在AI数据中心中,网络链路的高故障率一直是制约算力释放的关键困局。传统光纤链路故障率是铜缆的100倍以上,10万GPU规模的AI集群甚至每6-12小时就会出现链路故障,导致同步性极强的AI训练任务中断,造成巨大算力浪费。
在9月葡萄牙召开的“ACM SIGCOMM 2025”大会上,微软研究院公布了突破性技术MOSAIC,凭借宽通道慢速率架构与microLEDs创新组合,一举将链路故障率降低100倍。
这不仅破解了AI数据中心的链路故障难题,还同步实现50米长距传输,为铜缆10倍、最高68%功耗降低,可无缝兼容现有网络协议与硬件,为大规模AI集群的稳定运行与高效扩容提供了关键技术支撑。

在当今AI数据中心网络中,传统的链路技术面临着一个难以调和的矛盾:铜缆链路虽然能效高且可靠,但传输距离极短,通常不超过 2 米,限制了其在单个机架内的使用;而光纤链路虽然能够跨越数十米的距离,却以高功耗和低可靠性为代价。
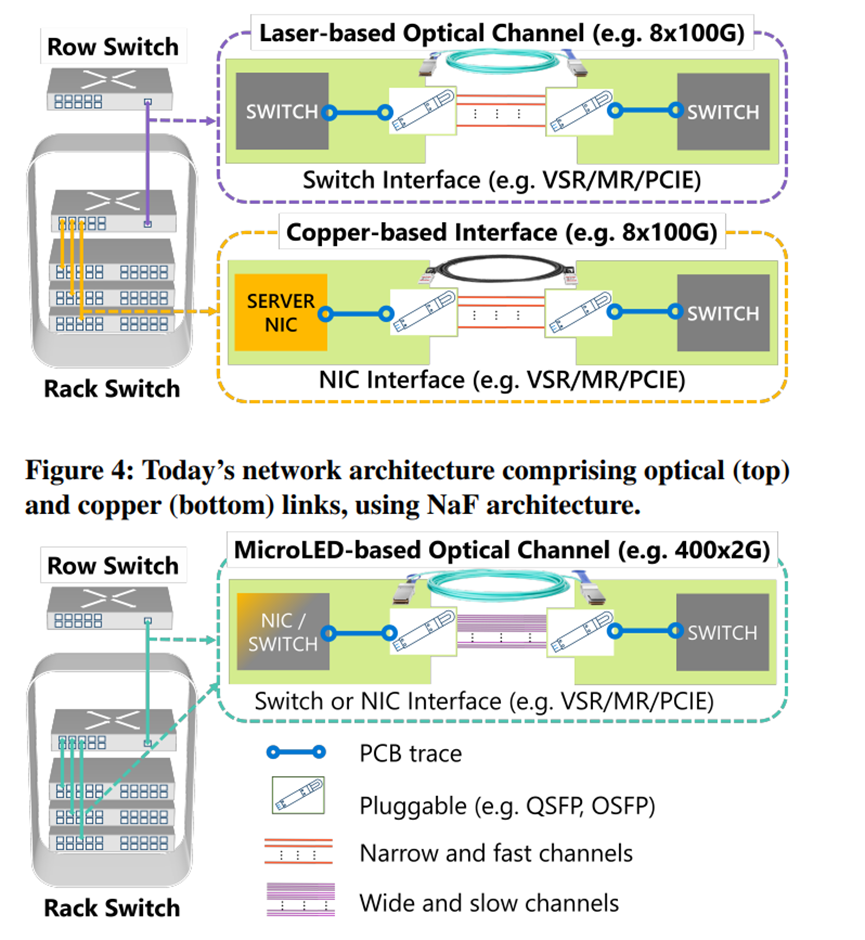
MOSAIC 的核心架构与传统的“窄且快”(Narrow-and-Fast,NaF)架构截然不同。传统的 NaF 架构依赖于少数几个高速串行通道来实现高带宽传输,例如一个800Gbps 的链路可能仅使用 8 个 100Gbps 的通道。这种架构在高速传输时面临着诸多问题,包括铜缆链路的信号衰减加剧导致传输距离受限,光纤链路的功耗急剧上升以及可靠性降低。
而 MOSAIC 的 WaS 架构则采用了数百个并行的低速光学通道,每个通道的数据速率相对较低,例如在 MOSAIC 的原型中,每个通道的传输速率为 2Gbps。
这种架构转变带来了诸多显著优势。首先,低速传输显著提高了能效,与传统光纤链路相比,MOSAIC的功耗降低了高达 68%。其次,通过采用光学传输,MOSAIC避免了铜缆链路的传输距离限制,能够支持长达 50 米的传输距离,这比铜缆链路的传输距离长出了 10 倍以上,与目前的 AOC 光纤链路相当。
