大家好,我是肆〇柒。今天,我们来探讨一下大型混合推理模型(LHRM)。在人工智能领域,大型推理模型(LRM)能够自如的完成比如编程、数学和常识推理等任务。然而,这些模型在实际应用中却暴露出过度思考的问题,简单查询面前,它们依然花费大量计算资源进行冗长的思考,这无疑是对计算资源的巨大浪费。比如,在处理日常问候语 “Hello” 时,模型依然启动复杂的推理过程,这就好像大炮打蚊子,青龙偃月刀削土豆,能力过剩却效率低下。
为解决这一难题,大型混合推理模型(LHRM)出现了。它可以根据用户查询的上下文信息,精准地决定是否启动思考模式。这不仅为人工智能领域提供了新的解决方案,还让我们看到了在推理能力和效率之间取得平衡的可能性。

Qwen2.5-7B-Instruct、DeepSeek-R1-Distill-Qwen-7B以及本文中的LHRM-7B在推理相关任务(顶部)和日常问答任务(底部)中的示例回答上图展示了 Qwen2.5-7B-Instruct、DeepSeek-R1-Distill-Qwen-7B 和本文中的 LHRM-7B 在推理相关任务(顶部)和日常问答任务(底部)中的示例响应。虽然 LLMs 对简单查询响应简洁,但在复杂推理方面表现挣扎。LRM 通过明确的思考步骤处理推理任务,但往往在简单任务中过度使用思考模式,导致响应速度变慢,用户体验下降。相比之下,LHRM 能够自适应地决定何时启动思考模式,在保持强大推理能力的同时,实现更快速、更自然的日常交互。
研究背景与动机
LRM 的发展现状
LRM 模型在今年大量涌现,DeepSeekR1、OpenAI o1/o3 系列等模型各显神通。它们如同探险家,不断开辟新的领域,在各自的任务中表现出色。这些模型通过生成长推理链,展现出强大的推理能力,为解决复杂问题提供了新的思路。
然而,LRM 在追求强大推理能力的同时,却忽视了效率问题。这就像一辆追求速度的赛车,却在城市道路上频繁急刹,造成了资源的浪费。现有研究多集中于提升 LRM 的性能,却鲜少关注其在实际应用场景中的效率表现,这使得 LRM 在面对简单任务时,依然会启动复杂的推理过程,导致计算资源的浪费。
过度思考的困境
以一个简单的数学计算为例,对于 “2 + 2” 这样的问题,LRM 会启动完整的推理过程,生成详细的思考步骤,这无疑是对计算资源的浪费。过度思考现象在实际应用中屡见不鲜,它如同一个无形的黑洞,吞噬着宝贵的计算资源,导致延迟增加,用户体验下降。
