
译者 | 涂承烨
审校 | 重楼
不到十年前,能与计算机进行有意义的对话的想法还只是科幻小说。但今天,数以百万计的人与AI助手聊天,根据文本描述创作令人惊叹的艺术作品,并每天使用这些AI工具/系统来理解图像和执行高级任务。这一进步由许多专业AI模型驱动,每个模型都有其独特的功能和应用。本文将介绍八种正在重塑数字格局并可能塑造我们未来的专业AI模型。
1.LLMs:大型语言模型(Large Language Models)
还记得科幻电影里人类过去常常与计算机正常交谈的情景吗?大型语言模型创造了一种虚构已成为现实的氛围。这些模型理解并生成人类语言,构成了现代AI助手的支柱。
LLMs的架构:
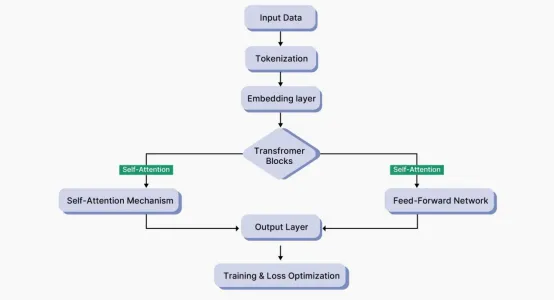
LLMs本质上建立在变换器(Transformer)之上,变换器由堆叠的编码器和/或解码器块组成。典型的实现包括使用以下组件:
- 多头注意力层(Multi-Head Attention Layers):不同的注意力层允许模型同时关注输入的各个部分,每层计算 Q、K、V 矩阵。
- 前馈神经网络(Feed-Forward Neural Networks):当这些网络接收注意力输出时,它们实现两个线性变换,中间有一个非线性激活函数,通常是 ReLU 或 GELU。
- 残差连接与层归一化(Residual Connections and Layer Normalization):通过允许梯度在深度网络中流动并通过归一化网络激活来使训练稳定。
- 位置编码(Positional Encoding):当变换器并行处理词元(token)时,它使用正弦或学习得到的位置嵌入来注入位置信息。
- 多阶段训练(Multi-Phase Training):在精选数据集上进行微调之前的预训练,随后进行对齐(alignment),其中人类反馈强化学习(RLHF)是方法之一。
LLMs的关键特性:
- 自然语言理解与生成
- 在较长词元跨度上的上下文感知
- 从海量训练数据中学习知识表示
- 零样本学习(无需任何特定训练即可执行任务的能力)
- 上下文学习(in-context learning),即通过示例适应新格式的能力
- 遵循指令进行复杂的多步推理
- 用于解决问题的思维链(Chain-of-thought)推理能力
LLMs的示例:
- GPT-4(OpenAI):最具先进性的语言模型之一,具有多模态能力,驱动着 ChatGPT 和数千个应用程序。
- Claude(Anthropic):以产生深思熟虑、细致入微的输出和良好推理而闻名。
- Llama 2 & 3(Meta):强大的开源模型,将AI带给大众。
- Gemini(Google):谷歌的最先进模型,具有极强的推理和多模态能力。
LLMs的用例:
想象你是一个遭遇写作瓶颈的内容创作者。LLMs可以生成想法、创建文章大纲或为你起草内容供你润色。设想你是一个遇到编码问题的开发者;这些模型可以调试你的代码、提出解决方案,甚至用浅显的英语解释复杂的编程概念或术语。
2.LCMs:大型概念模型(Large Concept Models)
LLMs 专注于语言,而 LCMs 则侧重于理解思想之间更深层次的概念关系。你可以把它们看作是掌握概念而不仅仅是单词的模型。
LCMs的架构:
LCMs 在变换器架构基础上构建,增加了用于概念理解的专业组件,通常包括:
- 增强的交叉注意力机制(Enhanced Cross-Attention Mechanisms): 将文本词元连接到概念表示,并将单词连接到潜在概念。
- 知识图谱集成(Knowledge Graph Integration):直接在架构中或通过预训练目标间接集成结构化知识。
