在人们都认为疯狂砸钱,拼命地把大语言模型的参数规模往上堆的Scaling Law已经到头了的时候。一篇叫《递减收益的错觉:衡量LLMs中的长时程执行能力》的论文又给大家来了一剂“强心针”。

这篇报告由剑桥大学、斯图加特大学人工智能研究所、马克斯普朗克智能系统研究所以及图宾根ELLIS研究所的大神们联手发布。他们用一套极其巧妙的实验告诉世界:所谓的“递减收益”很可能只是一种错觉。
研究员们发现:“单步准确度的边际收益可以复合成模型成功完成任务长度的指数级改进。”
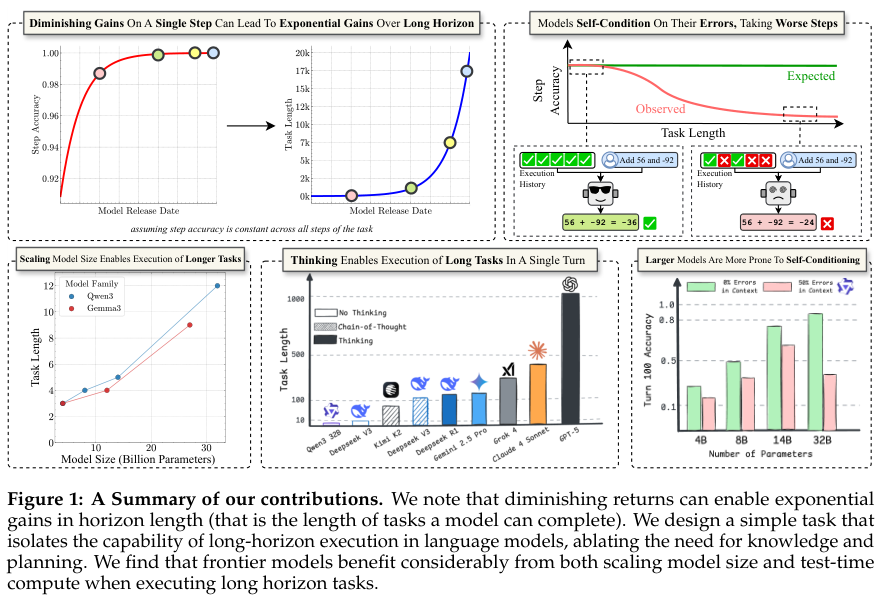
意思就是,你别看模型每次升级,在单个小问题上的准确率就提升那么一丢丢,好像进步慢下来了。但就是这微不足道的“一丢丢”,在处理需要成百上千个步骤的超长任务时,会像滚雪球一样,最终带来指数级的爆炸性提升。
你想想,AI的真正价值是啥?不就是能干活,能干又长又复杂的活嘛。自动驾驶汽车得能跑长途,不能只在停车场里转悠吧?AI助手得能帮你搞定一个完整的项目,而不是只能解决简单任务吧?这种长时间、多步骤连续作战的能力,就是“长时程执行能力”,它一直是深度学习这个领域难啃的骨头,也就是最要命的短板。
我们到底该怎么衡量一个模型到底能连续、可靠地执行多少步操作呢?这篇研究,就是来回答这个灵魂拷问的。
一个简单到极致的实验,却扒了所有模型的秘密
要搞明白AI为啥在长任务上容易“掉链子”,首先得把问题简化。研究团队设计了一个堪称“天才”的实验,这个实验的核心思想就是“控制变量”,把影响模型表现的几个大因素——推理能力、知识储备、规划能力——全都给按住,只留下最纯粹的“执行能力”来考察。
想象你是老板,要测试一个员工执行力。你不会给他一个开放性问题让他自由发挥,而是把任务清单、所有需要的资料、甚至每一步该怎么做都写得清清楚楚,然后跟他说:“来,照着这个做,一字不差地执行就行。”如果这样他还能搞砸,那就不是他聪不聪明的问题,而是他能不能专注、稳定地把一件简单的事情重复做好的问题。
研究团队设计的这个任务叫做“键值字典添加任务”。
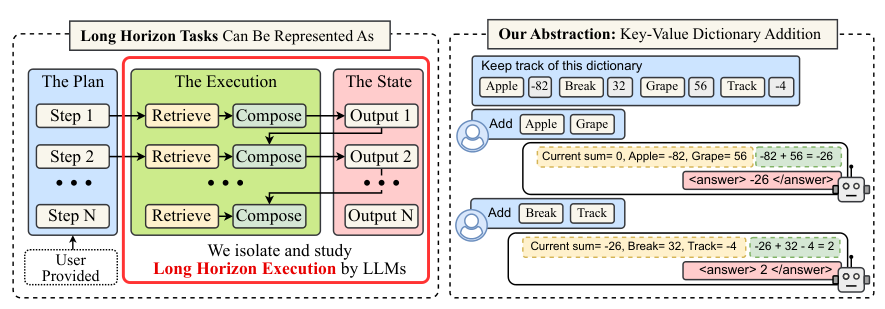
首先,给模型一个“字典”,里面是一堆常见的五个字母的英文单词(比如“apple”、“water”),每个单词对应一个随机的整数(比如-99到99之间)。这个字典就是模型完成任务所需的所有“知识”,直接摆在它面前,不用它去记忆和回忆。
