
译者 | 朱先忠
审校 | 重楼
简介
无论你是在准备面试,还是在工作中构建机器学习系统,模型压缩都已成为一项必备技能。在大语言模型(LLM)时代,模型规模越来越大,如何压缩这些模型以使其更高效、更小巧、更易于在轻量级机器上使用,这一挑战从未如此严峻。
在本文中,我将介绍每位机器学习从业者都应该理解和掌握的四种基本压缩技术。我将探讨剪枝、量化、低秩分解和知识蒸馏,每种方法都各有优势。我还将为每种方法添加一些精简的PyTorch代码示例。
模型剪枝
剪枝可能是最直观的压缩技术。其原理非常简单:移除网络的一些权重,可以是随机移除,也可以是移除“不太重要”的权重。当然,在神经网络中,“移除”权重指的是将权重设置为零。
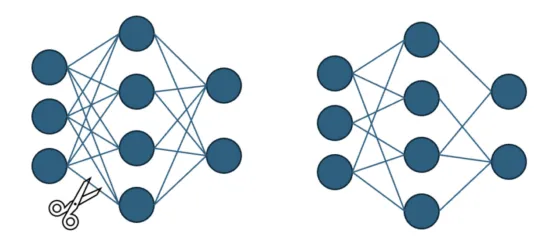
模型修剪(图片来自作者和ChatGPT,创作灵感来自于【引文3】)
结构化与非结构化修剪
让我们从一个简单的启发式方法开始:删除小于阈值的权重。
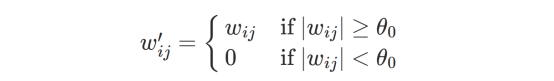
当然,这并不理想,因为我们需要找到一种方法来找到适合我们问题的阈值!更实际的方法是删除某一层中幅度(范数)最小的指定比例的权重。在单层中实现剪枝有两种常见的方法:
- 结构化修剪:删除网络的整个组件(例如,来自权重张量的随机行,或卷积层中的随机通道)。
- 非结构化剪枝:删除单个权重,无论其位置和张量的结构如何。
我们也可以将上述两种方法中的任意一种用于全局剪枝。这将移除多个层中选定比例的权重,并且根据每层参数的数量,移除率可能会有所不同。
PyTorch使这变得非常简单(顺便说一下,你可以在我的GitHub代码仓库中找到所有代码片段)。
复制import torch.nn.utils.prune as prune # 1. 随机非结构化剪枝(随机选取20%的权重) prune.random_unstructured(model.layer, name="weight", amount=0.2) # 2.L1-范数非结构化剪枝(最小权重的20%) prune.l1_unstructured(model.layer, name="weight", amount=0.2) # 3. 全局非结构化剪枝(按L1范数计算,各层权重的40%) prune.global_unstructured( [(model.layer1, "weight"), (model.layer2, "weight")], pruning_method=prune.L1Unstructured, amount=0.4 ) # 4. 结构化修剪(删除L2范数最低的30%行) prune.ln_structured(model.layer, name="weight", amount=0.3, n=2, dim=0)
注意:如果你上过统计学课,你可能学过一些正则化方法,它们也会在训练过程中隐式地使用L0或L1范数正则化来修剪一些权重。修剪与此不同,因为它是作为模型压缩后的一项技术应用的。
剪枝为何有效?彩票假说
基于ChatGPT生成的图像
我想用“彩票假说”来结束本节。它既是剪枝的一个应用,也对移除权重如何能够改进模型进行了有趣的解释。我建议你阅读一下相关论文(引文7)以了解更多详细信息。
论文作者采用了以下程序:
- 训练完整模型,直至收敛
- 修剪最小幅度的权重(例如10%)
- 将剩余权重重置为其原始初始化值
- 重新训练这个修剪后的网络
- 重复该过程多次
重复30次之后,最终得到的参数只有原始参数的0.930(约4%)。令人惊讶的是,这个网络的表现竟然和原始网络一样好。
这表明存在重要的参数冗余。换句话说,存在一个子网络(“彩票”)实际上完成了大部分工作!
结论是:修剪是揭示这个子网络的一种方法。
量化
修剪的重点是完全删除参数,而量化则采用不同的方法:降低每个参数的精度。
请记住,计算机中的每个数字都是以位序列的形式存储的。float32值使用32位(参见下图),而8位整数(int8)仅使用8位。
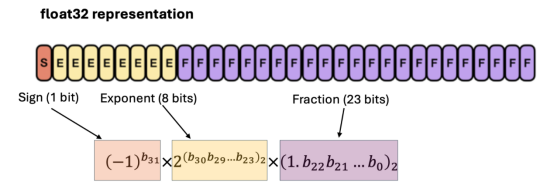
float32数字如何用32位表示的示例(图片来自作者和ChatGPT,创作灵感来自引文2)
大多数深度学习模型都使用32位浮点数(FP32)进行训练。量化会将这些高精度值转换为低精度格式,例如16位浮点数(FP16)、8位整数(INT8),甚至4位表示。
这里的节省是显而易见的:INT8所需的内存比FP32少75%。但是,我们如何在不破坏模型性能的情况下实际执行这种转换呢?
