
张剑清是一名上海交通大学在读博士生,获中国人工智能学会「青托」、吴文俊人工智能荣誉博士及国家奖学金。在代码大模型、合成数据集进化生成、联邦学习与推荐系统方向取得系列成果,主要关注其中的垂域自适应、模型融合、模型个性化主题,于JMLR、NeurIPS、ICML、CVPR、KDD、ICCV、AAAI等发表9篇CCF-A一作论文,主导并开源了PFLlib、HtFLlib、EvolveGen等项目,曾在字节跳动、清华AIR、KAUST、腾讯等机构实习交流。
数据短缺问题随着大模型的高速发展,日益加剧。已经有不少 Nature 论文指出,预计到 2028 年,公共数据的产生速度将因赶不上大模型训练的消耗速度而被耗尽。而在某些特殊领域,比如医疗、工业制造等,原本可用数据就非常少,数据短缺的问题更严重。
为了解决这一困境,我们提出了合成数据自主进化框架 PCEvolve:只需提供少量标注样本,就可在保护隐私同时进化出一整个数据集。PCEvolve 的进化过程类似 DeepMind 提出的 FunSearch 和 AlphaEvolve。

论文标题: PCEvolve: Private Contrastive Evolution for Synthetic Dataset Generation via Few-Shot Private Data and Generative APIs
论文链接:https://www.arxiv.org/abs/2506.05407
开源代码:https://github.com/TsingZ0/PCEvolve
进化生成开源平台:https://github.com/TsingZ0/EvolveGen
现有大模型 API 并不能拿来直接合成垂域数据
垂直领域的中小企业普遍不具备训练私有大模型的能力,而倾向于使用现成的大模型 API(下文简称「大模型」)。人造合成数据是目前解决数据短缺问题所采用的主流方法:让已有大模型生成数据,再进行筛选、标注、清洗等步骤,得到高质量训练数据。
然而,当应用到垂直领域,如医疗、工业制造等领域,大模型虽然能够根据 prompt 生成对应的数据,但满足「语义匹配」的数据,并不能直接拿来作为垂直领域数据使用。这是因为:垂直领域的数据还有各种其他特性信息,比如光照、数据采样设备型号、隐私信息、上下文等。
举例来说,皮革在不同环境、材质、磨损程度等方面,都具备太多细节信息,而提供给大模型的 prompt 很难完整描述;即便完整描述,大模型也不能完全生成符合 prompt 的数据,因为大模型本身还无法完全模拟世界。
如下图所示,大模型生成的数据,和垂域摄像机拍摄的数据,具有巨大的差距,虽然标签都是「带有胶水残留的皮革」。同样的,在文本领域,让现成的大模型生成的 code snippet 数据,也无法与某公司内部开发人员的代码习惯和代码规范相匹配。而且,这一垂域数据特征分布差异的问题,在任意模态都存在。

【图 1】左边为大模型生成,右边为实际采集。在工业制造皮革领域,大模型生成图片和实际采集图片的对比
同时,因为垂域数据可能因为知识产权、隐私保护、行业规范等原因,本地数据不允许上传给大模型作 context,极大地增加了 prompt 工程的难度、降低了合成数据的质量。比如,公司内部的代码不能上传、医院的病人数据不能上传、企业的次品样品数据不能上传等等。
PCEvolve:保护隐私的合成数据进化框架
垂域数据除了不能上传之外,还具有本身就稀少的特性,导致带标注的垂域样本原本就少。这使得其他要求提供大量标注样本的方法(如 PE 等),不再可用。因为 PE 等方法在垂域情况下,为了保护隐私所加的噪声过大,使其方法退化为一种随机方法。而我们的 PCEvolve 在进化过程中设计了一种基于「指数机制」(Exponential Mechanism)的新的隐私保护方法,适配垂域场景的少样本情况。
