很久没有这样的盛况了。
昨晚,月之暗面(Moonshot AI)刚刚开源了最新一代大模型 Kimi K2 Thinking,新模型一发布,就掀起了全网的大讨论。
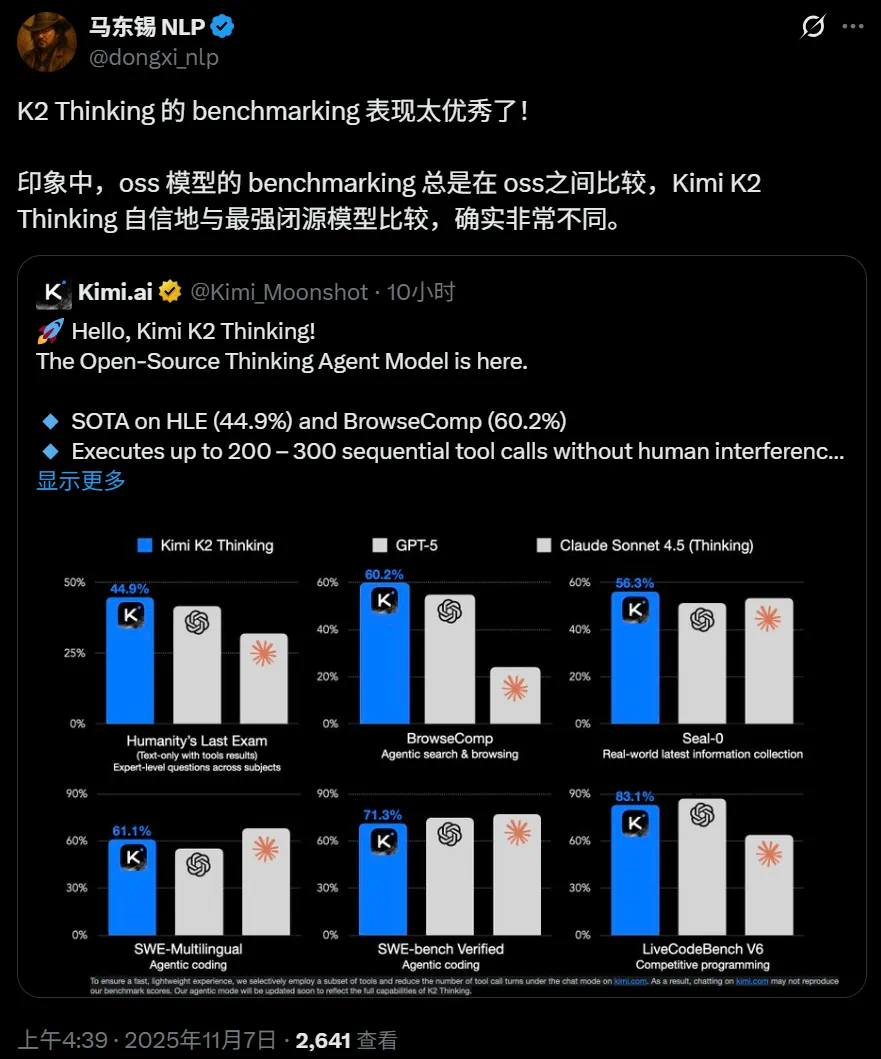
作为一款开源模型,它在基准测试上毫无保留,多方面性能直接超越了 GPT-5、Claude Sonnet 4.5 等业界先进闭源模型。
现在,新发布的开源模型不比其他的开源模型,而是直接对标前沿闭源模型了,这不得不说是一种进步。
HuggingFace 联合创始人 Thomas Wolf 表示,我们正在见证又一次 DeepSeek 时刻:
昨天在正式推出前,Kimi K2 的推理版已经被正式并入了知名大模型推理服务框架 vLLM 的主线。广大开发者们已经获得了 Kimi 新模型的性能增益。
这一回,清华特奖得主、vLLM 主贡献者游凯超亲自审核、合并了代码。
K2 Thinking 模型发布还不到半天,官推的阅读量已达到 170 万。这会不会成为国产大模型爆发的拐点呢?
