近日,Hugging Face更新了月度榜单,智源研究院的BGE模型登顶榜首,这是中国国产AI模型首次成为Hugging Face月榜冠军。BGE在短短一年时间内,总下载量已超数亿次,是目前下载量最多的国产AI系列模型。
BGE,全称BAAI General Embedding,是北京智源人工智能研究院研发的开源通用向量模型,该系列模型专为各类信息检索及大语言模型检索增强应用而打造。
自2023年8月发布首款模型BGE v1,历经数次迭代,BGE已发展为全面支持“多场景”、“多语言”、“多功能”、“多模态”的技术生态体系。BGE不仅性能综合卓越,多次大幅刷新BEIR、MTEB、C-MTEB等领域内主流评测榜单,而且始终秉持彻底的开源开放的精神,“模型、代码、数据”向社区完全公开。BGE在开源社区广受欢迎,许多RAG开发者将其比作信息检索的“瑞士军刀”。

除了个人用户,BGE亦被国内外各主流云服务和AI厂商普遍集成,形成了很高的社会商业价值。
通用向量模型:为RAG提供一站式信息检索服务
时代背景
检索增强(RAG: retrieval-augmented generation)是自然语言处理与人工智能领域的一项重要技术:通过借助搜索引擎等信息检索工具,语言模型得以与外部数据库连通,从而实现推理能力与世界知识的整合。
早在2019年至2020年,谷歌与Meta的研究人员就在多项独立的研究工作中提出了该项技术。此后数年间,RAG被逐渐应用于问答、对话、语言模型预训练等许多场景。
然而,RAG技术真正得到广泛认知则是源于2022年11月ChatGPT的发布:大语言模型为社会大众带来了前所未有的智能交互体验。由此,行业开始思考如何应用该项技术以更好的促进生产力的发展。
在众多思路中,RAG技术是大语言模型最为成功应用范式之一。借助RAG这一工作模式,大语言模型可以帮助人们以非常自然的方式与数据进行交互,从而极大提升获取知识的效率。与此同时,RAG还可以帮助大语言模型拓展知识边界、获取实时信息、处理过载上下文、获取事实依据,从而优化事实性、时效性、成本效益、可解释性等关键问题。
向量检索
经典的RAG系统由检索与生成两个环节所构成。大语言模型已经为生成环节提供了有力的支撑,然而检索环节在技术层面尚有诸多不确定性。
相较与其他技术方案,向量检索(vector search)因其使用的便捷性而广受开发者欢迎:借助向量模型(embedding model)与向量数据库,用户可以构建本地化的搜索服务,从而便捷的支撑包括RAG在内的诸多下游应用。
在RAG兴起的2023年初,向量模型作为技术社区首选的信息检索工具被广泛使用,一时间风光无二。然而空前的热度背后,向量模型的发展却较为滞后。
传统的向量模型多是针对特定的使用场景、以点对点的方式开发得到的。在面对RAG复杂多样的任务诉求时,这些专属的向量模型由于缺乏足够的泛化能力,检索质量往往差强人意。此外,与许多其他领域的问题类似,传统向量模型的研发多围绕英文场景,包括中文在内的非英文社区更加缺乏合适的向量模型以及必要的训练资源。
通用模型
针对上述问题,智源提出“通用向量模型”这一技术构想。目标是实现适应于不同下游任务、不同工作语言、不同数据模态的模型体系,从而为RAG提供一站式的信息检索服务。实现上述构想在算法、数据、规模层面存在诸多挑战,因此,智源规划了多步走的策略。
首先,着眼于“任务统一性”这一可实现性最强同时需求度最高的能力维度,即打造适用于中英文两种最重要语种、全面支持不同下游任务的向量模型。