下图是 PCEvolve 的架构图,左边是迭代进化框架:类似达尔文进化论,先让大模型 API 生成较大数量的候选合成数据(种群),再经过【选择器】(自然选择)进行淘汰,最后将不带隐私信息的优质合成数据返回给大模型进行下一轮进化。右边则是进化框架的「引擎」【选择器】的详细设计:以隐私数据作为参考(verifier)给合成数据打分(reward),最后根据分数优胜劣汰;其中打分过程,因为用到了隐私数据,需要作隐私保护。
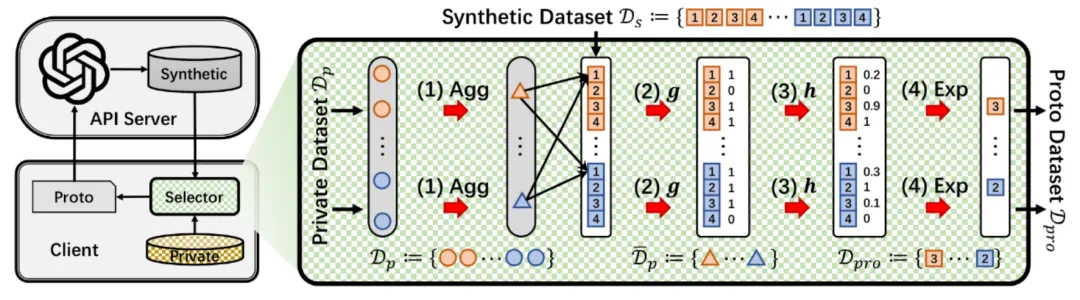
【图 2】PCEvolve 架构图
PCEvolve 选择器详细设计
首先我们先声明:下面所有的操作都需要考虑隐私保护,我们采用的是差分隐私(Differential Privacy, DP),并通过指数机制来实现 DP,其中指数机制定义为:

其关键在于定义一个「好的」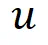 函数。在这里 epsilon 是隐私预算(privacy budget),我们定义
函数。在这里 epsilon 是隐私预算(privacy budget),我们定义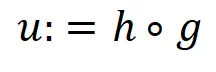 。下面详细介绍
。下面详细介绍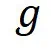 和
和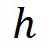 的设计。
的设计。
寻找聚类中心(Agg)给数据打分是需要计算距离的:合成数据离隐私数据近,就意味着合成的数据符合目标任务需要。而在样本空间(文本/图像)不方便计算距离,所以我们考虑利用现有的开源 Encoder 基座模型(如 CLIP 等)将数据映射到特征空间,方便计算距离。进一步地,因为私有数据集
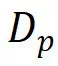 中每个标签有多个样本,每次与合成数据计算 pair-wise 距离再平均带来较高成本。所以我们首先寻找每个标签对应的私有数据的聚类中心,构成数据集,然后以这个聚类中心代表这个标签的所有私有数据用来计算距离。
中每个标签有多个样本,每次与合成数据计算 pair-wise 距离再平均带来较高成本。所以我们首先寻找每个标签对应的私有数据的聚类中心,构成数据集,然后以这个聚类中心代表这个标签的所有私有数据用来计算距离。充分利用不同标签样本间的对比信息
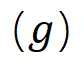 这一步开始,我们便开始执行淘汰机制了。我们首先淘汰掉那些「标签错误」的合成数据:即距离自己标签对应的隐私聚类中心的距离大于其他任何标签对应的隐私聚类中心的距离。用公式表示为:
这一步开始,我们便开始执行淘汰机制了。我们首先淘汰掉那些「标签错误」的合成数据:即距离自己标签对应的隐私聚类中心的距离大于其他任何标签对应的隐私聚类中心的距离。用公式表示为:
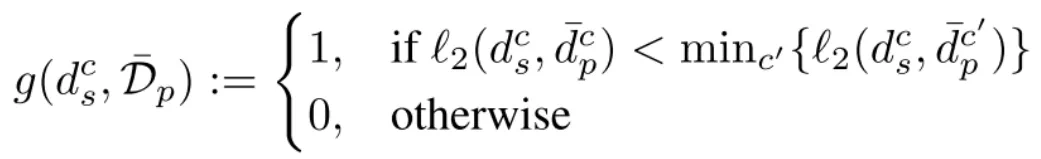
其中,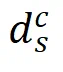 表示合成数据
表示合成数据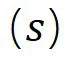 中标签为
中标签为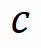 的样本,
的样本,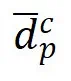 是
是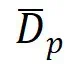 中的一个样本。
中的一个样本。
任务相似度校准由于大模型生成的合成数据与垂域数据,有较大的领域间距(在特征空间中,属于两团相聚极远的特征集合)。如果在每轮进化过程中,只筛掉「相对更远」的合成数据,剩下的合成数据与垂域数据之间的「绝对距离」依旧不会被优化。所以我们提出了相似度度量
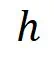 ,定义为:
,定义为:
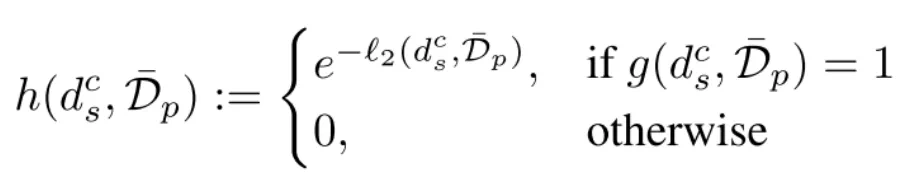
我们只对剩下的合成数据计算距离,其中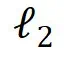 是欧氏距离,其值域为
