大模型,如今堪称AI界的「吞金巨兽」。
从写诗到解题,从对话到编程,它们几乎无所不能,但动辄千亿甚至万亿参数的规模,让部署成本高得离谱。
以FP16精度部署的DeepSeek-R1 671B为例,推理时大概需要1342GB的显存,如果是32GB 5090显卡,需要整整42张!
为了降低成本,天才工程师们想出了后训练量化(Post-training Quantization,PTQ)的方法,它能够在有限的校准数据和计算资源下对模型进行高效压缩。
但是PTQ依然带来新的问题——在极低比特精度(如W2A16、W4A4)时往往会出现明显的性能下降,规模是降了,但是不好用了!
就在这关键时刻,华为诺亚方舟实验室联合中科大亮出了「杀手锏」——CBQ(Cross-Block Quantization),一种基于跨块重建的后训练量化方案。

论文地址:https://openreview.net/pdf?id=eW4yh6HKz4
相比量化感知训练(QAT)所需数据量,CBQ仅用0.1%的训练数据,一键压缩大模型至1/7体积——浮点模型性能保留99%,真正实现「轻量不降智」。
值得一提的是,这项成果已荣登ICLR 2025 Spotlight(录取率仅5%)。
它不仅展现了大模型压缩领域的创新性和实用性,更像一颗信号弹,宣告大模型在国产算力上的普及时代已然来临!
目前,CBQ已作为可调用的算法之一,正式加入昇腾模型压缩工具包ModelSlim,帮助开发者在昇腾芯片上实现LLM的高效部署。
极低比特量化,为何如此难?
长期以来,后训练量化(PTQ)一直是压缩大语言模型的「黑科技」——通过解决异常值和采用layer-wise或block-wise的loss优化技术取得了比较不错的结果。
但是当把参数比特「压得特别低」的时候,模型性能会严重下降。