量化背后的数学
要将浮点数转换为整数表示,我们需要将连续的数值范围映射到一组离散的整数。对于INT8量化,我们将其映射到256个可能的值(从-128到127)。
假设我们的权重在-1.0和1.0之间标准化(在深度学习中很常见):
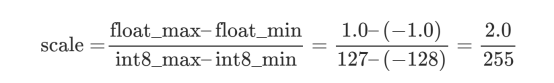
然后,量化值由下式给出:
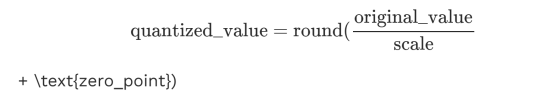
这里,zero_point=0因为我们希望0映射到0。然后,我们可以将这个值四舍五入到最接近的整数,以获得-127到128之间的整数。
而且,你猜对了:为了将整数恢复为浮点数,我们可以使用逆运算:
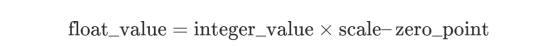
注意:实际上,缩放因子是根据我们量化的范围值确定的。
如何应用量化?
量化可以应用于不同的阶段,并采用不同的策略。以下是一些值得了解的技巧:(下文中的“激活”一词指的是每一层的输出值)
- 训练后量化(PTQ):A.静态量化:离线量化权重和激活(训练之后和推理之前)。B.动态量化:离线量化权重,但在推理过程中动态激活。这与离线量化不同,因为缩放因子是根据推理过程中迄今为止看到的值确定的。
- 量化感知训练(QAT):通过对值进行舍入来模拟训练过程中的量化,但计算仍然使用浮点数进行。这使得模型学习到对量化更具鲁棒性的权重,这些权重将在训练后应用。其底层思想是添加一些“假”操作:x -> dequantize(quantize(x)),这个新值接近x,但仍有助于模型容忍8位舍入和削波噪声。
import torch.quantization as tq
# 1. 训练后静态量化(权重+离线激活)
model.eval()
model.qconfig = tq.get_default_qconfig('fbgemm') # 分配静态量化配置
tq.prepare(model, inplace=True)
# 我们需要使用校准数据集来确定值的范围
with torch.no_grad():
for data, _ in calibration_data:
model(data)
tq.convert(model, inplace=True) # 转换为全int8模型
# 2.训练后动态量化(权重离线,激活实时)
dynamic_model = tq.quantize_dynamic(
model,
{torch.nn.Linear, torch.nn.LSTM}, # layers to quantize
dtype=torch.qint8
)
# 3. 量化感知训练(QAT)
model.train()
model.qconfig = tq.get_default_qat_qconfig('fbgemm') # 设置QAT配置
tq.prepare_qat(model, inplace=True) #插入假量子模块
# [here, train or fine‑tune the model as usual]
qat_model = tq.convert(model.eval(), inplace=False) # 在QAT之后转换为真正的int8量化非常灵活!你可以对模型的不同部分应用不同的精度级别。例如,你可以将大多数线性层量化为8位,以实现最大速度和内存节省,同时将关键组件(例如注意力头或批量规范层)保留为16位或全精度。
低秩分解
现在我们来谈谈低秩分解——一种随着LLM的兴起而流行的方法。