研究显示,过度思考在简单查询中会导致性能提升有限,却消耗了大量计算资源。这就像在平静的湖面上航行,却依然全速运转船桨,既浪费了能量,又未能显著提升速度。对于 LRM 来说,如何在推理能力和效率之间找到平衡点,成为需要解决的问题。
人类认知的智慧启示
人类在面对复杂问题时,会分析各种线索;而在面对简单问题时,则凭借直觉快速作答。这种认知模式如同一个智能的切换开关,能够在不同情境下灵活调整思考方式。
借鉴人类认知模式,LHRM 的设计理念被提出。它如同一个可以自适应思考模式的智能助手,能够根据查询的难度和类型,动态选择思考模式。这不仅提高了模型的效率,还保留了其强大的推理能力,使其在实际应用中更加实用。
LHRM 技术创新
混合推理模型架构分析
LHRM 拥有两种思考模式,思考模式(Thinking)如同一个深思熟虑的学者,会生成详细的推理过程;无思考模式(No-Thinking)则像一个敏锐的直觉者,直接给出答案。这种双模式架构使模型能够在不同任务中自由推理。
模型的目标是为每个查询选择最优的推理模式,以最大化任务特定效用函数的期望值。这如同一个智能的导航系统,能够根据路况选择最佳路线,确保模型在处理各种任务时都能达到最佳性能。
两阶段训练管道的深度剖析
第一阶段:混合微调(HFT)
HFT 阶段整合了推理密集型和直接答案型数据,为模型提供了丰富的学习素材。推理密集型数据来源于高质量的数学、代码和科学问题数据集,如 DeepSeekR1 的数学数据集和 OpenR1-Codeforces 数据集等;直接答案型数据则从 WildChat-1M 等对话数据中筛选出简单查询,通过 FastText 分类器排除复杂推理任务。
下表展示了第一阶段的数据分布和来源,涵盖了推理密集型和直接答案型数据的详细信息,包括数据集的类别、来源和大小等。这些数据为 HFT 阶段提供了多样化和高质量的学习素材,确保模型能够充分学习到不同任务的特点。
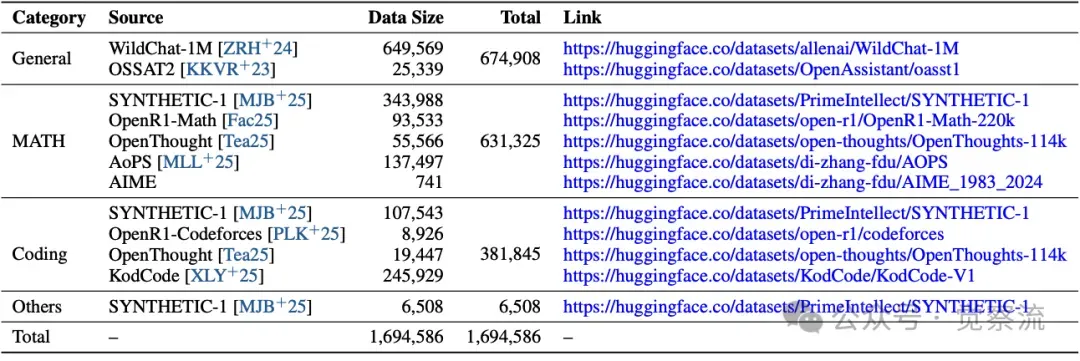
第一阶段的数据分布及来源
训练过程中,通过动态调整两种数据的占比,确保模型能够充分学习到两种思考模式的特点。例如,在训练初期,推理密集型数据占比约为 70%,随着训练的进行,逐渐调整到 50%,以平衡两种数据的影响。
基于构造的数据集,训练模型next token predict,为第二阶段强化学习奠定坚实基础。这一步骤如同为模型安装了一个精准的导航系统,使其在后续的学习中能够朝着正确的方向前进。