为什么极低比特量化,如此困难?其实,答案隐藏在大模型的复杂结构中。
研究者们对LLM在低比特量化场景下的量化误差进行了深入分析,发现了问题的关键所在:
随着模型参数数量的增加和量化bit数的减少,模型内部的层间依赖(inter-layer dependencies)和层内依赖(intra-layer dependencies)会显著增强,这严重影响了量化精度。
如下实验所示,清晰展示了LLAMA-7B层间与层内的依赖关系。
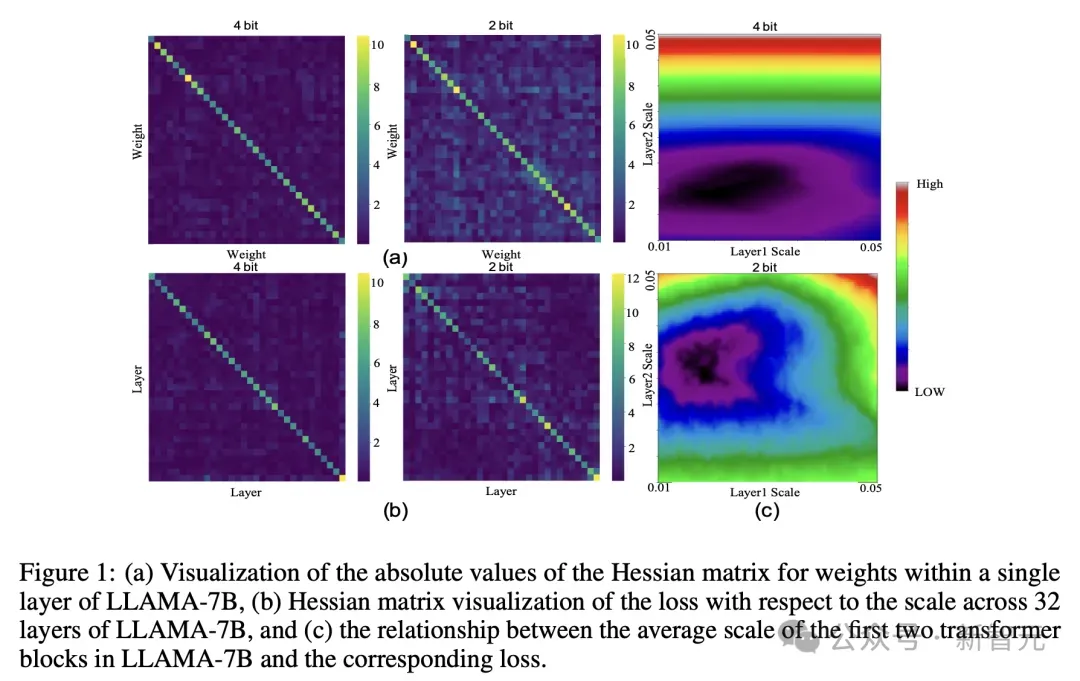
图1:Llama-7B内部权重和层之间依赖关系的变化,以及层间缩放因子(scale)对误差的影响
图1(a)为LLAMA-7B单一层中权重的Hessian矩阵绝对值可视化,2-bit图比4-bit更模糊,非对角线噪声增多,表示在低比特下权重间的「干扰」增强了。
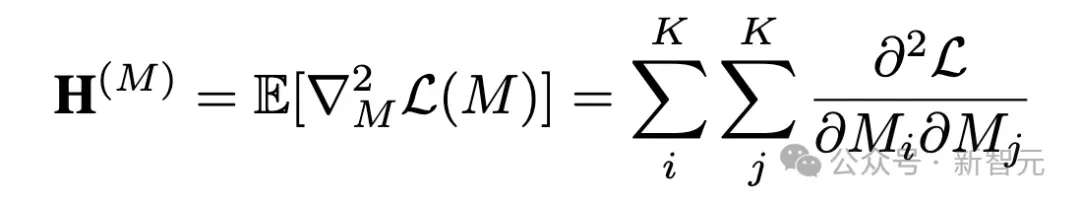
图1(b)为LLAMA-7B 32层中损失相对于scale的Hessian矩阵可视化,在2-bit量化中,非对角线明显比4-bit更亮,说明层间依赖增强,模型更容易因为一层的误差影响到另一层。
以及图1(c)LLAMA-7B前两个Transformer块的平均scale与相应损失之间的关系,4-bit情况下,误差平稳区域大,模型对 scale 不敏感。2-bit情况下,误差对scale非常敏感,选择不当误差急剧上升,黑色区域更集中、易出错。
总结来说,将模型参数从高精度压缩到低精度,这一过程主要面临三大核心挑战:
1. 层间依赖的「雪球效应」
大模型由多个Transformer层组成,各层参数之间存在复杂的相互依赖。
在极低比特量化时,量化误差会在层间不断累积放大,就像「滚雪球」一样,导致整体性能严重下降。