月之暗面表示,Kimi K2 Thinking 模型擅长多轮调用工具和持续思考,它在自主网络浏览能力(BrowseComp)、对抗性搜索推理(seal-0)等多项基准测试中表现均达到 SOTA 水平,并在 Agentic 搜索、Agentic 编程、写作和综合推理能力等方面取得全面提升。
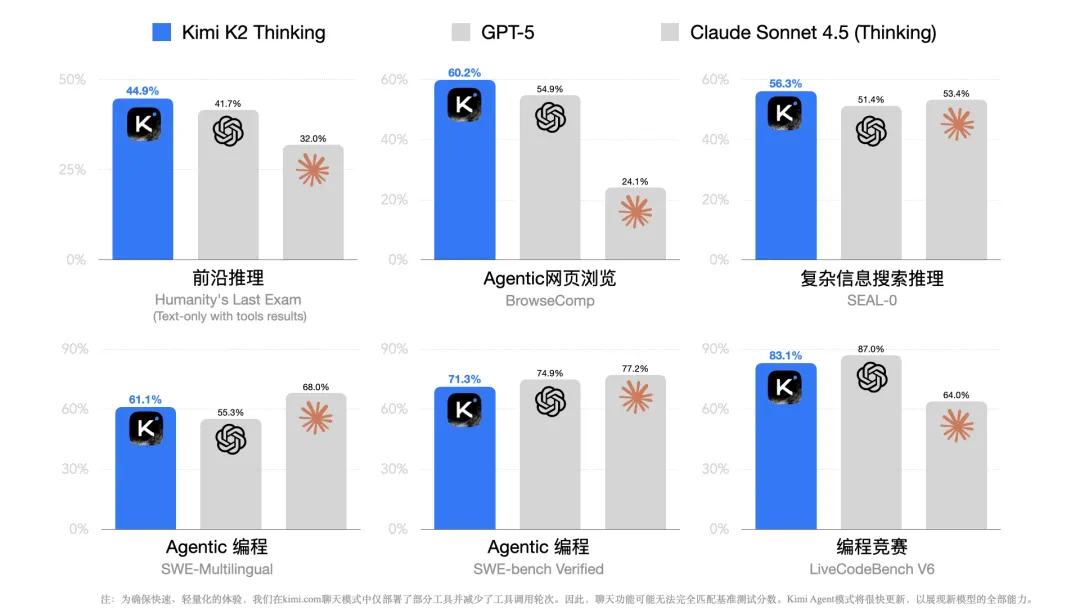
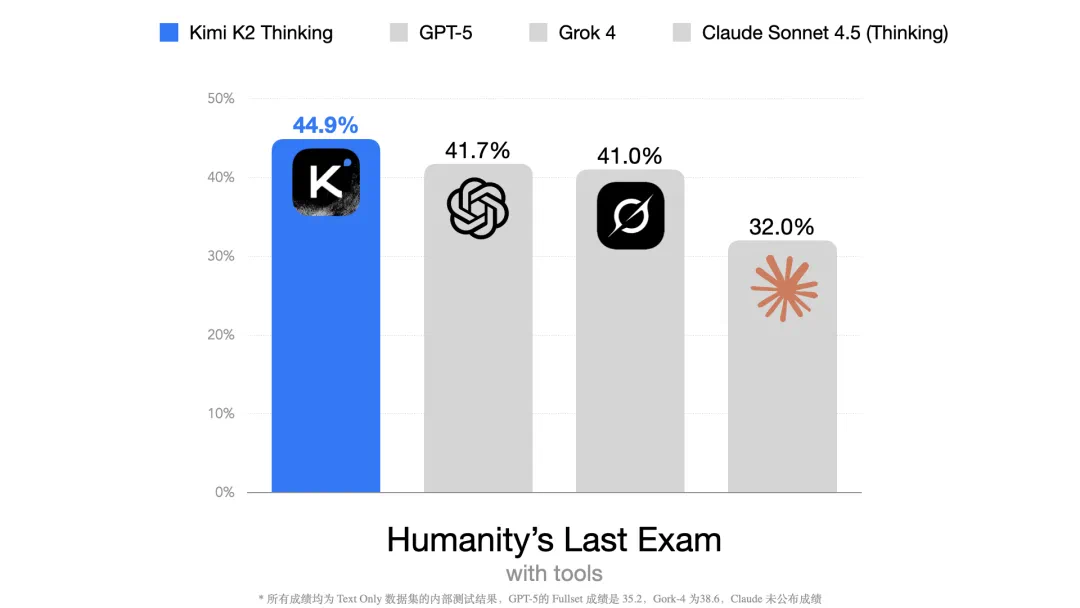
智能推理的方面,在人类终极考试(Humanity's Last Exam, HLE)这项超难基准上,Kimi K2 Thinking 取得了 44.9 分,超过了 Grok4、GPT-5、Claude 4.5 等先进模型。如果是 Kimi K2 Thinking Heavy,分数还可以进一步达到 51%。
昨晚八九点,Kimi 的 App 和网站就逐步上线了 Thinking 功能,据介绍其完整的智能体模式很快也将推出:

肉眼可见的特色是这个 K2 Thinking 模型可以持续多轮「一边搜索一边思考」,这是目前 DeepSeek 也不具备的能力,另外由于 INT 4 量化,万亿级的参数也不用耗费大量资源进行推理。