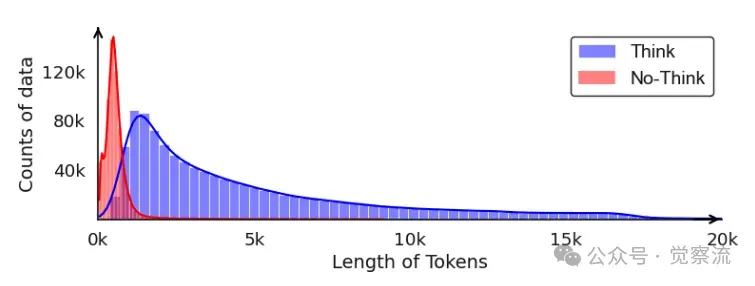
第一阶段思考数据和非思考数据的标记长度分布
上图描述了第一阶段中思考模式(Thinking)和无思考模式(No-Thinking)数据的token长度分布情况。思考模式数据的平均长度为 575 个token,而无思考模式数据的平均长度为 4,897 个token。这表明推理密集型任务通常需要更长的推理过程,而直接答案型任务则更加简洁直接。
第二阶段:混合组策略优化(HGPO)的深度探索
为每个查询在两种推理模式下分别采样多个候选响应。这如同在茫茫大海中撒网,尽可能多地捕获潜在的优质答案。具体而言,对于每个查询,使用旧策略 πθHFT 在思考模式和无思考模式下分别采样 N/2 个候选响应。例如,当 N=4 时,为每个查询采样 2 个思考模式响应和 2 个无思考模式响应。
下图展示了 HGPO 的工作流程,包括(1)使用两种推理模式对每个查询 q 采样多个响应;(2)通过奖励模型对响应进行评分,并根据公式 9 分配奖励;(3)计算优势值和策略损失,并更新策略模型。AE 表示优势估计器,奖励分配表示公式 9。
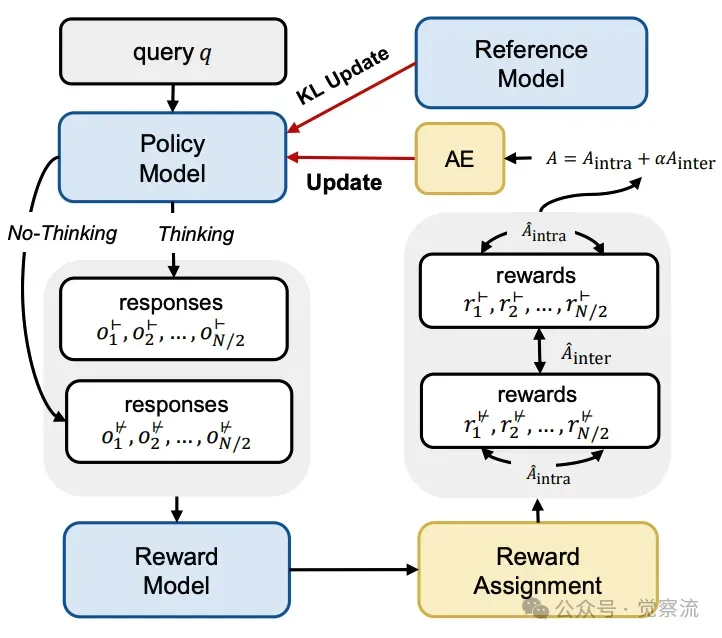
混合组策略优化的演示
应用奖励函数对候选输出进行评分,并基于规则分配组内和组间奖励。这一步骤如同对捕获的鱼进行筛选,选出最优质、最符合要求的答案。我们可以首先计算每种模式的平均奖励,然后基于平均奖励分配组间奖励,同时在每种模式内分配组内奖励。例如,在一个查询的采样响应中,思考模式的平均奖励为 8.5,无思考模式的平均奖励为 7.5,那么思考模式的响应将获得组间奖励 1,而无思考模式的响应将获得组间奖励 0。同时,在每种模式内,奖励最高的响应将获得组内奖励 1,其他响应获得组内奖励 0。

通过最大化目标函数来更新策略模型,同时控制 KL 散度以保持模型稳定性。这如同在风浪中驾驶船只,既要追求速度,又要保持稳定,确保模型在优化过程中不会偏离正确的方向。具体的目标函数为:
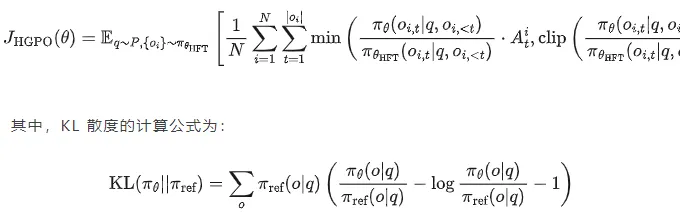
以下伪代码演示的算法详细描述了 HGPO 的算法步骤,包括初始化策略模型、采样响应、计算奖励、分配奖励、计算优势值和更新策略模型等过程。

混合组策略优化算法