- 分层编码层(Hierarchical Encoding Layers):这些层级在不同抽象层次上捕获概念,从具体实例到抽象类别。
- 多跳推理模块(Multi-Hop Reasoning Modules):允许多步跟踪概念关系链。
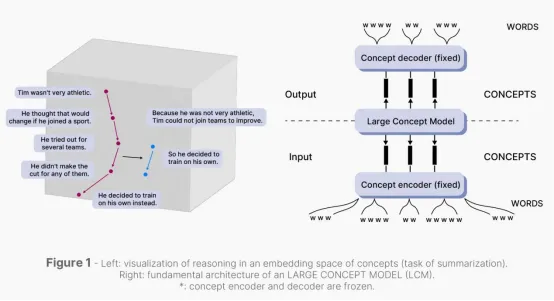
预训练通常针对概念预测、概念消歧、层次关系建模以及从抽象到具体的映射。此外,许多实现采用专门的注意力机制,该机制为与概念相关的词元分配与一般上下文相关的词元不同的权重。
LCMs的关键特性:
- 将抽象思想概念化,超越语言的表层
- 在逻辑和因果推理方面表现出色
- 改进的常识推理和推断能力
- 连接不同领域的相关概念
- 对层次结构的语义概念化
- 概念消歧和实体链接
- 类比与学习迁移
- 从多样信息源组合知识
LCMs的顶级示例:
- Gato(Deepmind):一个通用智能体,使用一个简单模型执行数百项任务。
- 悟道 2.0(Wu Dao 2.0, 北京智源人工智能研究院):一个用于概念理解的超大规模多模态 AI 系统。
- Minerva(Google):专长于数学和科学推理。
- Flamingo(DeepMind):通过概念框架桥接视觉和语言理解。
LCMs的用例:
对于试图将来自不同科学论文的见解整合起来的研究员,LCM 将揭示那些原本隐藏的概念联系。教育工作者可以与 LCMs 合作设计教学材料,以增强概念学习,而不是直接记忆。
3.LAMs:大型动作模型(Large Action Models)
大型动作模型是 AI 进化的下一阶段,这些模型不仅能理解或生成内容,还能在数字环境中采取有意义的有向动作。它们在理解与行动之间架起桥梁。
LAMs的架构:
LAMs 通过多组件设计将语言理解与动作执行结合起来:
- 语言理解核心(Language Understanding Core):基于变换器的LLM 用于处理指令并生成推理步骤。
- 规划模块(Planning Module):分层规划系统,将高级目标分解为可操作的步骤,通常使用蒙特卡洛树搜索(Monte Carlo Tree Search)或分层强化学习(hierarchical reinforcement learning)等技术。
- 工具使用接口(Tool Use Interface):用于外部工具交互的 API 层,包括发现机制、参数绑定、执行监控和结果解析。
- 记忆系统(Memory Systems):同时使用短期工作记忆和长期情景记忆来维持跨动作的上下文。
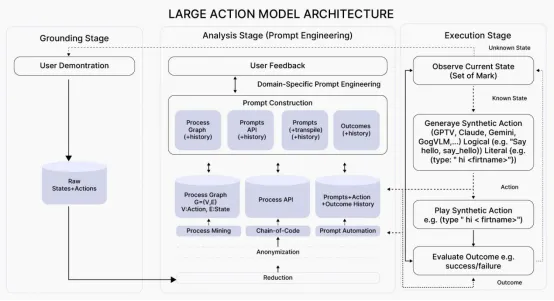
计算流程经历指令生成与解释、规划、工具选择、执行、观察和计划调整的循环。训练通常结合使用监督学习、强化学习和模仿学习的方法。另一个关键特征是存在一个“反思机制(reflection mechanism)”,模型在其中判断其动作的效果并相应地调整所应用的策略。
LAMs的关键特性:
- 根据以自然语言形式传递的指令采取行动
- 多步骤规划以实现需要如此的目标
- 无需人工干预即可使用工具和进行 API 交互
- 通过演示学习而非编程
- 从环境中接收反馈并自我适应
- 单智能体决策,安全第一
- 状态跟踪和跨越顺序交互
- 自我纠正和错误恢复
LAMs的顶级示例:
- AutoGPT:一个用于任务执行的实验性自主 GPT-4。
- 带工具的 Claude Opus:通过函数调用实现复杂任务的高级自主性。
- LangChain Agents:用于创建面向动作的 AI 系统的框架。
- BabyAGI:自主任务管理和执行的演示。
LAMs的用例:
想象要求一个 AI “研究本地承包商,汇编他们的评分,并为我们的厨房改造项目安排与前三名的面试”。LAMs 可以执行这种需要理解与行动相结合的多步骤复杂任务。