该系列模型被命名为BGE v1,于2023年8月份完成训练并对外发布。BGE v1经由3亿规模的中英文关联数据训练得到,可以准确表征不同场景下数据之间的语义相关性。主流基准MTEB(英文)、C-MTEB(中文)的评测结果显示,BGE v1的综合能力与各主要子任务能力均达到当时SOTA,超过了包括OpenAI Text-Embedding-002在内的众多高水平基线。其中,BGE v1在中文领域的优势尤为显著。这在很大程度上填补了中文向量模型的空白,极大的帮助了中文社区的技术开发人员。
第二,在实现任务层面的统一之后,新一版模型的迭代着眼于实现“语言统一性”。为此,智源推出了BGE M3模型,可支持100多种世界语言的统一表征,并实现各语言内部(多语言能力)及不同语种之间(跨语言能力)的精准语义匹配。
为了充分学习不同语言中的隐含信息,BGE M3模型使用了超过10亿条的多语言训练数据,并利用了大量机器翻译数据。这一训练数据的规模、质量、多样性都明显超过了此前提出的多语言向量模型。除了多语言能力,BGE M3模型还创造性的整合了向量检索、稀疏检索、多向量检索,首次实现了单一模型对三种主要检索能力的统一。同时借助位置编码及训练效率的优化,BGE M3的最大输入长度得以拓展至8192个词元(token),有效的支持了句子、篇章、以至超长文档等诸多不同粒度的检索对象。
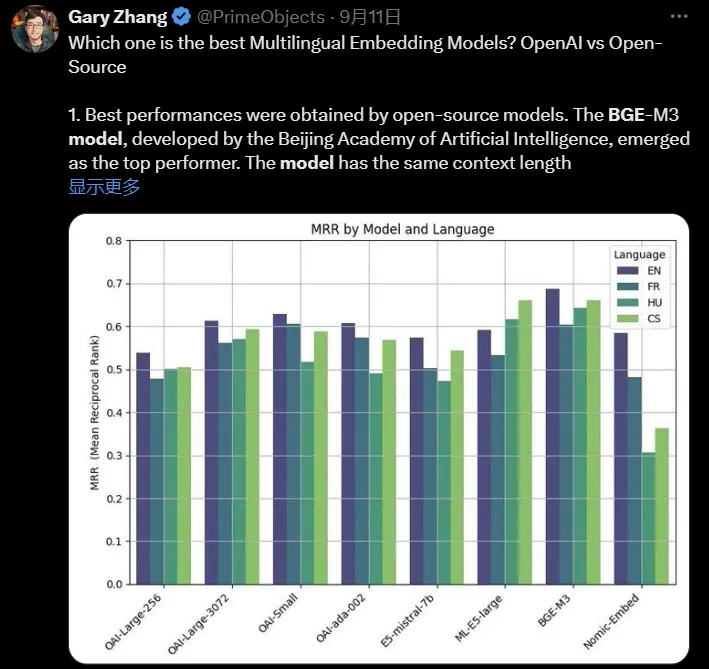
BGE M3模型在2024年2月完成训练并对外发布。其检索质量显著超越了同一时期发布的OpenAI Text-Embedding-003模型,在MIRACL、MKQA等主流评测基准的效果均达到业内最佳。与此同时,其支持的语种范围也远超其他同类模型,对于很多语言,BGE M3的能力甚至超越了该语言此前的专属向量模型。
BGE M3一经发布便广受好评,一度位居Hugging Face Trending前三位、Github Trending前五位。Zilliz、Vespa等业内主要的向量数据库第一时间便对BGE M3进行了集成及商业化应用。
第三,基于初步的阶段性成果,BGE模型进一步发展出多个衍生版本。
其中,BGE-re-ranker、BGE-re-ranker-m3旨在实现精准排序功能,以支持多阶段、细粒度的语义检索任务。BGE visualized在文本模型之上进一步拓展视觉数据处理能力,从而实现多模态混合检索能力。BGE-ICL则首次使得向量模型具备了上下文学习能力,使之可以依照用户意图灵活适配下游任务。
相关模型不仅持续刷新MTEB在内的多个主要基准的最高记录,同时带来了算法层面的诸多创新,在海内技术社区引起广泛讨论。
社区应用
开源是智源研究院大模型研发的一贯立场。本着这一原则,BGE的模型权重、推理及训练代码、训练数据均面向社区开放。与此同时,研发团队致力于不断推动创新研究,并积极通过技术讲座、研讨会、hands-on tutorial等形式与社区互动,帮助向量检索、RAG等技术的不断发展。
BGE系列模型遵循开放的MIT许可协议,社区用户可以对其自由的使用、修改、并进一步分发。除了众多个人用户,BGE的另一大使用群体来自于社区中热门的向量数据库(如Milvus、Vespa、Pinecone)以及RAG开发框架(如Langchain、Llama Index、RAGFlow)。国内外各大云服务厂商也纷纷提供BGE的商业化服务API,这不仅进一步促进用户使用,同时创造了较高的社会商业价值。
自2024年初至今,BGE系列模型的累计下载量已超过1亿次,成为下载量最多同时也是首个下载量超过一亿次的国产开源AI模型。
未来演进:从通用向量模型到通用搜索智能
在过去一年时间里,包括智源在内的多家机构都在致力于开发“好用且易用”的检索工具,以推动相关领域的学术研究与产业应用。随着BGE等模型的不断发展,这一目标在2024年底已初步实现:对于大多数应用场景、工作语言、数据模态,开发者都可以比较容易的获取相应的开源检索工具。与此同时,RAG产业的发展也方兴未艾:各个大模型厂商都将RAG作为主要商业模式赋能千行百业,Perplexity、New Bing等基于检索增强的AI搜索引擎也为人们带来了全新的搜索体验。