混合思考能力评估指标——混合准确率(HAcc)
HAcc 指标如同一把精准的尺子,用于衡量模型正确选择推理模式的能力。它不仅关注模型的答案是否正确,更关注模型是否选择了最适合的推理方式。基于奖励模型对两种模式下生成的响应进行评分,确定每个查询的最优推理模式,计算模型选择模式与最优模式一致的比例。具体计算公式为:

实验设计与结果分析
实验设置的深度剖析
与多种 LLM 和 LRM 进行比较,包括 Qwen2.5 系列模型和 DeepSeek-R1-Distill 系列模型。这如同在竞技场上邀请多位选手同台竞技,确保实验结果的全面性和客观性。
涵盖推理能力(数学和编程相关基准测试)、通用能力(开放式生成任务)以及混合思考能力(HAcc)。这如同从多个角度审视选手的表现,确保评估结果的全面性和准确性。
详细说明两阶段训练的数据集、优化器、学习率等参数设置。例如,在第一阶段,使用 1.7M 条混合格式的训练样例,训练 3 个 epoch,采用 AdamW 优化器,最大学习率为 1e−4,批大小为 128,最大序列长度为 32k tokens。在第二阶段,从 Deepscaler 和 Tülu3 数据集中随机采样 76K 个查询,使用 Llama-3.1-Tulu-3-8B-RM 作为参数化奖励模型,采用 AdamW 优化器,常数学习率为 1 × 10−6,批大小为 256,微批大小为 8,设置 α = 1.0 和 margin = 0.2。
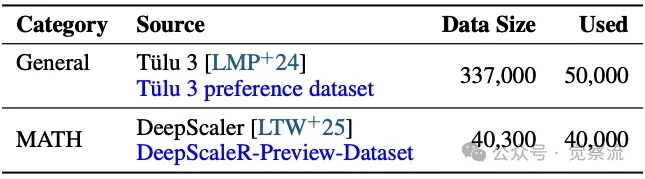
第二阶段的数据分布和来源上表展示了 Stage II 的数据分布和来源,涵盖了从 Deepscaler 和 Tülu3 数据集中采样的详细信息,确保训练数据的多样性和质量。
主要结果的深度解读
LHRM 在 1.5B 和 7B 参数规模下均超越所有基线模型,在数学、编程和通用任务上表现出色。例如,在 MATH500 数据集上,LHRM-1.5B 的准确率为 87.8%,相较于 HFT-DPO-1.5B 的 86.8% 有显著提升;在 Alpaca 和 Arena-Hard 任务上,LHRM-7B 分别比 HFT-DPO-7B 高出 50.2% 和 93.4%。
LHRM 在 HAcc 指标上显著领先,证明其能有效适应不同难度和类型的查询。例如,在 MATH500 数据集上,LHRM-1.5B 的 HAcc 为 93.8%,远高于 HFT-DPO-1.5B 的 48.1% 和 HFT-RFT-1.5B 的 38.3%。
