本文由 NUS ShowLab 主导完成。第一作者宋亦仁为新加坡国立大学 ShowLab@NUS 在读博士生,研究方向是视觉生成和多模态,在 CVPR、SIGGRAPH、NeurIPS 等国际顶级会议上发表多篇研究成果。共同一作刘成为 NUS 重庆研究院四年级本科生,研究方向是视觉生成。项目负责作者为该校校长青年教授寿政。
不久前,GPT-4o 的最新图像风格化与编辑能力横空出世,用吉卜力等风格生成的效果令人惊艳,也让我们清晰看到了开源社区与商业 API 在图像风格化一致性上的巨大差距。
目前,开源扩散模型在 image-to-image 风格迁移中普遍面临一个跷跷板困境:要想增强风格化效果,往往会牺牲细节、结构和语义一致性;而要保持一致性,风格表达则明显退化。
为了解决这一难题,我们提出 OmniConsistency,利用配对数据复现 GPT-4o 的出色风格化一致性,为开源生态注入接近商业级的能力。

- 论文标题:OmniConsistency: Learning Style-Agnostic Consistency from Paired Stylization Data
- 项目主页:https://github.com/showlab/OmniConsistency
- 论文链接:https://arxiv.org/abs/2505.18445
- Demo 试用链接:https://huggingface.co/spaces/yiren98/OmniConsistency
我们的解决方案:OmniConsistency
我们提出 OmniConsistency, 一个基于 DiT 的通用一致性增强插件,它可以在保持强烈风格化效果的同时,精准保留输入图像的细节、语义和结构。
OmniConsistency 的训练仅用了 2600 对 GPT-4o 生成的高质量图像,全流程只用约 500 小时 GPU 算力,成本极低。
OmniConsistency 有哪些亮点?来看三句话总结:
✅ 解决风格化与一致性之间的跷跷板问题
✅ 即插即用,兼容社区任意 Flux 底模的风格 LoRA
✅ 轻量高效,效果出色,媲美 GPT-4o
为什么现有方法会出现风格退化?
目前各大厂商的 AI 图生图业务的主流做法是组合风格化 LoRA + 一致性插件 + image2image pipeline。在特定风格数据上微调得到的风格 LoRA 模块,能够在文本到图像(text-to-image, T2I)任务中实现高质量风格图像生成。一致性模块(如 ControlNet、IP-Adapter、Redux 等)负责在图像到图像(image-to-image, I2I)任务中维持结构、边缘或姿态等条件,允许使用更大的去噪强度来获得更强的风格化效果。
问题是,当把这两类模块组合在一起用时,风格模块要的 “自由发挥” 和一致性模块要的 “严谨控制” 彼此掣肘。尤其在 I2I 任务中,风格表达往往会被削弱,出现明显的风格退化。换句话说,现有方法被困在风格化强度和一致性之间的跷跷板上,无法两全。
方法介绍:OmniConsistency 的核心设计
OmniConsistency 的核心目标是打破图像风格化任务中 “风格表达” 与 “一致性保持” 之间的跷跷板困境。为了解决这一问题,我们提出了一种全新的、风格 - 一致性解耦学习方法,其包括以下三项关键设计:
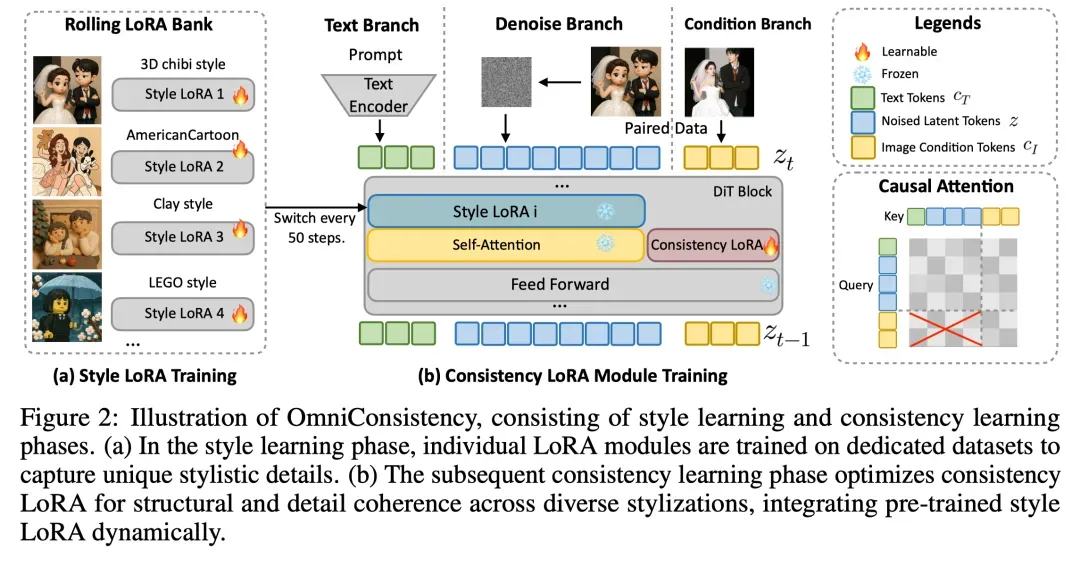
1. In-Context 一致性学习框架:从数据对学习
OmniConsistency 创新性地提出了一种基于风格化图像对的一致性学习机制:不是像现有方法那样先在风格结果上训练 LoRA,再用一致性插件去适配(这往往带来冲突);而是直接利用原图与其高一致性风格化结果的成对关系,专门学习图像在风格迁移中的一致性保持规律。
具体做法是:将原图经过 VAE 编码得到的 clean latent token 拼接到 denoise token 上,通过因果注意力机制引导模型学习配对图像风格化前后的一致性。
2. 两阶段风格 - 一致性解耦训练策略:稳健泛化的关键
为了从训练策略上彻底分离风格表达与一致性保持,我们采用了阶段化解耦训练机制:
- 第一阶段:风格学习。我们基于 22 种不同的艺术风格,用风格化结果图为每种风格独立训练一个 LoRA 模块,最终构建出一个稳定的 风格 LoRA 模块库。
- 第二阶段:一致性学习。在该阶段,我们冻结所有风格 LoRA,用风格化前后的配对数据训练一个轻量级的一致性模块(Consistency LoRA)。我们设计了 LoRA Bank 滚动加载机制,即训练时动态轮换风格 LoRA 与其对应的训练子集。这样能确保一致性模块专注于跨风格保持结构和语义,而不学习任何具体风格内容。
这种训练解耦策略在保持风格表达能力的同时,极大提升了模型对多风格场景下的一致性泛化能力。
3. 模块化架构设计:即插即用,兼容性强
OmniConsistency 被设计为一套完全模块化的插拔系统,兼容性极强:
- Plug-and-Play LoRA:一致性模块专门作用于条件分支,与风格 LoRA 使用独立 “插槽”,二者在架构上无参数冲突。因此,任何 HuggingFace 社区风格 LoRA 模型均可直接与 OmniConsistency 联动,无需修改或重训练。
- 因果注意力:不同于 Flux 和之前的可控性生成工作, 我们将双向注意力机制改成 Causal Attention. 我们定义了一个注意力 mask, 限制 Condition token 的 Query 和 Noised&Text Token 的 Key 计算注意力。 这样的好处是 Flux 的 Noised&Text 分支上没有新增可训练的 LoRA 参数, 完全为风格化 LoRA 腾出挂载位点。
- 兼容 EasyControl/ IP-Adapter 等控制信号:由于一致性模块采用因果注意力 + 条件注入策略,其他控制方法也可无缝集成,互不干扰。
数据集构建
我们采用 GPT-4o 自动生成了一套高质量配对数据:设计 22 种不同风格的提示词,上传原始图像,生成对应的风格化版本,还配上详细文本描述。