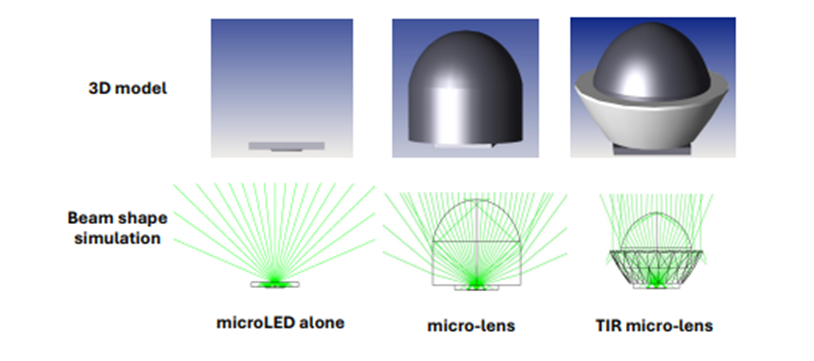
第三,微 LED 比激光器更为可靠,因为它们结构更简单,对温度变化不敏感。WaS 架构的并行性使得添加冗余通道变得轻而易举,进一步提升了可靠性,比 AOC 光纤链路高出两个数量级。WaS 架构还具有良好的可扩展性,通过增加通道数量和 / 或提高单通道速率,例如提升至 4-8Gbps,可以轻松实现更高的聚合速率,如 1.6Tbps 或 3.2Tbps。
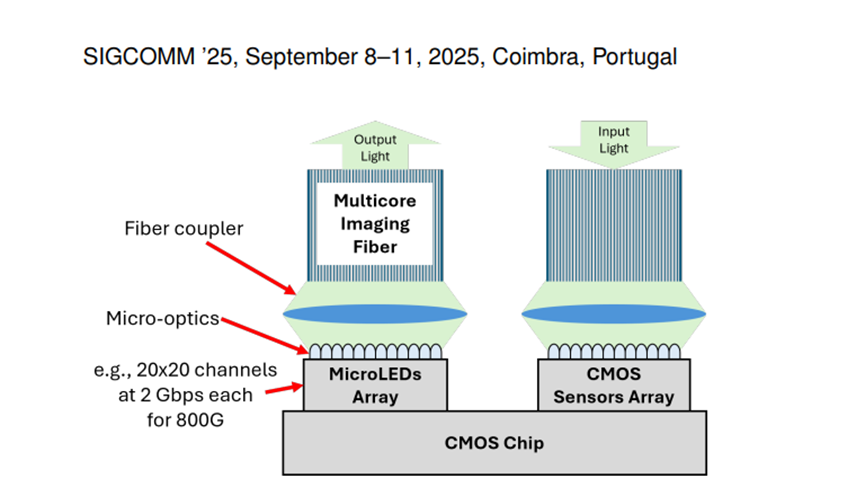
微 LED 是 MOSAIC 技术的关键组成部分之一。与传统用于照明的标准 LED 相比,微 LED 的尺寸要小得多,通常在几微米到几十微米之间。微 LED 的小型化使其能够在简单地开关调制方案下以数 Gbps 的速率进行调制,并且由于其小尺寸,可以以大规模阵列的形式制造,例如,在不到 1 毫米×1 毫米的芯片面积上集成超过50 万个微 LED,用于高分辨率显示设备,如头戴式显示器或智能手表。
对于 MOSAIC 来说,使用小型微LED 阵列就足以实现高聚合速率的传输。例如,假设每个微 LED 通道的速率为 2Gbps,那么一个 800Gbps 的 MOSAIC 链路可以通过一个 20×20 的微 LED 阵列来实现。
微 LED 的另一个重要优势在于其工作在可见光范围,这使得可以使用低成本的 CMOS 传感器作为接收器,类似于手机摄像头中的传感器。这种 CMOS 传感器与微 LED 的结合不仅降低了成本,还因为它们共享相同的 CMOS 技术,使得接收端的电子后端能够实现更紧密的集成,包括单片设计,即在一个硅片上集成所有的模拟电子元件和光电探测器阵列。这种集成方式进一步减少了成本以及功耗。