分别探讨 HFT 和 HGPO 阶段对模型性能的影响,验证两阶段训练的有效性。例如,HFT 阶段使模型在推理能力和通用能力上均得到显著提升,而 HGPO 阶段进一步优化了模型的推理模式选择能力,使模型在 HAcc 指标上取得了巨大进步。

不同任务间的性能比较上表展示了不同模型在各项任务上的性能对比,包括 MATH500、AIME24、AMC23、Olympiad Bench、LiveCodeBench、MBPP、MBPP+、AlpacaEval 2.0 和 ArenaHard 等。LHRM 在所有任务中均表现出色,尤其在 HAcc 指标上显著领先。
深入分析的全方位探索
不同优势估计器的影响
比较 REINFORCE++、GRPO 和 RLOO 等估计器在 HGPO 训练中的效果,证明 HGPO 对估计器选择的鲁棒性。例如,使用 REINFORCE++ 时,模型的 HAcc 为 92.5%,使用 GRPO 时为 93.8%,使用 RLOO 时为 91.2%。进一步分析表明,REINFORCE++ 在处理复杂推理任务时收敛速度较快,但 GRPO 在简单任务中能更稳定地选择最优模式。这使得在实际应用中,可以根据任务的复杂程度选择合适的估计器,以达到最佳的训练效果。
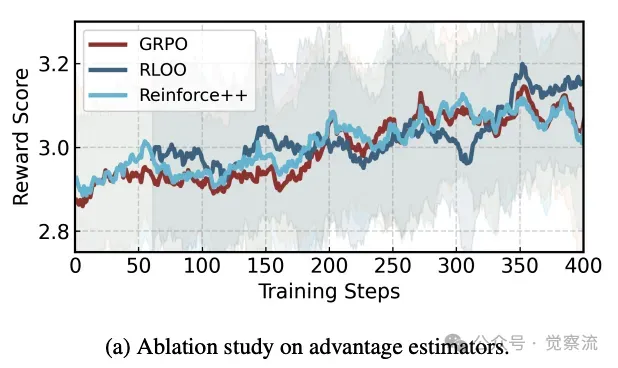
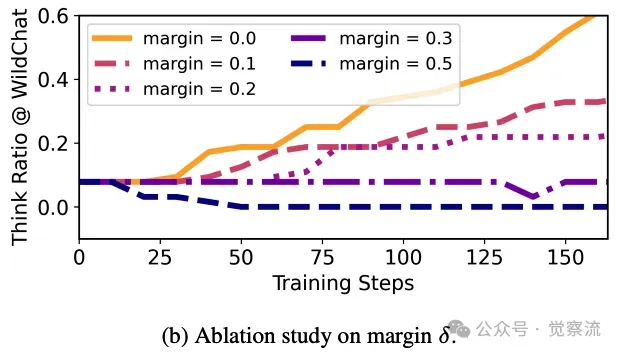
关于优势估计器和边界值δ影响的消融研究上图展示了不同优势估计器和超参数 δ 对 HGPO 训练效果的影响。结果显示,GRPO 在大多数情况下表现最佳,而 δ 的取值对模型在两种推理模式间的权衡有显著影响。
超参数 δ 的关键作用
分析 δ 不同取值对模型在两种推理模式间权衡的影响,为实际应用中的参数调整提供参考。例如,当 δ=0.2 时,模型倾向于更多地使用思考模式;当 δ=0.5 时,模型更倾向于使用无思考模式。实验表明,在实时性要求较高的场景(如智能客服)中,将 δ 设置为 0.5 可以显著降低响应延迟;而在对推理质量要求极高的场景(如数学证明),δ 设置为 0.2 则能更好地保证推理的准确性。
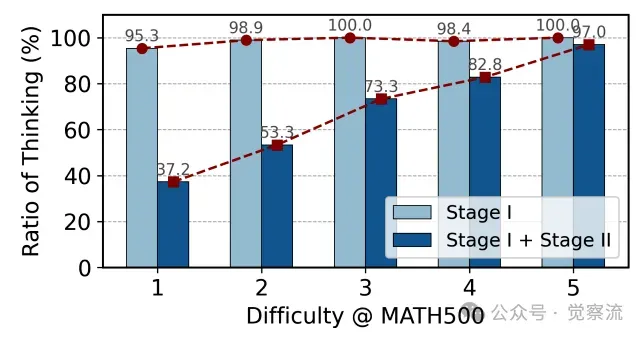