然而,传统逐层量化的方法,无法有效捕捉这些层间依赖,进而造成了精度损失。
2. 层内依赖的复杂性
同一层内的参数并非独立存在,而是存在紧密的关联性。
极低比特量化会破坏这些精细的层内依赖,导致模型在处理复杂任务时「力不从心」。
比如,大模型语义理解或推理能力,可能因参数精度的降低而显著退化。
3. 权重和激活的异常值
模型的权重和激活值中的异常值,在低比特量化时会引发较大的误差。
传统的方法无法精确识别和处理这些异常值,进一步加剧了量化误差。
可见,这些挑战让低比特量化,成为大模型压缩的「拦路虎」。
那么,华为的CBQ方案,是如何突破这些瓶颈?让我们一探究竟!
CBQ打破层间壁垒,精准又高效
CBQ的核心思想是,通过跨块依赖(Cross-Block Dependency, CBD)机制和自适应LoRA-Rounding技术,同时优化多个Transformer块的量化参数,从而更好地保留模型内部的依赖关系。
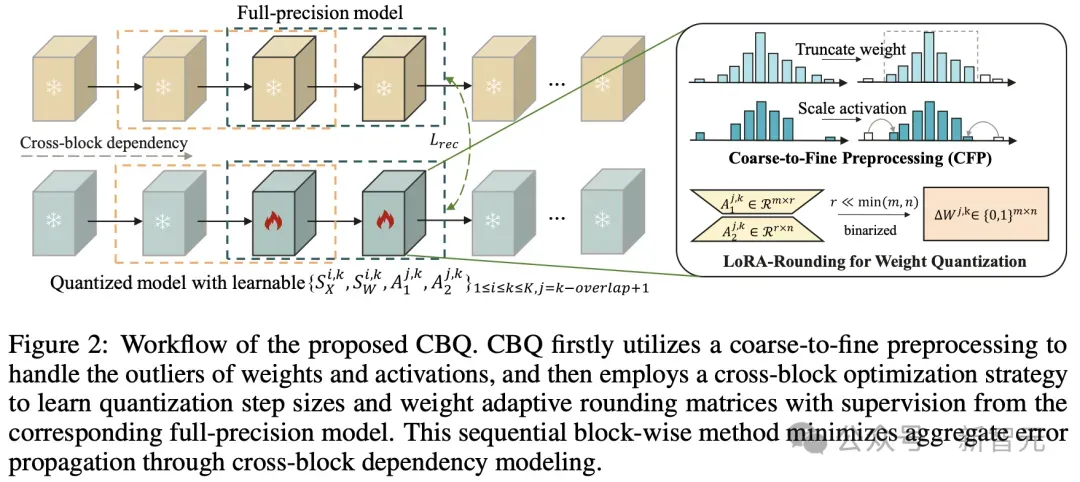
具体来说,它通过三大技术创新,为极低比特量化注入了全新活力。
跨块依赖机制(CBD)
刚刚也提到,传统量化方法采用逐层优化,却忽视了层间依赖的复杂性。
CBQ引入了CBD机制,通过滑动窗口的方式,同时优化多个Transformer块,并且相邻窗口之间会有重叠的块,以确保块之间的连接性和协作性。
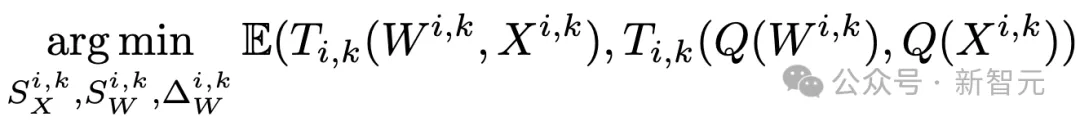
这种方法,可以有效地捕捉到模型内部的长距离依赖关系,使得相邻的块能够共同参与到量化过程中,从而提高整体的量化性能。
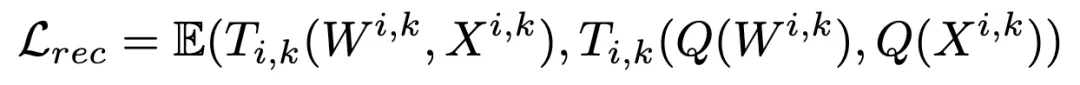
在实验中,随着滑动窗口中块的数量增加,模型的性能也得到了显著提升。