然后,设定一个初始数字,比如0。
接下来,一轮一轮地给模型下指令。每一轮的指令就是几个单词,比如第一轮给“apple”、“grape”。这个指令就是“计划”,也直接告诉模型了,不用它自己想。
模型需要干两件事:第一,去字典里查这两个单词对应的数字是多少,这叫“检索”。第二,把查到的数字加起来,再加到之前的总数上,更新结果,这叫“组合”。比如“apple”是10,“grape”是5,上一轮的总数是0,那这一轮结束,模型就应该算出15。下一轮再给新单词,就在15的基础上继续累加。
这个任务简单到小学生都会。它不需要复杂的推理,不需要广博的知识,甚至连计划都不用自己做。研究团队之所以这么设计,就是为了把所有可能的干扰项都排除掉,就看模型在连续不断的“查找-相加”这种机械操作中,能坚持多久不出错。
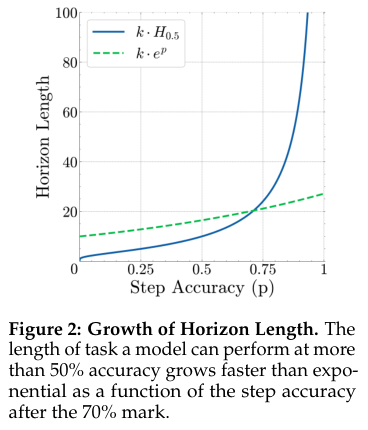
为了衡量模型的表现,他们定义了几个关键指标,就是从不同角度给模型打分。比如“步骤准确度”,就是看每一步加法算对了没;“轮次准确度”,就是看每一轮的总数更新对了没;“任务准确度”,就是从头到尾一次错都没犯的概率;还有一个最重要的指标叫“地平线长度”(Horizon Length,简称Hs),这个名字很酷,意思是,在保证成功率不低于某个值(比如50%)的前提下,这个模型最多能连续执行多少步。地平线长度越长,说明模型越“持久”,越靠谱。
实验团队找来了市面上好几个系列的“当红炸子鸡”模型,比如GPT-5、Claude-4 Sonnet、Grok 4、Gemini 2.5 Pro、Kimi K2、Qwen3-Instruct-235B-2507和DeepSeek R1等。
AI的“自我PUA”和“王者思维”
当实验数据徐徐展开。科学家们发现了几个让人拍案叫绝,又细思极恐的现象。
单步准确率上的一点点进步,到了长任务里就变成了指数级的巨大优势。研究团队甚至给出了一个数学公式来解释:
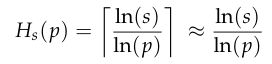
这就好比投资里的复利,每天多赚一点点,时间一长,财富就会爆炸式增长。这完美解释了为什么大家感觉模型进步慢了,但实际上它们能处理的任务越来越复杂。所谓的“递减收益”,不过是因为我们只盯着单步任务这个“活期利息”,而忽略了长时程任务这个“超级复利”罢了。
