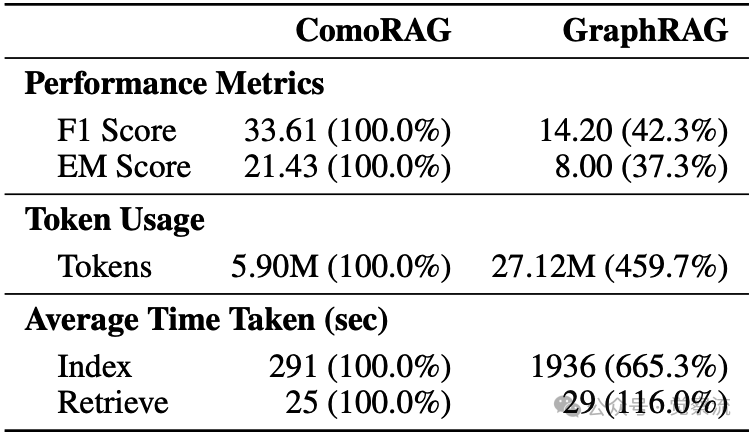
ComoRAG和GraphRAG的性能、Token 使用量及平均时间对比
模块化集成路径:ComoRAG的元认知循环可作为通用插件,无缝集成到各种RAG框架。虽然GraphRAG等结构化方法计算成本高(如上表显示其token使用量是ComoRAG的4.6倍),但其知识图谱表示与ComoRAG的层次化知识源有潜在互补性。未来可重点攻关"ComoRAG 作为即插即用增强模块,如何无缝嵌入现有 RAG 流水线并显著提升其查询处理能力"的具体落地方案。
认知科学启发的下一代RAG:未来,AI 还可进一步"仿脑"——比如借鉴海马体的机制来强化长时记忆,或引入注意力机制来精准筛选关键证据。元认知调节框架为打造更贴近人类思维的系统提供了核心原则,而 ComoRAG 已用这一原则在长文本检索与带状态推理任务上开辟了全新范式,并可泛化到更广泛的认知场景。
应用场景扩展:在长文本处理领域,如叙事理解、法律文档分析、医学记录解读等,ComoRAG的原理具有广泛的适用性。特别是在需要将情节发展或事件进程作为一个连贯的背景语境来理解的场景中,例如医疗记录中对病情发展的分析,或者法律案件中对事件时序的重建,其优势尤为突出。多模态叙事理解(结合文本与图像)也是有前景的扩展方向,可进一步提升系统对复杂叙事的理解能力。
总结
ComoRAG代表了从静态检索到状态式推理的范式转变,通过动态记忆工作区解决了矛盾证据整合问题,其元认知控制循环成功模仿了人类前额叶皮层的功能。在四大长叙事基准测试中,它持续超越各类强基线,特别是在需要全局理解的叙事型查询上实现高达19%的相对F1提升。
技术贡献:ComoRAG的核心贡献在于将RAG从静态检索转变为动态认知循环,通过记忆组织解决了叙事理解中的三个关键挑战:
1. 跨长距离上下文依赖:通过情节层捕捉时序发展
2. 矛盾证据整合:通过记忆工作区融合碎片证据
3. 情节进展理解:通过元认知循环实现状态式推理
实验表明,状态式推理只需2-3轮循环即可高效收敛,这为实际应用提供了可行性,并验证了"认知循环进行正确的状态式推理"的有效性。
应用前景:该技术可应用于多个领域:
- 文学分析:理解复杂角色关系和情节发展
- 法律文档解读:追踪案件事件时序和因果链条
- 医疗记录分析:理解病情发展和治疗历程
- 教育领域:辅助学生理解复杂叙事文本
ComoRAG不仅解决了长叙事理解的技术挑战,更为构建更接近人类认知的AI系统提供了重要思路。它标志着RAG技术从"检索增强"迈向"认知增强"的关键转变,为未来AI系统设计提供了认知科学的宝贵启示。正如研究指出,ComoRAG框架取得成功并非只是泛泛的改进,而是针对叙事性查询类型提供了一种精准且有效的解决方案,这是实现真正叙事理解的基石。这一思路将推动RAG技术向更智能、更人性化的方向持续发展。