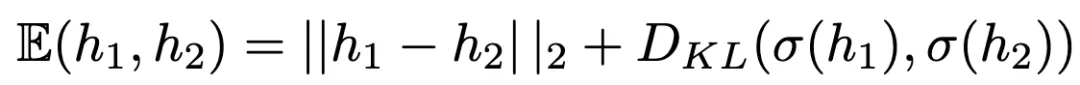
自适应LoRA-Rounding技术
为了应对层内依赖的复杂性,CBQ提出了自适应LoRA-Rounding技术,通过两个低秩矩阵来学习量化权重的自适应补偿值。
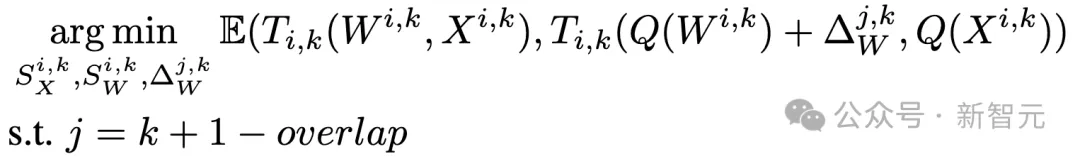
与传统的AdaRound方法相比,LoRA-Rounding通过低秩分解大大减少了可学习参数,训练速度更快,GPU内存消耗更低。
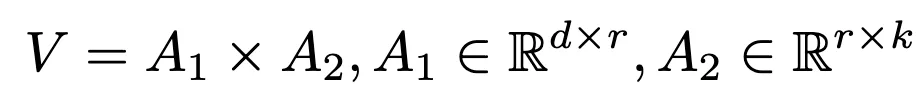
这种方法能够在训练过程中动态调整权重的量化精度,从而更好地适应模型的内部结构和数据分布。
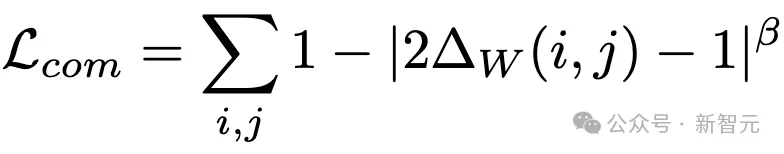
粗到细的预处理策略(CFP)
针对异常值问题,CBQ采用了粗到细的预处理策略(Coarse-to-Fine Preprocessing, CFP)。
CFP策略从统计学的角度出发,通过分阶段检测和处理权重和激活中的异常值。
在粗粒度检测阶段,通过计算四分位数和四分位距来初步估计异常值的范围;在细粒度检测阶段,通过最小化异常值子集与正常值子集之间的距离,同时最大化子集内部的方差,来精确识别异常值的位置。
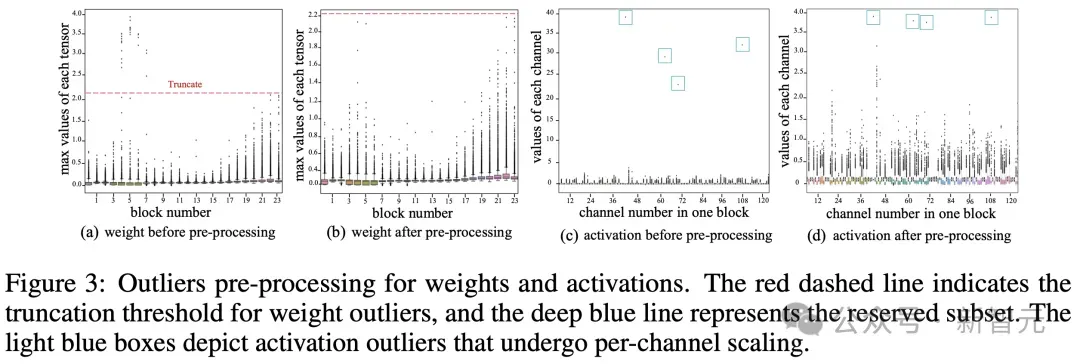
这种分阶段策略,有效减少了量化误差,确保模型在低比特场景下依然「稳如泰山」。
那么,CBQ在场景中的真实表现又如何呢?
实验结果:性能与效率的双赢
一系列研究结果显示,CBQ在华为盘古模型和开源模型的表现上,大放异彩。
盘古模型:端侧部署「杀手锏」