4.MoEs:专家混合模型(Mixture of Experts)
考虑一组专家而不是一个单一的通才,这就是MoE设计所暗示的。这些模型由多个专家神经网络组成,每个网络都经过训练以处理特定的任务或知识领域。
MoE的架构:
MoE 实现条件计算(Conditional Computation),使得不同的输入激活不同的专门子网络:
- 门控网络(Gating Network):将输入发送到适当的专家子网络,决定模型内的哪些“记忆”应处理每个词元或序列。
- 专家网络(Expert Networks):多路、专门的神经子网络(专家),通常是嵌入变换器块中的前馈网络。
- 稀疏激活(Sparse Activation):每个输入只激活一小部分参数。这是通过 top-k 路由(top-k routing)实现的,其中只允许得分最高的前k个专家处理每个词元。
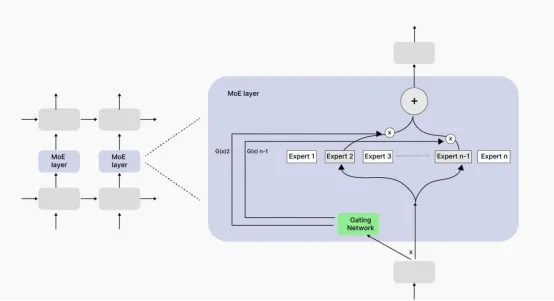
现代实现用变换器中的 MoE 层替代标准的 FFN(前馈网络)层,保持注意力机制为密集的。训练涉及负载平衡(Load Balancing)、损失和专家丢弃(Expert Dropout)等技术,以避免病态路由模式。
MoE的关键特性:
- 高效扩展到巨大参数数量,而无需按比例增加计算量
- 实时将输入路由到专门网络
- 由于条件计算,参数效率更高
- 在专门的领域-任务上表现更好
- 对于新颖输入具有优雅降级(Graceful degradation)能力
- 更擅长多领域知识
- 训练时减少灾难性遗忘(Catastrophic Forgetting)
- 领域平衡的计算资源
MoE的顶级示例:
- Mixtral AI:一个采用稀疏专家混合架构的开源模型。
- Switch Transformer(Google):最早的 MoE 架构之一。
- GLaM(Google):谷歌在 MoE 架构上构建的拥有1.2万亿参数的语言模型。
- Gemini Ultra(Google):采用基于 MoE 的方法来提升性能。
MoE的用例:
考虑一个需要 AI 系统能够处理和管理从客户服务到技术文档再到创意营销等一切事务的企业。MoE 模型最擅长这种灵活性,因为它们使得不同的“专家”能够根据所执行的工作被激活。
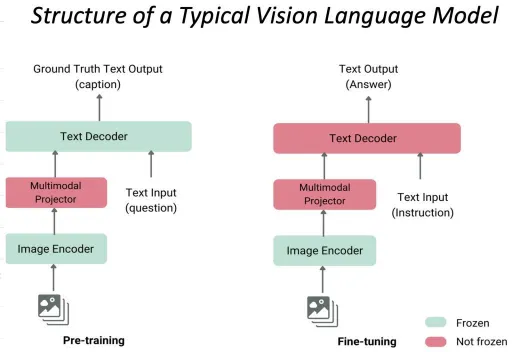
5.VLMs:视觉语言模型(Vision Language Models)
用最简单的话说,VLMs 是视觉与语言之间的桥梁。VLM 具有理解图像并使用自然语言传达相关信息的能力,本质上赋予 AI 系统“看见”并“讨论”所见内容的能力。
VLMs的架构:
VLMs 通常为视觉和语言流实现双流架构:
- 视觉编码器(Visual Encoder):通常是视觉变换器(Vision Transformer, ViT)或卷积神经网络(CNN),将图像分割成小块(Patches)并进行嵌入(Embedding)。
- 语言编码器-解码器(Language Encoder-Decoder):通常是基于变换器的语言模型,接收文本输入并输出文本。
- 跨模态融合机制(Cross-Modal Fusion Mechanism):此机制通过以下方式连接视觉和语言流:
A.早期融合(Early Fusion):将视觉特征投影到语言嵌入空间。
B.晚期融合(Late Fusion):分别处理,然后在更深层通过注意力连接。
C.交错融合(Interleaved Fusion):在整个网络中设置多个交互点。
D.联合嵌入空间(Joint Embedding Space):一个统一的表示空间,视觉概念和文本概念被映射到可比较的向量。
