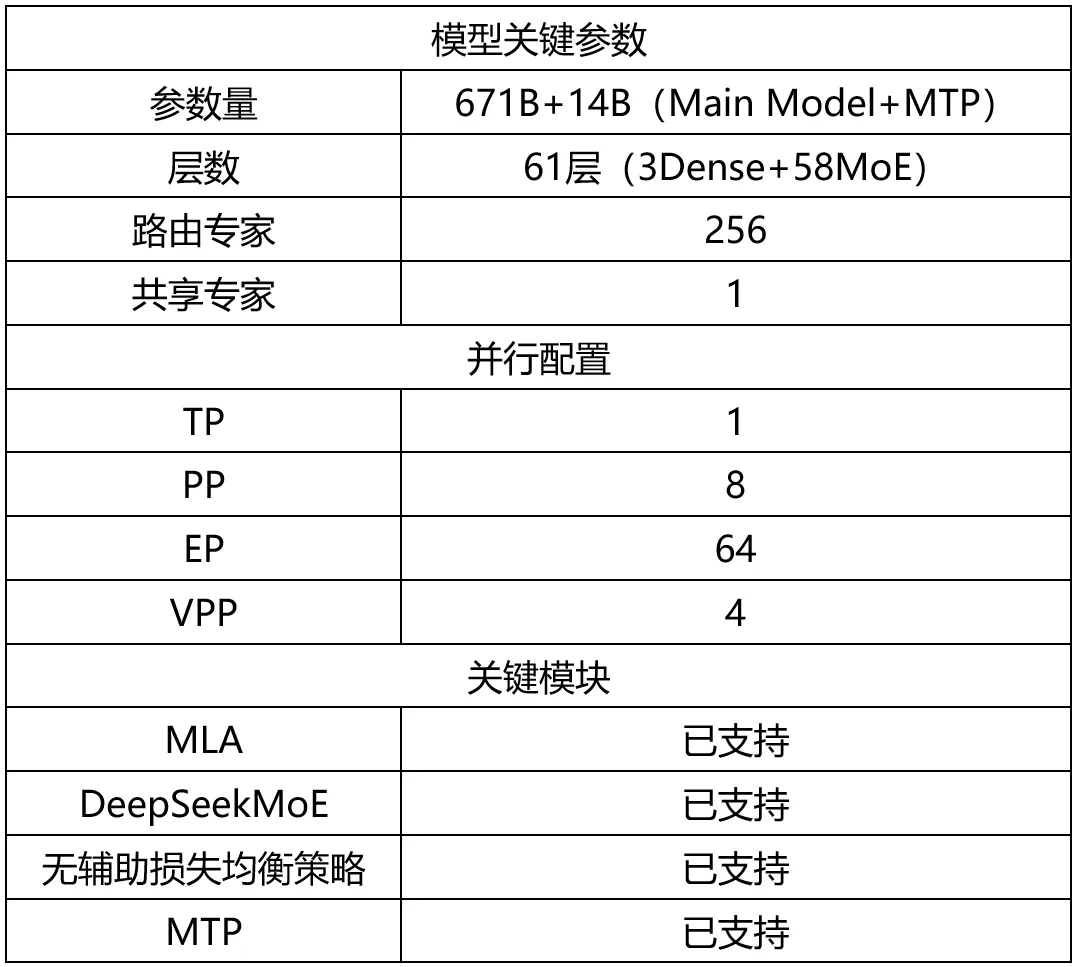
据介绍,MindSpeed 现已支持 DeepSeek V3 模型预训练与微调。所使用的并行配置与模型参数如下:
DeepSeek 团队通过知识蒸馏,实现了较小的模型也能具备较强的推理能力。华为称已基于昇腾完成蒸馏流程验证,并表示经过蒸馏后的 Qwen 模型在对应领域上的评分获得显著提升,开发者可基于此参考,完成自定义蒸馏模型训练。
另外,华为昇腾还适配完成 Open R1 项目的重要步骤:打通 Open R1-Zero 的 GRPO 流程,同时支持通过 vLLM 等生态库实现训练过程中的数据生成。
据介绍,Open R1 项目是 Hugging Face 官方开源的对 DeepSeek-R1 模型流程进行完全开放式复现的项目,是当前主流复现项目之一,当前已有 18K+ star 数,其目标是构建 DeekSeek-R1 训练流程的缺失部分。