实验里,除了两个最小的模型,其他所有模型在第一步操作时,准确率都是100%。这说明,它们绝对理解任务,也具备完成任务的能力。但是,随着轮次的增加,哪怕是最牛的模型,在连续执行了15轮这种简单任务后,准确率也掉到了50%以下。
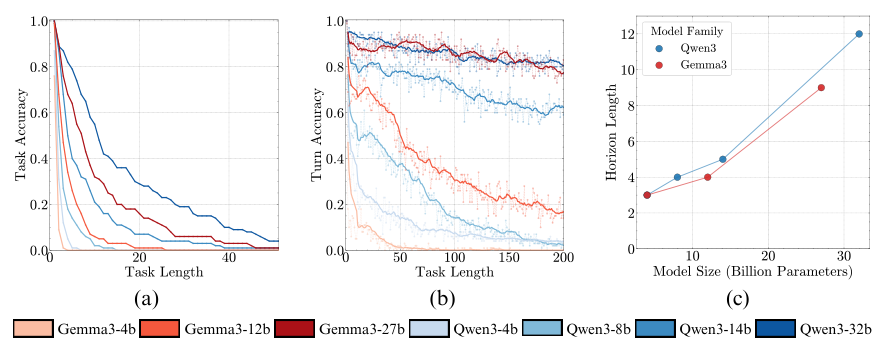
在知识和推理都被“锁死”的情况下,模型规模越大的,长时程执行能力就越强,坚持的时间就越长。研究者猜测,可能是大模型内部的神经回路更复杂,有更多的“冗余备份”,不容易因为一个小地方出错就全盘崩溃。
这次研究最重磅的发现,是一个足以改变AI训练范式的现象:“自我条件效应”(self-conditioning effect)。这是什么意思呢?研究团队发现,当模型在执行任务的过程中犯了一个错,这个错误的输出会成为它下一步行动的“上下文”或“历史记录”。然后,怪事发生了:模型看到自己之前犯过错,它接下来就更容易犯错。一次失误,会导致接二连三的失误,形成恶性循环。
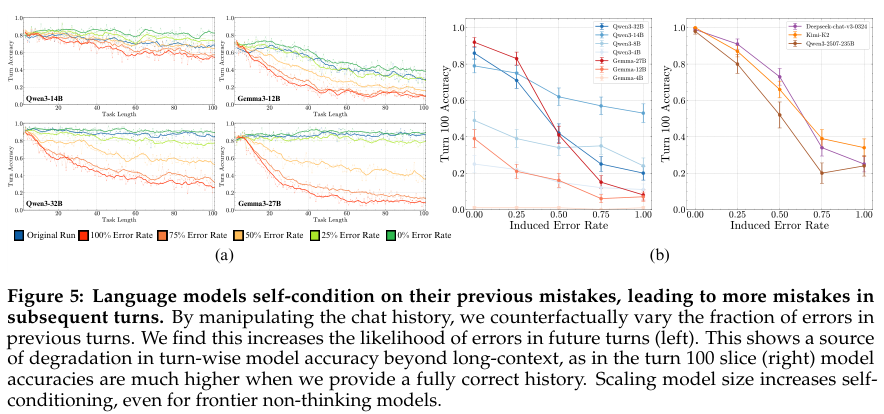
这简直就像一种“自我PUA(精神打压)”。模型在潜意识里告诉自己:“哦,看来我就是个会犯错的模型”,于是就心安理得地继续犯错。我们通常是“吃一堑,长一智”,在错误中学习和进步。而AI呢,却是在错误中“学习”如何继续犯错。研究团队做了一个绝妙的实验来验证这一点:他们人为地在模型的历史记录里“投毒”,注入一些错误的答案。结果发现,注入的错误率越高,模型在后续任务中的表现就越差。
研究人员还发现,扩大模型规模,并不能解决这个“自我PUA”的问题。虽然更大的模型在处理长上下文时表现更好,但它们同样会受到自我条件效应的困扰。就算是参数量超过2000亿的Kimi-K2和Qwen3-235B这种巨无霸模型,一旦历史记录里有了错误,它们的性能照样会持续下滑。说明,“自我PUA”是可能一种根植于当前AI训练范式深处的“心病”,光靠“吃胖”是治不好的。
就在大家觉得这问题无解的时候,转机出现了。最新的“思考模型”(thinking models)可以完美修复“自我PUA”。这些模型,比如用了强化学习的,它们在输出最终答案之前,会先在内部生成一个“思考过程”或者说“草稿”。研究团队发现,这些模型完全不受历史错误的影响。不管你在它们的历史记录里注入多少错误,它们在当前这一步的表现都稳如泰山。