单一领域内LHRM的思维比率分析上图展示了 LHRM 在单一领域内不同难度任务的思考比率分布情况。随着任务难度的降低,模型的思考比率逐渐减少,表明模型能够自适应地选择推理模式,减少不必要的推理步骤。
不同领域中LHRM思维比率的分析上图展示了 LHRM 在不同领域(数学、编程和通用任务)中的思考比率分布情况。结果显示,模型在不同领域中均能根据任务特点动态调整思考模式,确保推理效率和质量的平衡。
模型规模与推理行为的关系
研究 1.5B 和 7B 模型在 RL 训练过程中的思考比率变化,揭示模型规模与推理策略的关系。例如,1.5B 模型在训练初期的思考比率为 70%,随着训练的进行逐渐增加到 85%;而 7B 模型在训练初期的思考比率为 60%,随着训练的进行逐渐减少到 45%。这表明,较小规模的模型在训练过程中需要更多的思考来补偿其有限的参数容量,而较大规模的模型则能更快地掌握任务规律,减少不必要的推理步骤。
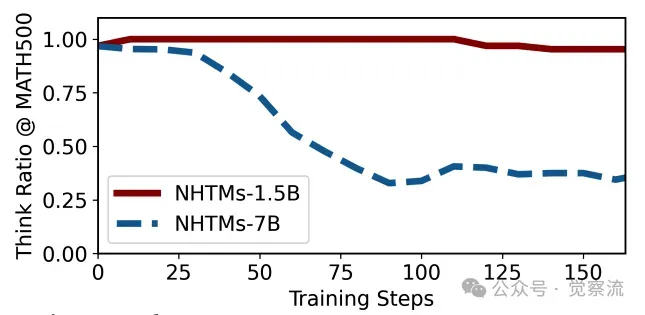
模型规模的消融研究上图展示了模型规模对推理行为的影响。随着模型规模的增大,模型在简单任务中更倾向于使用无思考模式,而在复杂任务中则能更高效地进行推理。
跨领域泛化能力的深度验证
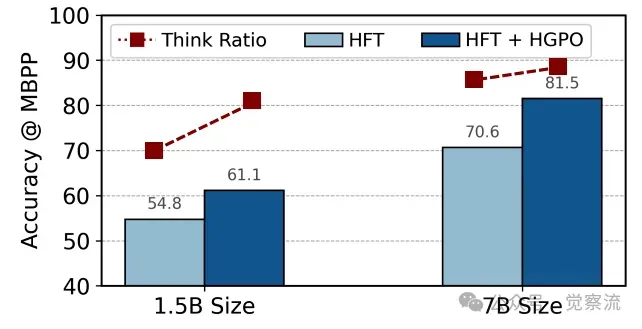
评估在数学和通用领域训练的模型在编程领域的表现,验证 LHRM 的跨领域适应性。例如,LHRM-1.5B 在 MBPP 数据集上的准确率为 61.1%,相较于 HFT-DPO-1.5B 的 53.3% 有显著提升;在 MBPP+ 数据集上的准确率为 63.9%,相较于 HFT-DPO-1.5B 的 55.0% 也有明显提高。进一步分析发现,LHRM 在处理编程任务时,能够通过迁移数学和通用领域的推理策略,快速适应代码生成任务的要求,体现了其强大的泛化能力。

来自DeepSeek-R1-Distill-Qwen-7B和本文的LHRM-7B模型的示例输出上图展示了 DeepSeek-R1-Distill-Qwen-7B 和本文中的 LHRM-7B 模型在简单问题上的示例输出。对于简单问题,LHRM 能够自适应地选择无思考模式,快速给出准确答案,显著提升响应速度。

LHRM-7B采用无思考模式解决简单的数学问题上图展示了 LHRM-7B 在解决简单数学问题时使用无思考模式的示例。模型直接输出答案,无需冗长的推理过程,显著提高了处理简单任务的效率。