此外,在传统的光纤通信中,通常使用单芯光纤来传输信号。但对于 MOSAIC 这种拥有数百个并行通道的架构来说,如果为每个通道都使用单独的光纤,将会导致成本和复杂性急剧增加。因此,MOSAIC 采用了多芯成像光纤来解决这一问题。
考虑到光纤中纤芯数量的丰富性,团队并没有采用一对一地将每个微 LED 映射到一个纤芯的方案,而是选择将一个微 LED 映射到多个纤芯上。这种设计方式显著降低了对光纤与微 LED 对准精度的要求,从而进一步降低了整体的复杂性和成本。
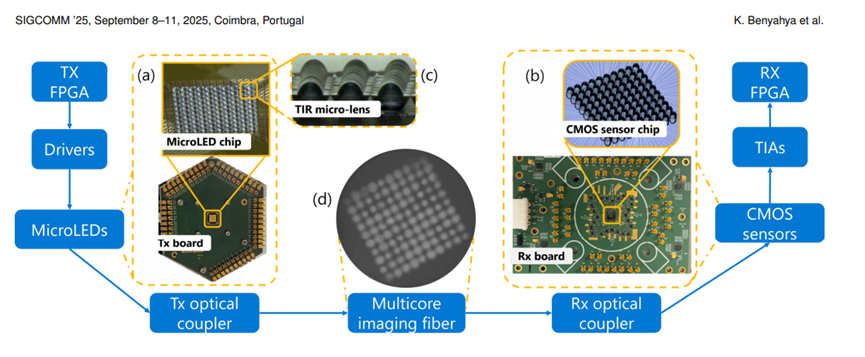
与使用多根离散光纤相比,多芯成像光纤采用单次制造工艺,确保了所有纤芯在传输特性上的高度一致性,并且所有纤芯的长度也几乎完全相同。结合相对较低的单通道数据速率,这使得通道间的时序偏差可以忽略不计。例如,即使假设存在 1 厘米的长度差异,在光纤中的光传播速度为 5ns/m 的情况下,所产生的延迟差异仅为 50ps。这仅相当于单通道数据速率 2Gbps 下比特周期的 10%,这样的偏差是可以轻松容忍的。
为了测试MOSAIC性能,研究团队构建了包含 100 个通道的原型,每个通道传输速率为 2Gbps。测试结果显示,在传输距离方面,它突破了铜缆局限,实现 50 米传输,远超铜缆通常不超 2 米的距离。功耗上,800Gbps 链路单端功耗仅 3.1 - 5.3W,较传统光纤链路降低 56 - 68% 。
通过 15% 冗余通道及热备用设计,结合微 LED 自身特性,故障率比现有 AOC 光纤链路低 100 倍。在30 米光纤实际测试中,2Gbps / 通道传输稳定,误码率<2×10⁻⁸ 。模拟显示,50 米距离内 800Gbps 可插拔模块以 2Gbps / 通道传输,误码率<10⁻⁶ ,展现出长距、低耗、高可靠的卓越性能 。