然而应用侧繁荣的背后隐藏着技术层面的发展陷入相对停滞。相较于基础大模型、多模态等领域,信息检索在近期内鲜有激动人心的技术进展。
几朵乌云
在应用于RAG任务时,有三个关于检索工具的“小问题”常被提及。
一是领域适配问题:通用的向量模型在处理某些特定领域的问题时效果不佳,需要经过进一步微调方可达到可用的状态。
二是切片问题:过长的上下文需要经过切片、并独立编码,方可在RAG过程中进行使用;但是,最佳的切片尺寸往往难以选择。
三是控制机制问题:什么时候需要做检索,拿什么内容去做检索。
这几个小问题常在工程层面进行被讨论,但其背后暗含着传统检索工具(向量模型、排序模型)本质性的技术限制。
其一是静态属性。以传统的向量模型为例:输入数据会被单向性、一次到位地映射为高维向量。
无论是用户还是模型自身并不能自主依据不同任务、不同场景对模型功能进行自适应的调整。虽然此前曾有也学者提出使用提示指令(instruction)对模型进行个性化调整,但后来的实验证明,传统模型仅是机械性的记住了训练时见到过的指令,并不能像GPT那样泛化出一般性的指令遵循能力,唯有不断微调模型参数方可使之适应于新的任务场景。
因此,当前一众的通用向量模型处处都可用、但效果并非最佳。从搜索的全局视角看,他们更应该作为一种局部性的技术手段。
其二是机构化限制。当代的信息检索技术多发展自互联网的场景,因此都隐含着对数据的结构化或者半结构化的建设。
比如:一个网页、一条新闻或者一个维基段落就是一个独立的信息单元。数据天然就是可切分的,或者说数据存在平凡的切分最优解(trivial solution for optimal chunking)。
因此,传统的信息检索手段能够比较容易对数据进行编码与索引。但是这一假设在RAG场景中完全不适用。
数据会是一个超长的词元序列(如pdf文件、长视频、代码仓库、历史交互记录),而非按照某种结构定义好的知识。数据不存在所谓最优的切片策略:人们固然可以遵循某种归纳偏执对非结构化数据进行切片,但是对于某个问题有利的上下文切片策略,换做另一个问题就可能是一个非常糟糕的策略。
其三是僵化的工作机制。传统的信息检索主要针对“一问一答”这一固定的工作模式。用户需要较为清晰地表述“自己需要获取信息”以及“需要获取什么样的信息”。
也正是由于这样的限制,当前的RAG应用依然局限于简单的问答场景(quesiton-answering),在更加普遍的任务中尚不能获得取得令人满意的结果(如代码仓库的上下文管理、长期记忆、长视频理解)。
通用搜索智能
通用搜索的终极目标是能够在“任何场景、任何任务中,精准获取所需的各种形态的信息”。因此,理想的信息检索工具应具备主动发掘任务需求的能力,并能根据不同的应用场景进行自适应调整。同时,还要能够高效处理自然状态下的数据——无论是非结构化还是多模态的数据。
如何构建通用搜索智能仍然是一个未解的难题,而有效地改造和利用大模型将是实现这一目标的关键。
大模型的应用将为信息检索带来显著优势。与传统静态检索模型不同,大模型具有动态性:它们能够根据具体任务的输入进行调整,甚至通过自我提示和反思等机制进一步优化,进而更好地适应任务需求。此外,大模型能够自然处理非结构化和多模态数据,并具备主动发起信息需求的能力。
值得注意的是,2024年初曾爆发过关于RAG(检索增强生成)与长上下文大模型的讨论,表面上这两者似乎存在冲突,但实际上并无矛盾:语言模型直接处理海量信息的效率较低,必须借助有效的信息检索工具;而传统的信息检索工具智能化不足,需要更智慧的中枢来加以驱动。
因此,未来通用搜索智能的实现,依赖于大模型与检索工具的深度融合。