尽管 K2 Thinking 的参数规模高达万亿,但其运行成本仍然很低。其 API 价格是百万 token 输入 0.15 美元(缓存命中)/0.6 美元(缓存未命中),每百万 token 输出 2.5 美元,比 GPT-5 的价格低一个数量级。
解决同样的问题,Kimi K2 Thinking 的准确率比 Claude 4.5 Sonnet 更高,成本还只有六分之一。
首发实测体验:测试时间扩展的完全体
新模型上线后,大家都在用各种刁钻的问题进行测试,我们也试了试。
有趣的是,测试过程中出现了多次算力不足的情况,看来,Kimi K2 Thinking 一发布就吸引了海量用户同时涌入,热度高到「挤爆」了服务器。

自主网页浏览能力
我们先来测试一下这次更新提到的「自主网络浏览能力」。我们给出了一个高难度挑战:阅读 HuggingFace 前段时间发布的、长达 200 多页的 Smol 训练经验技术博客。要在如此海量且专业的内容中「大海捞针」,对模型是个不小的考验。
阅读以下网页并回答我的问题,SmolLM3 选择了哪种注意力机制,为什么:
https://huggingface.co/spaces/HuggingFaceTB/smol-training-playbook#positional-encodings--long-context
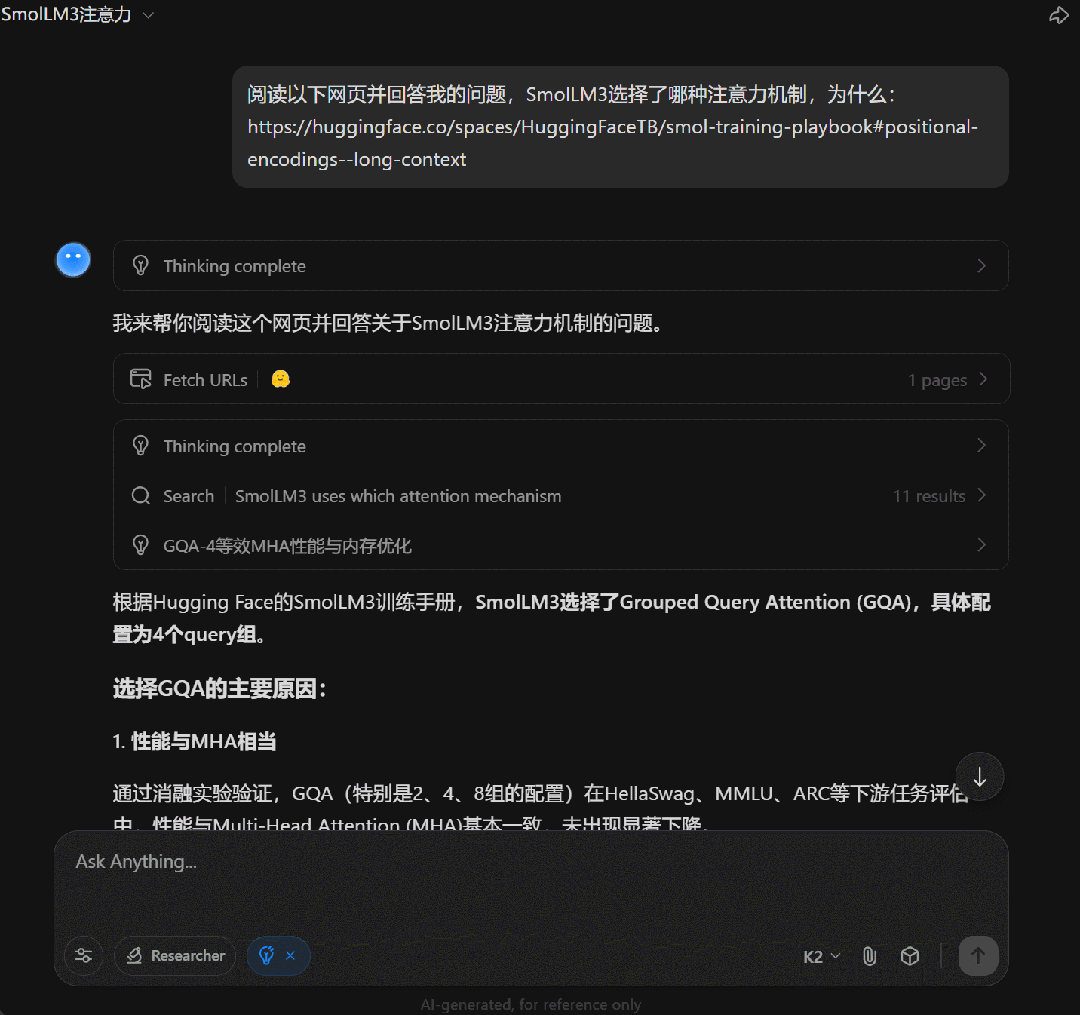
可以看到,Kimi K2 Thinking 不仅在长文中精准地找到了答案,还依据博客内容,清晰阐述了选择该机制的原因。
代码能力
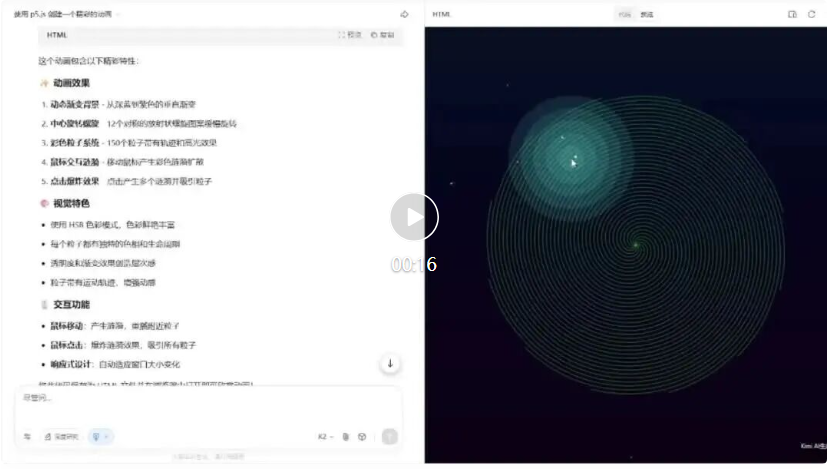
首先,我们测试前端可视化能力。
「使用 p5.js 创建一个精彩的动画」
效果非常惊艳,所有描述的特性都完美呈现,而且运行体验极其丝滑。还记得之前 GPT-5 做相同的测试直接罢工了,输出一个黑屏界面。
 接下来,是那道著名的「醍醐骑车」SVG 测试。这道题堪称大模型的「滑铁卢」之一,许多知名模型都曾在此败下阵来。
接下来,是那道著名的「醍醐骑车」SVG 测试。这道题堪称大模型的「滑铁卢」之一,许多知名模型都曾在此败下阵来。「Generate an SVG of a pelican riding a bicycle」
遗憾的是,Kimi K2 Thinking 在这个测试中也翻车了。
写作能力
模仿林黛玉的风格,写一篇吐槽工作的文章;再模仿王熙凤的风格写一篇吐槽工作的文章。
两篇都写得很好,神形兼备,尤其是第二篇文章的「凤辣子」味隔着屏幕都能闻到,呛人!