然后,我们通过人工筛选,剔除了风格不一致、细节错误、姿态错位等问题图,最终精选出 2600 对高质量图像对,涵盖了动漫、素描、像素画、水彩、赛博朋克等风格。
效果如何?
直接上图, OmniConsistency 能很好的维持风格化前后构图、语义、细节一致,对人物面部特征的维持也有一定作用。对多人合影等复杂场景,很好的维持了人数、姿势、性别、种族、年龄,甚至还能维持图片中的英文文字正确性。



OmniConsistency 对训练阶段没见过的风格 LoRA 也有很好的泛化作用。

定量评估

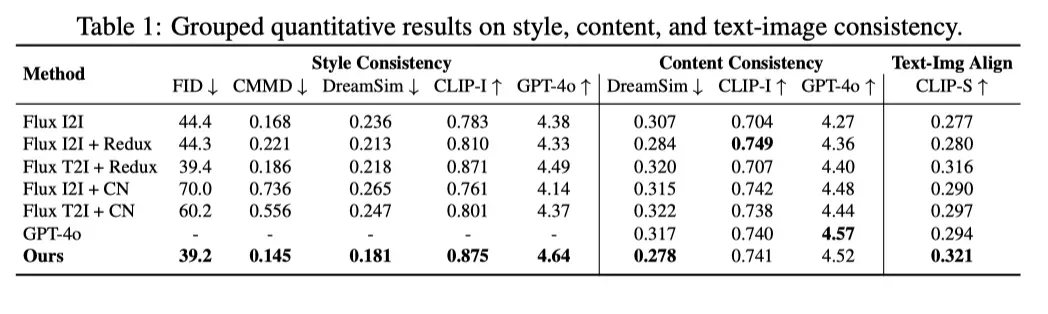
论文构建了一个全新数据集,包括:22 种风格、2600 对高质量图像对, 由 GPT-4o 构建并进行人工筛选。用 100 张复杂场景测试图(多人合影、建筑、动物等)作为 benchmark。使用 LibLib 网站上 5 个训练阶段未见过的全新风格 LoRA ,进行定量计算。

采用用多项指标全面评估,包括风格一致性评估(FID、CMMD、DreamSim、CLIP Image Score、GPT-4o Score);内容一致性评估(DreamSim、CLIP Image Score、GPT-4o 评分);图文对齐(CLIP Score)。
总结
风格一致性:FID 和 CMMD 指标显著优于基线,风格化程度接近 LoRA 文生图 效果。
内容一致性:复杂场景下的细节、语义、结构保持能力大幅提升。
泛化能力:在未见过的 LoRA 风格上泛化效果出色,显示出强大的风格无关性。
轻量高效:得益于特征复用和位置编码差值技术,推理显存与时间开销相比 Flux text2image pipeline 仅增加约 5%,适合部署到生产环境。
即插即用、广泛兼容:模块化设计支持与社区 LoRA、EasyControl、IPAdapter 等主流插件无缝集成,无需重训即可使用。