是欧氏距离,其值域为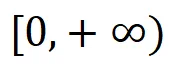 ,所以
,所以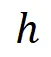 的值域为
的值域为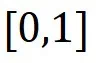 。那么
。那么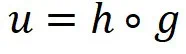 的值域也是
的值域也是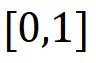 。从而DP 灵敏度
。从而DP 灵敏度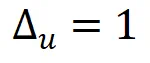 (详细计算细节请参考论文)。
(详细计算细节请参考论文)。
实际上,统计上述公式中的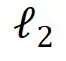 的值出现的频率,即可发现:
的值出现的频率,即可发现: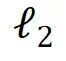 的值几乎不会充满整个
的值几乎不会充满整个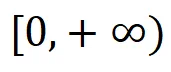 ,但其值域依旧是 [0,1]、DP 灵敏度
,但其值域依旧是 [0,1]、DP 灵敏度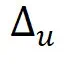 依旧是 1,这样就带来了隐私预算
依旧是 1,这样就带来了隐私预算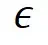 的浪费;因为在指数机制中,不同样本的
的浪费;因为在指数机制中,不同样本的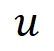 值差异越大越好、越能提升高质量样本被选中的概率(根据指数机制的定义)。所以,我们提出对原本的
值差异越大越好、越能提升高质量样本被选中的概率(根据指数机制的定义)。所以,我们提出对原本的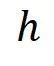 进行校准,并提出了新的
进行校准,并提出了新的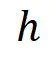 如下:
如下:
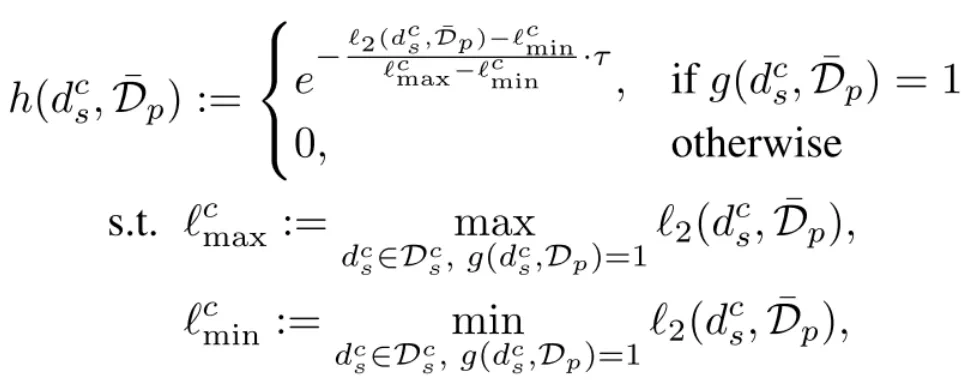
这个新的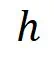 值域不变,使得 DP 灵敏度
值域不变,使得 DP 灵敏度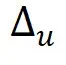 依旧是 1,同时满足指数机制的 DP(理论证明请参考论文)。
依旧是 1,同时满足指数机制的 DP(理论证明请参考论文)。
执行指数机制选择存活样本因为在我们的精心设计下,使得指数机制得以满足,DP 得以保证。所以这一步变得简单:我们只需要执行指数机制定义的概率采样,即可得到带有隐私保护的高质量合成数据选择结果。
在医疗场景和工业制造场景的实验结果
我们主要通过两种方式验证 PCEvolve 的效果:a) 合成的数据对于下游模型训练的增幅,b) 合成数据本身的质量。
a) 合成的数据对于下游模型训练的增幅
我们评估了 PCEvolve 在 COVIDx(COVID-19 胸部 X 线图像)、Came17(乳腺癌转移的肿瘤组织切片)、KVASIR-f(用于胃肠道异常检测的内镜图像)、MVAD-l(用于异常检测的皮革表面)上的表现,这里大模型方面我们只需提供 API 即可。
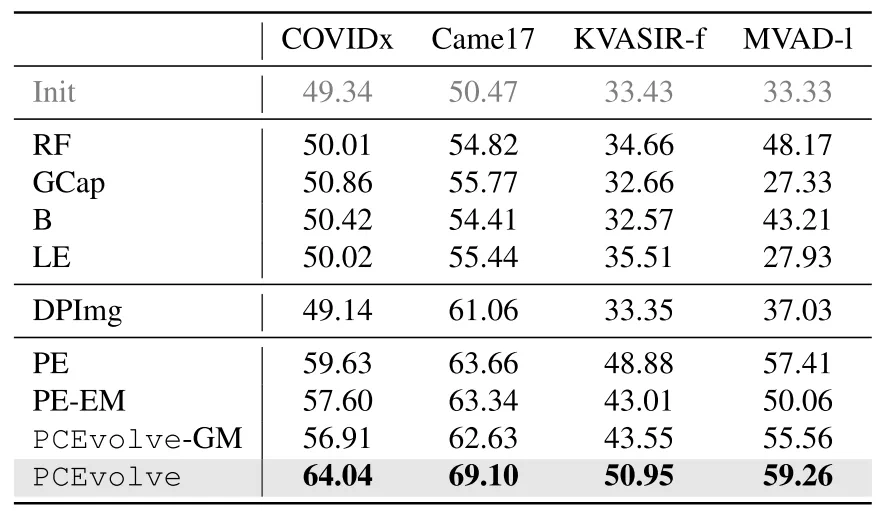
【表 1】在四个特殊领域数据集上的精度(%)
b) 合成数据本身的质量
下图是我们采样的皮革表面数据,这三行分别代表正常皮革、有切割缺陷的皮革、有胶水残留缺陷的皮革。「Initial」表示大模型 API 合成的图像(进化之前);「Private」表示垂域场景真实采集的隐私皮革表面数据。

【图 3】皮革表面图像数据。
其他更多实验详见论文。