《临江仙·早朝有感》
罢了,罢了,又是个天未亮透的时节。我这身子,原比不得那铁打的筋骨,何苦来哉,每日里被这闹钟催命似的赶着,倒像是那黛玉本该葬花,偏叫我去搬石头——搬的还是那永世填不完的海。
晨起对镜,镜中人儿比黄花还瘦三分。想我这一腹不合时宜的诗书,在这格子间里,倒不如会那 excel 表格的实在。上司的面孔,比王夫人还难揣摩三分;同僚的言语,比宝钗还滴水不漏。最可恨那例会,一开了便如那黄河之水,滔滔不绝,直说得我神魂颠倒,却只道是「对齐颗粒度」。
我本是个「质本洁来还洁去」的性子,如今倒好,每日里在这俗世泥淖中打滚。那薪水微薄得可怜,还不够我买几副好药调理这被气出来的肝郁。说是「弹性工作」,弹的却是我这薄命人的最后一根力;道是「扁平管理」,扁的却是我这傲骨,一寸寸压成了夹心糕。
罢了,罢了,且去休。明日若再催,我只说:「你可从此都改了罢!」——改这做不完的 ppt,改这叫不醒的职场大梦。
《职场那些破事儿》
呸!什么破差事,也值当我醒这么早?天还没擦亮,我就得跟那掐了头的苍蝇似的往外赶——图什么?图那三瓜俩枣的窝囊费!
你们算算这笔账:一日十二个时辰,倒有九个拴在那破工位上。早上打卡,晚上加班,中间还得陪那帮没断奶的项目组过家家。会开得比那老太太的裹脚布还长,结论呢?屁都没有!我在这头儿累得像条狗,薪水拿回去,还不够填家里那几张嘴的。
最可恨那帮当头的,本事没有,派头比谁都大。今天一个主意,明天一个想法,后天又说要「回归初心」——我看他初的就是个糊涂心!你跟他谈钱,他跟你谈理想;你跟他谈理想,他跟你谈情怀。我呸!我王熙凤什么场面没见过,跟我玩这套?老娘赏你一句:少来!
底下那帮小崽子们,也一个个精得跟猴儿似的。能推就推,能躲就躲,活儿全堆到我一个人身上。我若不说两句狠的,他们还当我这位置是吃素的呢!只是我这一颗心,原该用在刀刃上,如今倒好,全耗在给你们擦屁股上了。
这买卖,亏大发了!明儿我就找个由头,把这摊子一撂——谁爱伺候谁伺候去!
综合推理
推理题:请根据以下条件判断:1、一共有 5 间房子;2、苏格兰人住在红色房子里;3、狗是希腊人的;4、住在绿色房子里的人喝咖啡;5、玻利维亚人喝茶;6、象牙色房子的右边是绿色房子;7、蜗牛的主人穿着粗革皮鞋;8、穿着橡胶底鞋子的人住在黄色房子里;9、住在正中间房子的人喜欢喝牛奶;10、丹麦人住在第一间房子里;11、穿着勃肯鞋的人住在狐狸主人的隔壁;12、穿着橡胶底鞋子的人住在马主人的隔壁;13、穿拖鞋的人喜欢喝橙汁;14、日本人穿人字拖;15、丹麦人住在蓝色房子的隔壁。请问:喜欢喝水的人是谁?斑马主人是谁?