【关键观察点】神经网络中许多权重矩阵的有效秩远低于其维度所暗示的秩。简而言之,这意味着参数中存在大量冗余。
注意:如果你曾经使用过主成分分析(PCA)进行降维,那么你已经遇到过一种低秩近似的形式。主成分分析(PCA)将大矩阵分解为较小、低秩因子的乘积,从而尽可能多地保留信息。
低秩分解背后的线性代数
取权重矩阵W。每个实数矩阵都可以用奇异值分解(SVD)来表示:
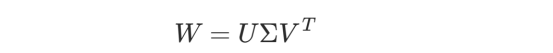
其中Σ是一个奇异值非增阶的对角矩阵。正系数的数量实际上对应于矩阵W的秩。
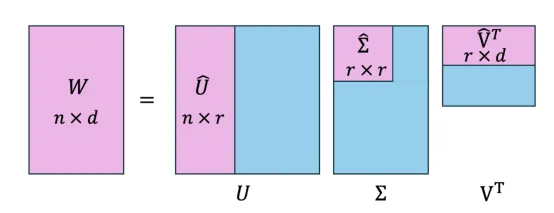
秩为r的矩阵的SVD可视化(图片来自作者和ChatGPT,创作灵感来自引文5)
为了用秩k<r的矩阵近似W,我们可以选择sigma的k个最大元素,以及相应的U和V的前k列和前k行:
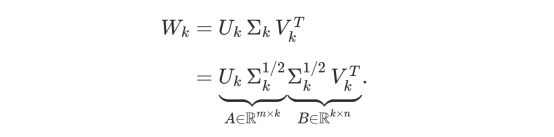
看看新矩阵如何分解为A与B的乘积,现在参数总数是m*k+k*n=k*(m+n)而不是m*n!这是一个巨大的进步,尤其是当k远小于m和时n。
实际上,它相当于用两个连续的线性层x→Wx替换线性层x→A(Bx)。
在PyTorch中
我们可以在训练前应用低秩分解(将每个线性层参数化为两个较小的矩阵——这并非真正的压缩方法,而是一种设计选择),也可以在训练后应用(对权重矩阵应用截断奇异值分解)。第二种方法是迄今为止最常见的方法,如下所示。
复制import torch # 1.提取重量并选择秩 W = model.layer.weight.data # (m, n) k = 64 # 期望的秩 # 2. 近似低秩SVD U, S, V = torch.svd_lowrank(W, q=k) # U: (m, k), S: (k, k), V: (n, k) # 3. 构造因子矩阵A和B A = U * S.sqrt() # [m, k] B = V.t() * S.sqrt().unsqueeze(1) # [k, n] # 4. 替换为两个线性层,并插入矩阵A和B orig = model.layer model.layer = torch.nn.Sequential( torch.nn.Linear(orig.in_features, k, bias=False), torch.nn.Linear(k, orig.out_features, bias=False), ) model.layer[0].weight.data.copy_(B) model.layer[1].weight.data.copy_(A)
LoRA:低秩近似的应用
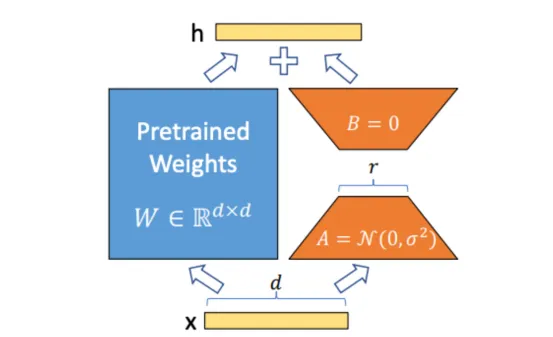
LoRA微调:W是固定的,A和B经过训练(来源:引文1)
我认为有必要提一下LoRA:如果你一直关注LLM微调的发展,你可能听说过LoRA(低秩自适应)。虽然LoRA严格来说不是一种压缩技术,但它因能够有效地适应大型语言模型并使微调非常高效而变得非常流行。
这个想法很简单:在微调过程中,LoRA不会修改原始模型权重W,而是冻结它们并学习可训练的低秩更新:
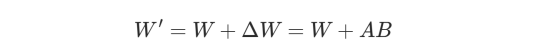
其中,A和B是低秩矩阵。这使得仅使用一小部分参数就可以实现特定任务的自适应。
甚至更好:QLoRA通过将量化与低秩自适应相结合,进一步实现了这一点!