预训练通常采用多目标训练机制,包括图像-文本对比学习、带视觉上下文的掩码语言建模、视觉问答和图像描述生成。这种方法培养了能够在多种模态之间进行灵活推理的模型。
VLMs的关键特性:
- 解析和整合视觉与文本信息
- 图像理解和细粒度描述能力
- 视觉问答和推理
- 场景解读,包括物体和关系识别
- 关联视觉和文本概念的跨模态推理
- 基于视觉输入的文本生成
- 关于图像内容的空间推理
- 理解视觉隐喻和文化参照
VLMs的顶级示例:
- GPT-4(OpenAI):支持视觉功能的 GPT-4 版本,可以分析和讨论图像。
- Claude 3 Sonnet/Haiku(Anthropic):具有强大视觉推理能力的模型。
- Gemini Pro Vision(Google):在文本和图像方面具有先进的多模态能力。
- DALLE-3 & Midjourney:虽然主要以图像生成闻名,但也包含了视觉理解组件。
VLMs的用例:
想象一位皮肤科医生上传一张皮肤状况的图像,AI 立即提供带有推理的潜在诊断。或者一位游客将手机对准一个地标,即时获取其历史意义和建筑细节。
6.SLMs:小型语言模型(Small Language Models)
人们将注意力给予越来越大的模型,但我们通常忘记了小型语言模型(SLMs) 涵盖了一个同样重要的趋势:设计用于在无法访问云端的个人设备上高效工作的 AI 系统。
SLMs的架构:
SLMs 开发了针对计算效率优化的专门技术:
- 高效注意力机制(Efficient Attention Mechanisms):替代标准自注意力的系统(标准自注意力复杂度为平方级 O(n²)),包括:
A.线性注意力(Linear attention):通过核近似将复杂度降低到 O(n)。
B.局部注意力(Local attention):仅在局部窗口内进行注意力计算,而不是在整个序列上。
- 状态空间模型(State Space Models):另一种具有线性复杂度的序列建模方法。
- 参数高效变换器(Parameter Efficient Transformers):减少参数数量的技术包括:
A.低秩分解(Low-Rank Factorization):将权重矩阵分解为较小矩阵的乘积。
B.参数共享(Parameter Sharing):跨层重用权重。
C.深度可分离卷积(Depth-wise Separable Convolutions):用更高效的层替换密集层(dense layers)。
- 量化技术(Quantization Techniques):降低权重和激活值的数值精度,通过训练后量化、量化感知训练或混合精度方法实现。
- 知识蒸馏(Knowledge Distillation):通过基于响应的、基于特征的或基于关系的蒸馏模型,转移封装在大型模型中的知识。
所有这些创新使得一个 1-100 亿参数的模型能够在消费级设备上运行,其性能接近更大的云端托管模型。
SLMs的关键特性:
- 执行完全在应用程序内进行,无需云端依赖或连接
- 增强数据隐私,因为数据永远不会从设备卸载
- 由于没有网络往返,能够提供非常快速的响应
- 节能且对电池友好
- 完全离线操作,无需检查远程服务器,对于高度安全或远程环境特别有用
- 更便宜,无 API 使用费
- 可针对特定设备或应用进行升级
- 针对特定领域或任务进行针对性优化
SLMs的顶级示例:
- Phi-3 Mini(Microsoft):一个 38 亿参数的模型,在其规模上表现非常出色。
- Gemma(Google):一个旨在进行设备端部署的轻量级开源模型系列。
- Llama 3 8B(Meta):Meta 的 Llama 家族中更小的变体,旨在高效部署。
- MobileBERT(Google):专为移动设备定制,同时仍保持类似 BERT 的性能。
SLMs的用例:
SLMs 可以真正帮助那些几乎没有任何连接但需要可靠 AI 支持的人。注重隐私的客户可以选择将不必要的私人数据保留在本地。打算在资源可能受限的环境中为应用程序提供强大 AI 功能的开发者可以随时利用它。
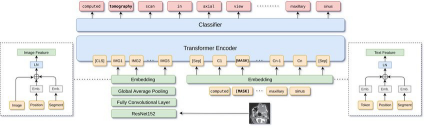
7、MLMs:掩码语言模型(Masked Language Models)
掩码语言模型采用一种不同寻常的语言理解方式:它们通过完成填空练习来学习,在训练过程中随机“掩码”掉一些词,使得模型必须从周围的上下文中找出那个缺失的词元。
MLMs的架构:
MLM 通过双向架构以实现整体上下文理解:
- 仅编码器变换器(Encoder-only Transformer):与严格从左到右处理文本的基于解码器(decoder-based)的模型不同,MLMs 通过编码器块(encoder blocks)双向关注整个上下文。
- 掩码自注意力机制(Masked Self-Attention Mechanism):每个词元都可以通过缩放点积注意力(scaled dot-product attention)关注序列中的所有其他词元,无需应用任何因果掩码(causal mask)。
- 词元嵌入、位置嵌入和段落嵌入(Token, Position, and Segment Embeddings):这些嵌入组合形成包含内容和结构信息的输入表示。
预训练目标通常包括:
- 掩码语言建模(Masked Language Modelling):随机词元被替换为[MASK]词元,然后模型根据双向上下文预测原始词元。
- 下一句预测(Next Sentence Prediction):判断两个段落是否在原始文本中相互跟随,不过像 RoBERTa 这样的更新变体移除了此目标。
这种架构产生的是词元的上下文相关表示,而不是下一个词元预测。基于此,MLMs 更倾向于用于理解任务而非生成任务。
MLMs的关键特性:
- 双向建模利用更广泛的上下文增强理解
- 更擅长语义分析和分类
- 强大的实体识别和关系抽取能力
- 使用更少样本进行表示学习
- 在结构化抽取任务上达到最先进水平
- 向下游任务的可迁移性强
- 处理一词多义的上下文词表示
- 易于针对专业领域进行微调
MLMs的顶级示例:
- BERT(Google):第一个带来 NLP 范式转变的双向编码器模型
- RoBERTa(Meta):采用更好训练方法进行鲁棒优化的 BERT
- DeBERTa(Microsoft):具有解耦注意力的增强版 BERT
- ALBERT(Google):采用参数高效技术的轻量级 BERT 平台
MLMs的用例:
想象一位律师必须从数千份合同中提取某些条款。MLMs 非常擅长此类有针对性的信息提取,有足够的上下文来识别相关部分,即使它们的描述方式截然不同。
8.SAMs:分割任意模型(Segment Anything Models)
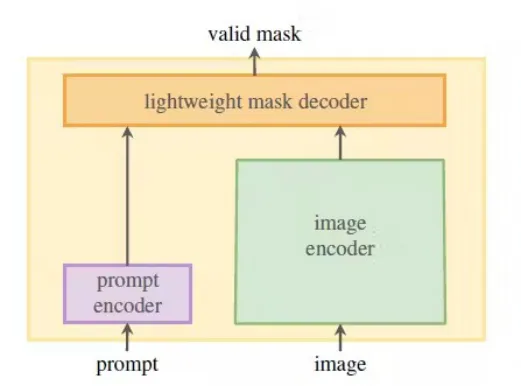
分割任意模型(SAM) 是计算机视觉领域的一项专业技术,用于以近乎完美的精度从图像中识别和分离对象。
SAM的架构:
SAM 的架构是多组件的,用于图像分割:
- 图像编码器(Image encoder): 这是一个视觉变换器(Vision Transformer, ViT)主干网络,对输入图像进行编码以产生密集的特征表示。SAM 使用 VIT-H 变体,包含 32 个变换器块,每块有 16 个注意力头。
- 提示编码器(Prompt Encoder): 处理各种类型的用户输入,例如:
A.点提示(Point Prompts): 带有背景指示符的空间坐标。
B.框提示(Box Prompts): 两点坐标。
C.文本提示(Text Prompts): 通过文本编码器处理。