CBQ量化技术已成功应用于华为盘古大模型PanGu-7B和PanGu-1.5B的端侧部署,凭借其高精度的量化性能,有效支撑了盘古大模型在多个业务场景的落地应用。
如下表所示,在W8A8/W4A16精度下,PanGu-1.5B模型在中文(C-Eval/CMMLU)、多任务语言理解(MMLU)基准中的表现,毫不逊色于全精度模型的性能。
在中文、多语言理解、数学基准中,PanGu-7B的表现同样如此。
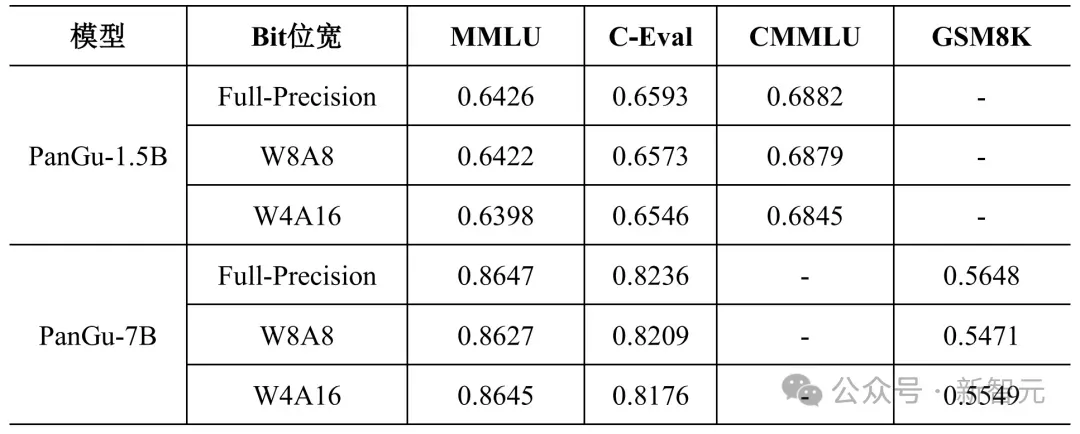
这些成果,足以让盘古模型在手机等终端设备上,轻松运行。
开源模型:超越最优
此外,CBQ在多个开源LLM(如OPT、LLaMA)上也取得了SOTA。
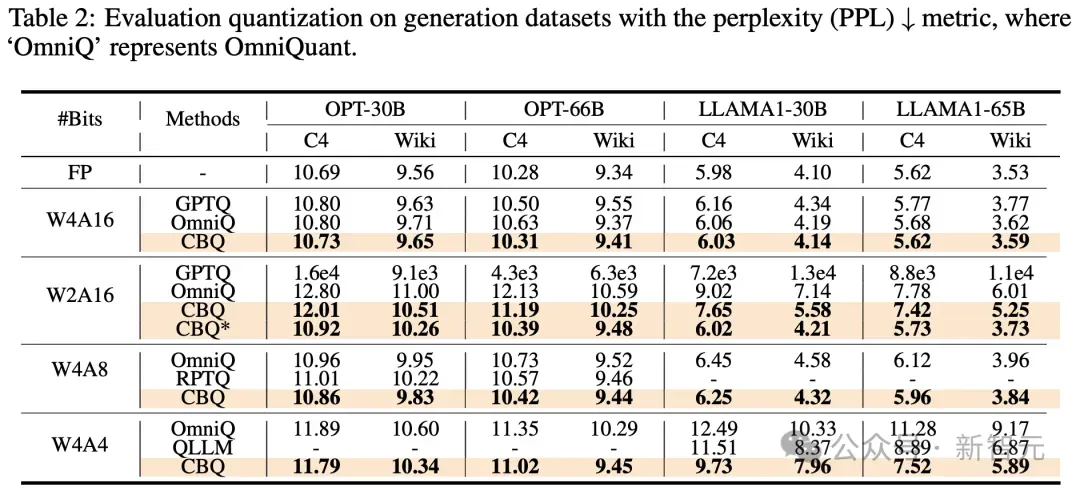
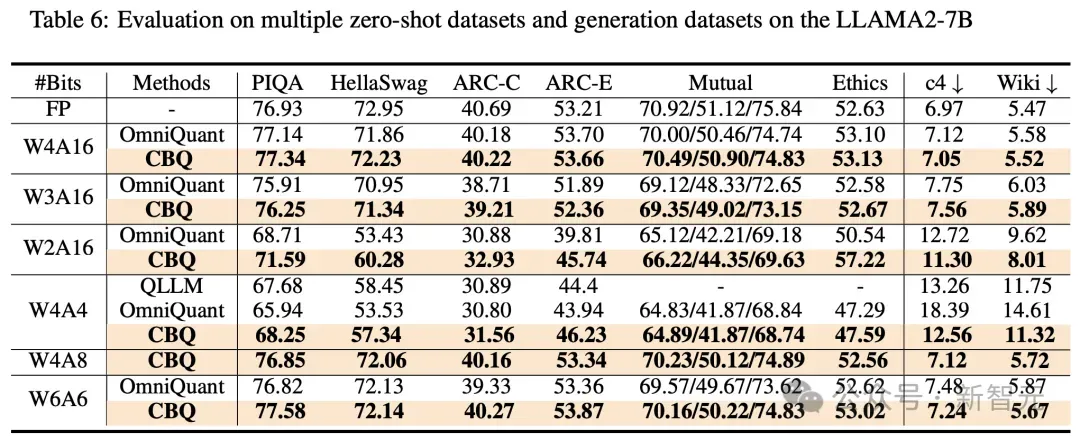
例如,在W4A16、W2A16和W4A8等低比特量化设置下,CBQ的性能均优于现有的最先进方法,并且与全精度模型的性能差距缩小到了1%以内。
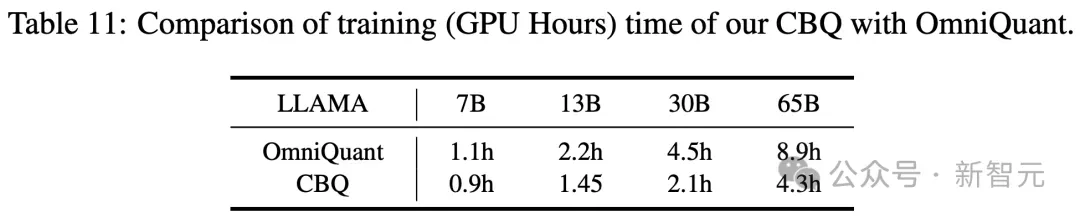
更令人惊叹的是,CBQ仅需4.3小时即可完成对4位权重的LLaMA1-65B模型的量化,展现了压缩率与精度之间的完美平衡(trade-off)。
未来展望
华为的CBQ方案,以跨块依赖机制、自适应LoRA-Rounding技术,以及粗到细的预处理策略,成功征服了极低比特量化的「三大高峰」。
这项创新有效地解决了,大模型在低比特量化场景下所面临的层间依赖和层内依赖难题。
它不仅在多种大语言模型和数据集上展现出了显著的性能提升,成功缩小了与全精度模型之间的差距,还以高效的量化效率实现了复杂模型的快速压缩。
最终,让盘古和各类开源模型,成功实现了在昇腾硬件上的高效部署,并为更加广泛的应用铺就坦途。