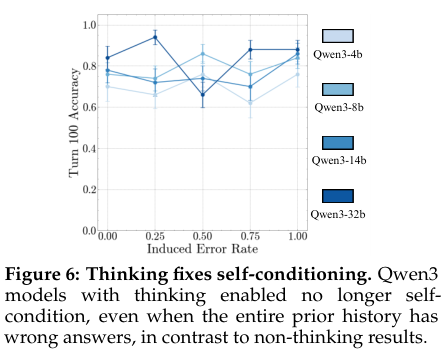
为什么呢?研究者推测有两个原因。第一,强化学习的训练目标是“任务成功”,而不是像传统模型那样,仅仅是“预测最可能的下一个词”。所以它有更强的目标感,不会轻易被历史带偏。第二,也是更关键的,它们在思考新一轮任务时,似乎能做到“翻篇”,把上一轮的思考过程和结果(无论是对是错)隔离开,每一次都像一次全新的独立计算。这就从根本上切断了错误传播的链条。
整篇论文最高能的部分,是思考模型不仅能修复“自我PUA”,它们在一次交互中能够执行的任务长度,简直是碾压式的存在。研究团队搞了个“单轮极限挑战赛”,看各个模型在不出“思维链”(chain of thought)的情况下,一次性最多能处理多少个键值对的累加。
结果让人目瞪口呆。那些非思考模型,哪怕是像DeepSeek-V3和Kimi K2这样的万亿巨兽,表现都不佳。而思考模型这边,则完全是另一个次元的景象。
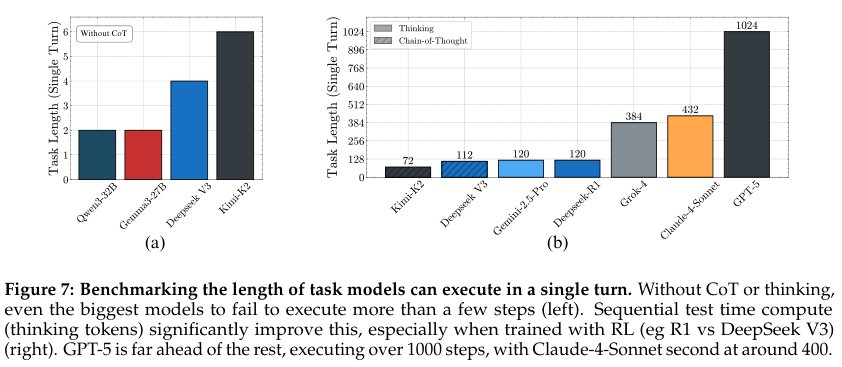
GPT-5可以一口气执行超过1000步!而排在第二名的Claude-4-Sonnet是432步。
游戏规则,该改改了?
但这篇研究告诉我们,在各种各样的基准测试集上刷榜,看谁的单步任务准确率更高,这种方式可能不全面。研究者指出:“如果AI代理的经济价值也来自于它能够完成的任务长度,那么单轮或短期任务基准可能是评估进一步投资大型语言模型计算收益的虚幻参考。”也就是新的、专注于长任务执行的基准测试,将会变得越来越重要。
这对投资决策来说,可能意味着“继续烧钱,而且要烧得更理直气壮”。
对于那些致力于开发AI代理(Agent)的公司来说,这篇研究清楚地指出了通往成功的几条路:第一,必须想办法克服“自我条件效应”。第二,大力拥抱“思考模型”的技术路线,让AI学会“三思而后行”。第三,模型规模依然重要,它是长时程执行能力的基础保障。第四,要研究更聪明的上下文管理方法,别让过去的错误成为未来的包袱。
研究结果表明,像强化学习这种更注重“任务成功”的训练范式,可能是解锁长时程能力的关键。未来的训练,可能需要加入更多的长时程任务,甚至专门训练模型的“思考轨迹”生成能力和“自我纠错”能力,而不是简单地模仿和预测。
但也有业内人士表示,这项研究并不严谨。你怎么看?