D.掩码提示(Mask Prompts): 编码为密集的空间特征。
- 掩码解码器(Mask Decoder): 一个结合图像和提示嵌入以产生掩码预测的变换器解码器,由交叉注意力层(cross-attention layers)、自注意力层(self-attention layers)和一个 MLP 投影头组成。
训练包括三个阶段:在1100万个掩码上的监督训练、模型蒸馏和针对特定提示的微调。这种训练可以实现对未见过的对象类别和领域的零样本迁移,从而在其他分割任务中实现广泛用途。
SAM的关键特性:
- 零样本迁移到训练中从未见过的新对象和类别
- 灵活的提示类型,包括点、框和文本描述
- 在超高分辨率下实现像素级完美分割
- 对各类图像具有领域无关的行为
- 多对象分割,了解对象之间的关系
- 通过提供多个正确分割来处理歧义
- 可作为组件集成到更大的下游视觉系统中
SAM的顶级示例:
- Segment Anything(Meta): Meta Research 的原始模型。
- MobileSAM: 为移动设备优化的轻量级变体。
- HQ-SAM: 具有更好边缘检测的更高质量变体。
- SAM-Med2D: 用于医疗成像的医学适配版本。
SAM的用例:
照片编辑者可以使用 SAM 以手动需要数分钟或数小时才能达到的精度即时将主体与背景分离。另一方面,医生可以使用 SAM 的变体在诊断影像中勾画解剖结构。
你应该选择哪种模型?
模型的选择完全取决于你的需求:
模型类型 | 最佳用例 | 计算要求 | 部署选项 | 关键优势 | 限制条件 |
LLM | 文本生成、客户服务、内容创作 | 非常高 | 云端、企业服务器 | 多功能语言能力、通用知识 | 资源密集、可能产生幻觉 |
LCM | 研究、教育、知识组织 | 高 | 云端、专用硬件 | 概念理解、知识连接 | 仍是新兴技术、实现有限 |
LAM | 自动化、工作流执行、自主智能体 | 高 | 云端(带API访问) | 动作执行、工具使用、自动化 | 设置复杂、可能不可预测 |
MoE | 多领域应用、专业知识 | 中-高 | 云端、分布式系统 | 规模化效率高、特定领域知识 | 训练复杂、路由开销 |
VLM | 图像分析、可访问性、视觉搜索 | 高 | 云端、高端设备 | 多模态理解、视觉上下文 | 实时使用需要大量计算 |
SLM | 移动应用、注重隐私的用途、离线使用 | 低 | 边缘设备、移动端、浏览器 | 隐私、离线能力、可访问性 | 与更大模型相比能力有限 |
MLM | 信息提取、分类、情感分析 | 中 | 云端、企业部署 | 上下文理解、针对性分析 | 不太适合开放式生成 |
SAM | 图像编辑、医学成像、物体检测 | 中-高 | 云端、GPU工作站 | 精确的视觉分割、交互式使用 | 专精于分割而非通用视觉任务 |
结论
专业AI模型代表了各项改进之间的新成果。也就是说,机器能够越来越像人类一样理解、推理、创造和行动。然而,该领域最令人兴奋的可能不是任何一种模型类型的承诺,而是当这些类型开始融合时将会出现什么。这样的系统将整合 LCMs 的概念理解能力、LAMs 的行动能力、MOEs 的高效选择能力以及 VLMs 的视觉理解能力,所有这些似乎都可以通过 SLM 技术在本地设备上运行。
问题不在于这是否会改变我们的生活,而在于我们将如何利用这些技术来解决最大的挑战。工具已经在这里,可能性是无限的,未来取决于它们的应用。
译者介绍
涂承烨,51CTO社区编辑,具有15年以上的开发、项目管理、咨询设计等经验,获得信息系统项目管理师、信息系统监理师、PMP,CSPM-2等认证。
原文标题:Top 8 Specialized AI Models,作者:Riya Bansal