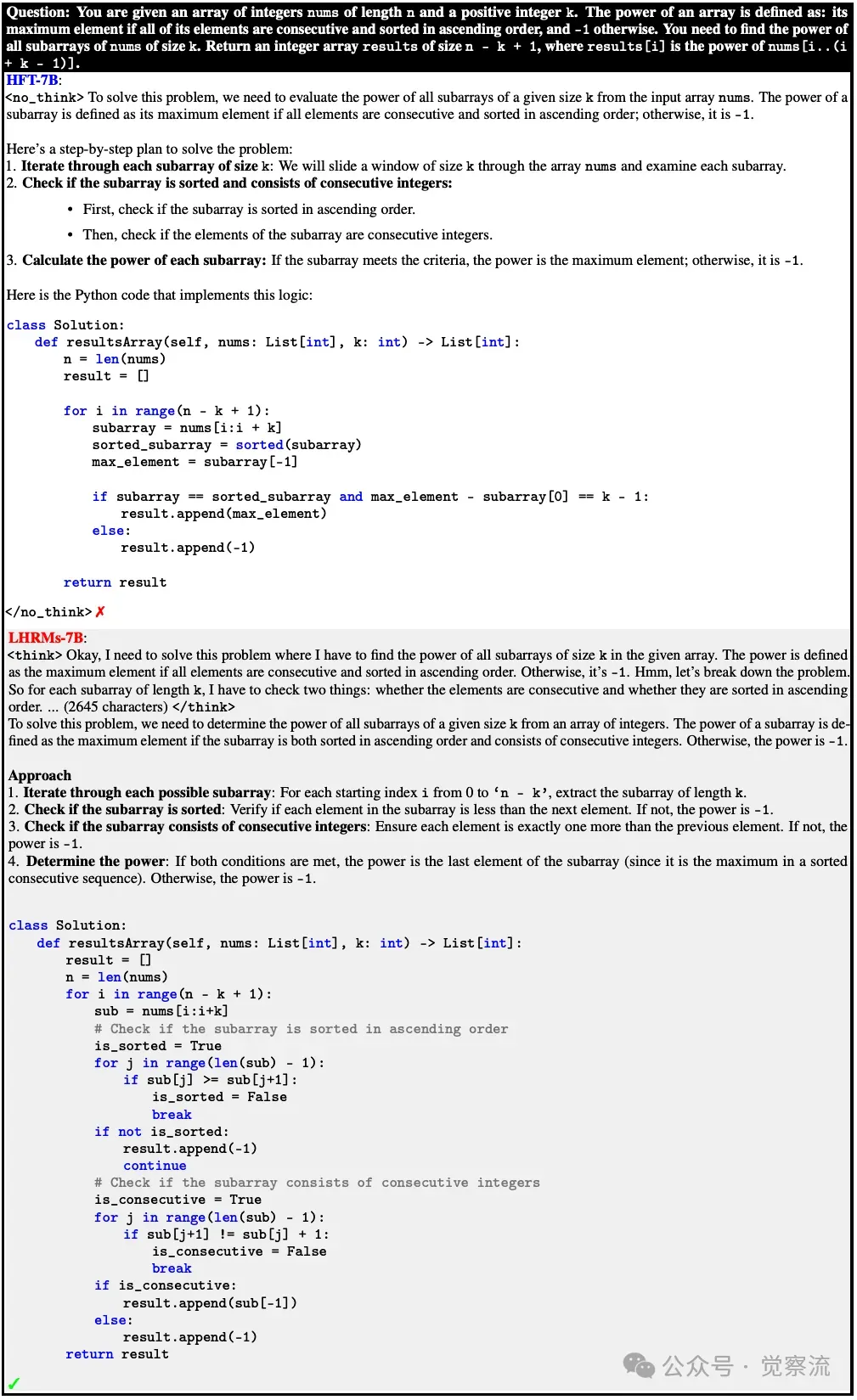
LHRM-7B 学会了选择思考模式来解决复杂的代码问题上图展示了 LHRM-7B 在解决复杂代码问题时选择思考模式的示例。模型生成详细的推理步骤,逐步解决问题,确保推理的准确性和完整性。
总结与展望
提出混合推理模型架构、两阶段训练管道和 HAcc 评估指标,在提升推理能力和通用性能的同时显著提高效率。这为后续研究提供了新的方向和思路。
在实际应用中,LHRM 的潜力是巨大的。以智能客服为例,LHRM 能够根据用户问题的复杂程度动态调整思考模式。对于简单的查询,如 “如何重置密码”,模型快速切换到无思考模式,直接给出简洁明了的答案,显著降低响应延迟,提升用户体验。而对于复杂的技术支持问题,如 “服务器频繁崩溃的原因分析”,LHRM 则启动思考模式,生成详细的推理步骤,逐步排查问题,最终提供精准的解决方案。这种智能切换不仅提高了客服效率,还确保了问题解决的准确性。
在自动编程领域,LHRM 根据代码逻辑的难易程度选择推理模式。对于简单的代码生成任务,如 “生成一个计算数组平均值的函数”,模型快速输出代码,满足开发者的即时需求。而对于复杂的算法设计问题,如 “优化大规模数据处理的分布式算法”,LHRM 则通过深度推理,逐步构建算法框架,验证其正确性和性能,帮助开发者攻克技术难题。这种高效的代码生成和算法设计能力,将极大地推动软件开发的智能化进程。
在数学教育领域,LHRM 为学生提供个性化的数学问题解答和推理过程指导。对于基础的数学运算问题,如 “解一元二次方程”,模型直接给出答案和简洁的步骤,帮助学生快速掌握解题方法。而对于复杂的数学证明题,如 “证明费马大定理在某些特殊情况下的成立”,LHRM 则生成详细的推理过程,引导学生逐步理解证明逻辑,培养其数学思维能力。这种因材施教的智能辅导方式,将为数学教育带来革命性的变化。
参考资料
- Think Only When You Need with Large Hybrid-Reasoning Models
https://arxiv.org/pdf/2505.14631
- github repo - hiyouga/LLaMA-Factory
https://github.com/hiyouga/LLaMA-Factory
- github repo - volcengine/verl
https://github.com/volcengine/verl