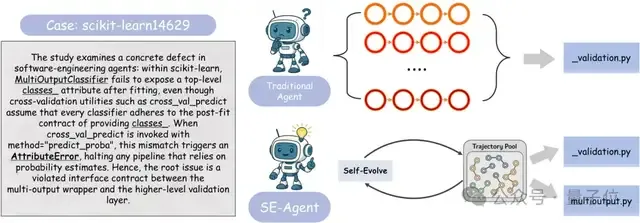
在全球人工智能发展的浪潮中,模型推理的速度和效率愈发成为焦点。近期,华为的数学团队在 DeepSeek 开源周期间推出了名为 FlashComm 的新技术,旨在通过三项创新措施,大幅提升大模型推理的性能,最高可达80% 的速度提升。
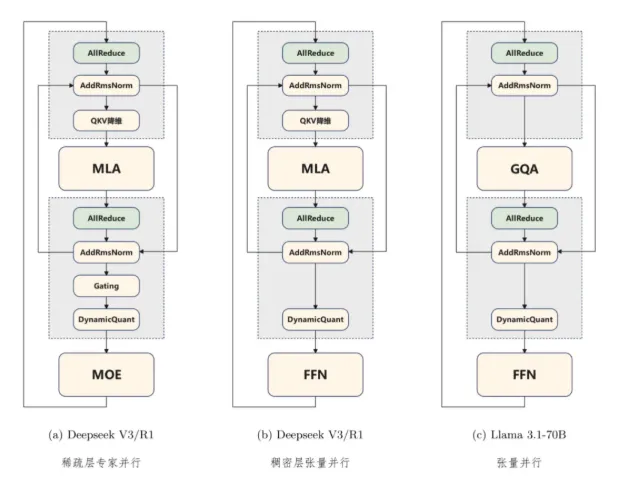
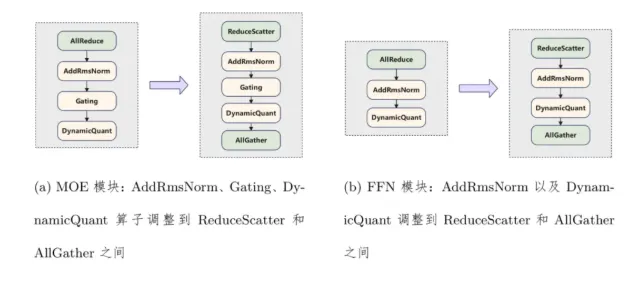
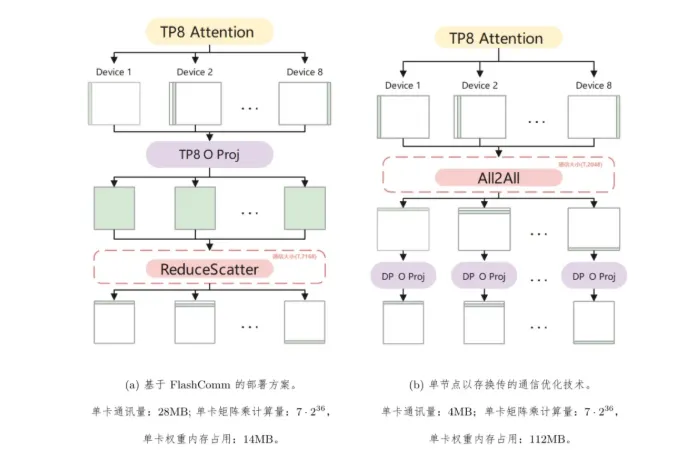
首先,FlashComm 技术重点优化了 AllReduce 通信操作。传统的 AllReduce 方法就像一辆装满货物的集装箱车,不够灵活。华为团队通过智能化手段,将数据分为两部分:先进行 ReduceScatter,然后再进行 AllGather。这一重组过程使得后续的通信量减少了35%,同时关键计算量也减少到原来的1/8,推理性能提升了22% 到26%。
其次,在推理过程中,华为发现可以通过调整矩阵乘法的并行维度来减轻通信负担。在保持结果精确的前提下,三维张量被 “压扁” 成二维矩阵,结合 INT8量化技术,数据传输量骤降86%,整体推理速度提升33%。这一策略就像将大型货物装入小型集装箱,让数据传输变得更加高效。
最后,华为的多流并行技术打破了传统串行计算的局限。在 MoE 模型的推理过程中,华为团队将复杂的计算流程进行拆解和重组,借助昇腾硬件的多流引擎实现了三条计算流的精准并行。这种方法可以在一组数据进行专家计算的同时,另一组数据已经进入门控决策阶段,从而最大限度地提高计算效率。
FlashComm 的发布标志着华为在大模型推理领域的一次重大技术突破。这不仅将提升模型的推理速度,还将推动人工智能应用的发展,为科研和工业领域的 AI 应用带来新的机遇。