刚刚,字节旗下的豆包团队发布了他们最新的推理模型Seed-Thinking-v1.5!
亮点很突出:200B参数击败DeepSeek R1(671B),不到后者参数量的三分之一!
与其他最新的超大杯推理模型相比,Seed-Thinking-v1.5 是一个相对小型的专家混合(MoE)模型——激活参数为 20B,总参数规模为 200B。
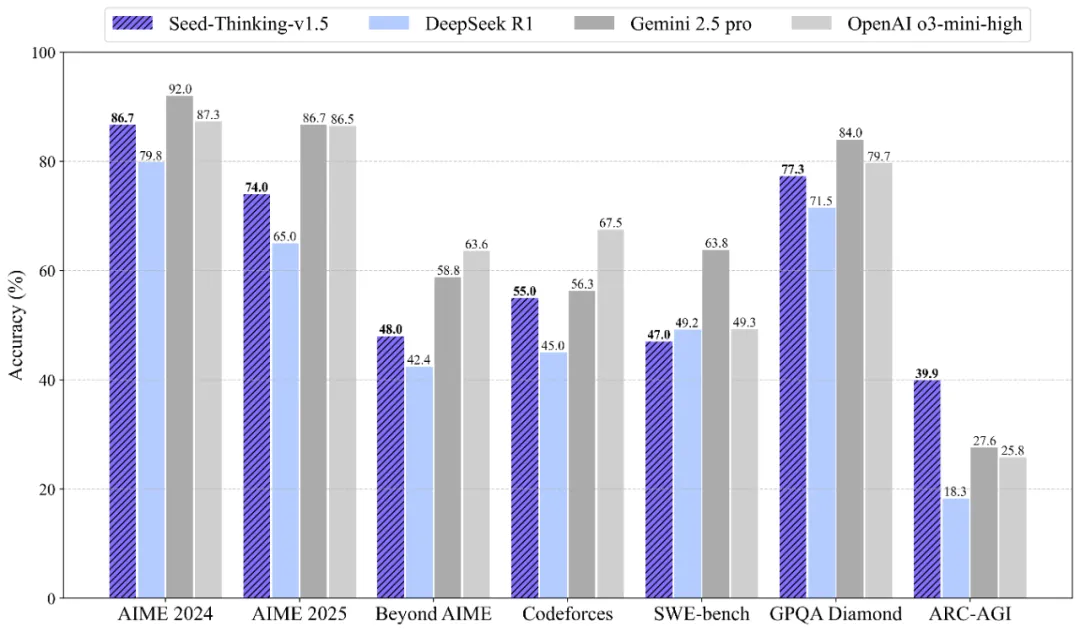
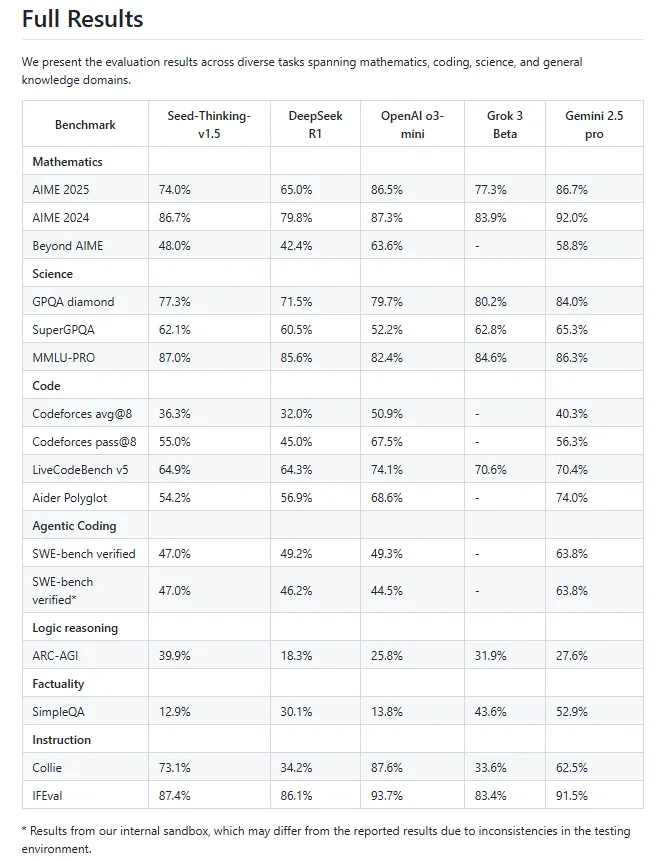
Seed-Thinking-v1.5 在数学、科学和逻辑推理等“硬核”任务中表现稳定:在 AIME 2024 上取得了 86.7 分,在 Codeforces 上达到 55.0 分,在 GPQA 上达到 77.3 分,展现出在 STEM 领域和编程任务中的出色推理表现。
除了推理任务,该方法还展现出对多种任务的优秀泛化能力。例如,在非推理任务上的胜率比 DeepSeek R1 高出 8%,表明其适用范围更广。
此外,为了更好评估模型通用推理能力,字节专门开发了两个内部基准:BeyondAIME 和 Codeforces。这两个基准之后会开源,以支持后续研究。
报告地址:https://github.com/ByteDance-Seed/Seed-Thinking-v1.5