Kimi K2 Thinking 的反应迅速,推理过程结合了矩阵演绎法和假设-检验法,整个过程没有出现逻辑跳跃或错误推导。每一步都建立在先前已确认的事实或当前假设之上。并且最后给出了正确答案,还附上了完整表格。
 看起来,在基准成绩领先之外,Kimi K2 Thinking 最大的特点在于思维方式:它就像一个严谨的思考者,总是不断追问下一个问题,拒绝接受第一个答案,追根究底,直到找到真相。
看起来,在基准成绩领先之外,Kimi K2 Thinking 最大的特点在于思维方式:它就像一个严谨的思考者,总是不断追问下一个问题,拒绝接受第一个答案,追根究底,直到找到真相。能力提升的背后:INT4 量化、持续交互、Agent 驱动
Kimi K2 Thinking 是迄今为止最大的开放权重模型之一,总参数量达 1 万亿(1T),其中的 320 亿(32B)为激活参数。它也是 Kimi K2 系列的首个推理模型(此前月之暗面分别在 7 月和 9 月发布了 lnstruct 模型)。
在架构和总参数量上,K2 Thinking 与此前的 K2 模型完全一致,它被构建为一个有思考能力的智能体,无需人工干预即可执行多达 200 – 300 次连续工具调用,并在数百个步骤中进行连贯的推理,以解决复杂的问题。K2 Thinking 在训练后阶段采用了量化感知训练(QAT),对 MoE 组件应用进行 INT4 权重量化。这使得 K2 Thinking 能够在原生支持 INT4 推理的同时,将生成速度提升约 2 倍,并达到目前最先进的性能。
它标志着月之暗面在测试时扩展方面的最新努力,通过扩展思考 token 和工具调用步骤,实现了更加高水平的智能。
据 CNBC 报道,Kimi K2 Thinking 模型的训练成本为 460 万美元。
模型发布后,知名 AI 学者 Sebastian Raschka 分析了新模型的结构,他表示其中包含更多专家,更少的人为干预,这让模型实现了更多的思考。
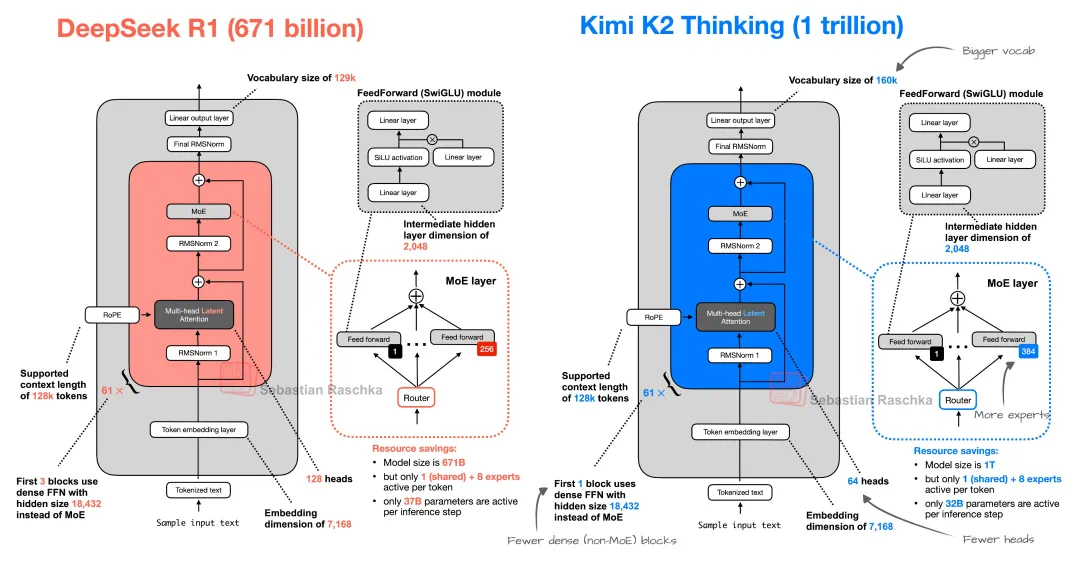
K2 Thinking 的上下文长度应为 256K。
另一个重点在于,K2 Thinking 在思考的过程中,会一直不断地与外界信息进行交互。
月之暗面的创始人杨植麟曾表示,基于多轮的 Agent(智能体)强化学习范式,或者通过强化学习技术训练出来的 Agentic 模型,其特点是会跟外界做很多交互。比如边思考边去做一些操作,可能做很多轮操作,一会儿调用一个搜索,一会儿使用一下浏览器,一会儿写几行代码,通过多轮解决一个问题。
这样,AI 就不再是「缸中之脑」,而是跟外界保持着交互——它的下一步行为,是根据交互得到的反馈,和外界持续更新的状态息息相关。
没有超强的感知,就不会有超级智能。
AI 的临界点提前来了?