再次强调,这是一种非常灵活的技术,可以应用于各个阶段。通常,LoRA仅应用于特定的层(例如,注意力层的权重)。
知识蒸馏
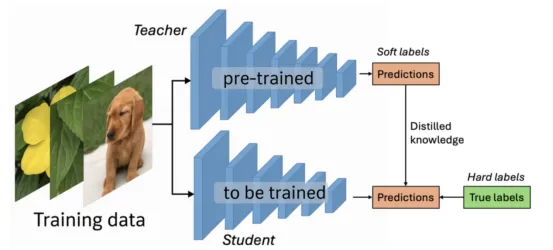
知识蒸馏过程(图片来自作者和ChatGPT,创作灵感来自引文4)
知识蒸馏与我们迄今为止所见的方法截然不同。它不是修改现有模型的参数,而是将“知识”从一个庞大而复杂的模型(“老师”)迁移到一个规模更小、更高效的模型(“学生”)。其目标是训练学生模型模仿老师的行为并复制其表现,这通常比从头开始解决原始问题更容易。
蒸馏损失
我们来解释一下分类问题中的一些概念:
- 教师模型通常是一个大型、复杂的模型,可以在当前任务中取得高性能。
- 学生模型是第二个较小的模型,具有不同的架构,但针对相同的任务进行定制。
- 软目标:这些是教师模型的预测(概率,而不是标签!)。学生模型将使用它们来模仿教师的行为。请注意,我们使用原始预测而不是标签,因为它们也包含有关预测置信度的信息。
- 温度:除了教师模型的预测之外,我们还在softmax函数中使用了一个系数T(称为温度),以便从软目标中提取更多信息。增加T可以柔化分布,并帮助学生模型更加重视错误的预测。
实践中,训练学生模型非常简单。我们将常规损失(基于硬标签的标准交叉熵损失)与“蒸馏”损失(基于教师的软目标)结合起来:
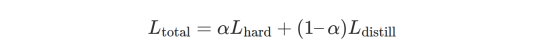
蒸馏损失只不过是教师分布和学生分布之间的KL散度(你可以将其视为两个分布之间距离的度量)。
至于其他方法,可以并且鼓励根据用例调整此框架:例如,还可以比较学生和教师模型之间网络中的中间层的logit和激活,而不仅仅是比较最终输出。
实践中的知识蒸馏
与之前的技术类似,有两种选择:
- 离线蒸馏:预先训练好的教师模型是固定的,并训练一个单独的学生模型来模仿它。这两个模型完全独立,并且在蒸馏过程中教师的权重保持不变。
- 在线蒸馏:两个模型同时训练,知识转移发生在联合训练过程中。
下面是应用离线蒸馏的简单方法(本文的最后一个代码块):
复制import torch.nn.functional as F def distillation_loss_fn(student_logits, teacher_logits, labels, temperature=2.0, alpha=0.5): # 带有硬标签的标准交叉熵损失 student_loss = F.cross_entropy(student_logits, labels) # 软目标的蒸馏损失(KL散度) soft_teacher_probs = F.softmax(teacher_logits / temperature, dim=-1) soft_student_log_probs = F.log_softmax(student_logits / temperature, dim=-1) # kl_div需要将对数概率作为第一个参数的输入! distill_loss = F.kl_div( soft_student_log_probs, soft_teacher_probs.detach(), #不为教师计算梯度 reductinotallow='batchmean' ) * (temperature ** 2) # 可选,缩放因子 #根据公式计算损失 total_loss = alpha * student_loss + (1 - alpha) * distill_loss return total_loss teacher_model.eval() student_model.train() with torch.no_grad(): teacher_logits = teacher_model(inputs) student_logits = student_model(inputs) loss = distillation_loss_fn(student_logits, teacher_logits, labels, temperature=T, alpha=alpha) loss.backward() optimizer.step()
结论
感谢你阅读本文!在LLM时代,由于参数数量高达数十亿甚至数万亿,模型压缩已成为一个基本概念,几乎在每种情况下都至关重要,可以提高模型的效率和易部署性。
但正如我们所见,模型压缩不仅仅是为了减小模型大小,而是为了做出深思熟虑的设计决策。无论是选择在线还是离线方法,压缩整个网络,还是针对特定的层或通道,每种选择都会显著影响性能和可用性。现在,大多数模型都结合了其中几种技术(例如,查看这个模型)。
除了向你介绍主要方法之外,我希望本文还能激发你进行实验并开发自己的创造性解决方案!
不要忘记查看我的GitHub存储库,你可以在其中找到所有代码片段以及本文讨论的四种压缩方法的并排比较。
参考文献
【1】Hu, E.等人,2021。《大型语言模型的低秩自适应》(Low-rank Adaptation of Large Language Models)。arXiv preprint arXiv:2106.09685。
【2】Lightning AI。《使用混合精度技术加速大型语言模型。》(Accelerating Large Language Models with Mixed Precision Techniques)。Lightning AI博客。
【3】TensorFlow博客。《TensorFlow模型优化工具包中的剪枝API》(Pruning API in TensorFlow Model Optimization Toolkit)。TensorFlow博客,2019年5月。
【4】Toward AI。《知识蒸馏的简单介绍》(A Gentle Introduction to Knowledge Distillation)。Towards AI,2022年8月。
【5】Ju, A。《ML算法:奇异值分解(SVD)》(ML Algorithm: Singular Value Decomposition (SVD))。LinkedIn Pulse。
【6】Algorithmic Simplicity。《这就是大型语言模型能够理解世界的原因》(THIS is why large language models can understand the world)。YouTube,2023年4月。
【7】Frankle, J.与Carbin, M。(2019)。《彩票假设:寻找稀疏、可训练的神经网络》(The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks)。arXiv preprint arXiv:1803.03635。
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:Model Compression: Make Your Machine Learning Models Lighter and Faster,作者:Maxime Wolf