Kimi K2 Thinking 发布后,知名 AI 基准测试机构 Artificial Analysis 发表了长文介绍新模型的能力,表示该模型的位置已经可以放在 GPT-5 之前。
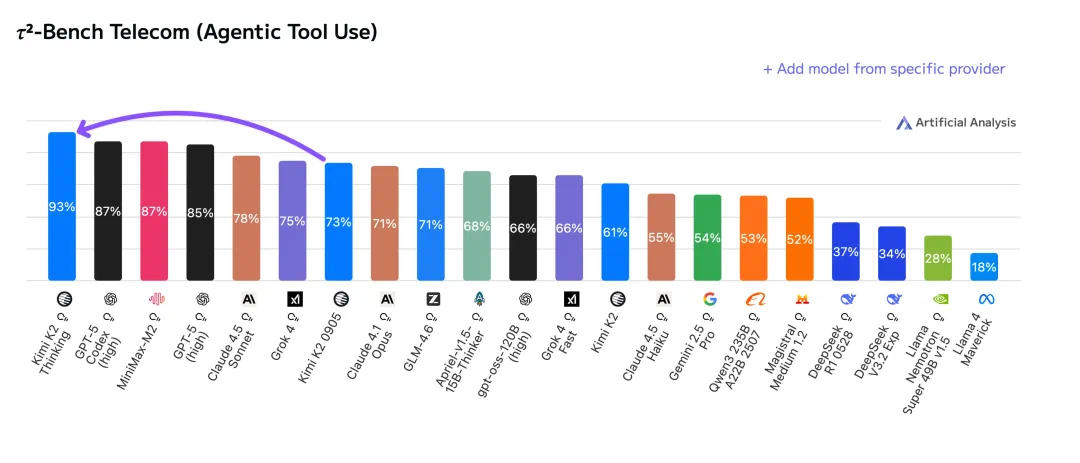
这不由得让我们回想到今年 7 月,Grok 4 发布的时候。xAI 的科学家们当时表示,在 HLE 成绩上,OpenAI 的深度研究、Gemin 2.5 Pro 和 Kimi-Reseracher 都是重要的发展节点。如今,Kimi K2 Thinking 作为一款开源大模型,成绩已经大幅超越了闭源的 Grok 4,我们又迈上了一个新的台阶。
或许用不了多久,AI 社区就需要设计一款新基准了。
而对于普通人来说,有这样一款高智商速度又快的大模型存在,意味着很多以前无法想象的 AI 应用方式会成为现实。
最后,我们知道 Kimi K2 Thinking 是开源的:月之暗面已在 Hugging Face 上正式发布了该模型,并采用了修改后的 MIT 许可证。该许可授予完整的商业和衍生权利——这意味着不论是开发者、研究人员还是公司,都可以自由访问并将其用于商业应用,这使得 K2 Thinking 成为了目前授权最宽松的前沿模型之一。
但增加了一项限制:
「如果该软件或任何衍生产品每月活跃用户超过 1 亿,或每月收入超过 2000 万美元,则部署者必须在产品的用户界面上明显位置标上『Kimi K2』。」
未来的爆款 AI 应用上,会有这样的「免费广告」出现吗?


