嘿,大家好!这里是一个专注于前沿AI和智能体的频道~
谷歌 DeepMind 和 MIT 联合发了一篇论文,名叫 TUMIX(Tool-Use Mixture)。
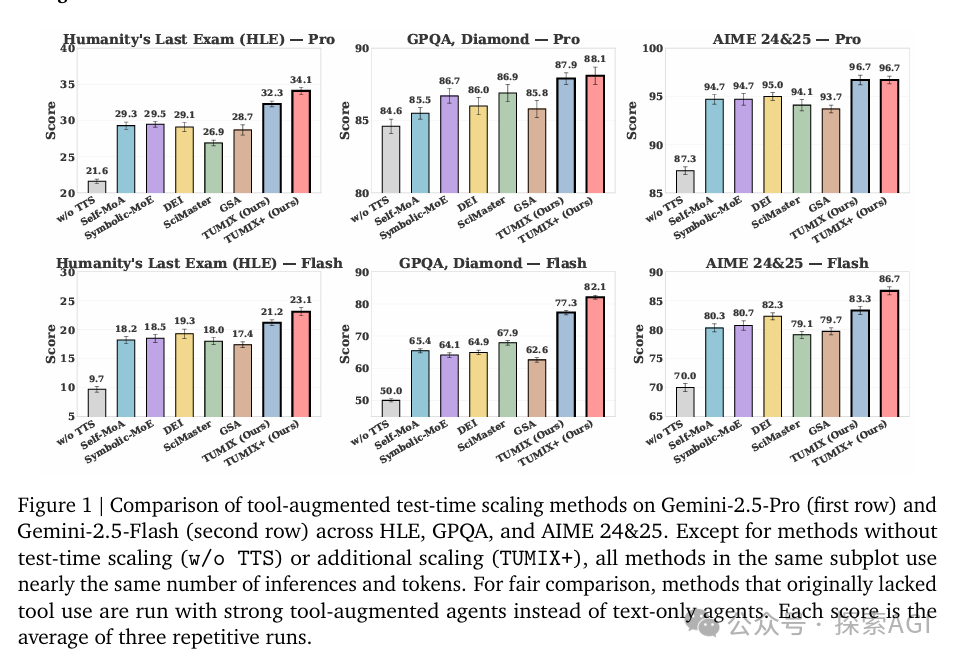
大概就是说,Multi-Agent 才是 test-time- scaling的终极打开方式,可以以一半的成本,在HLE上,准确率从 21.6% 飙升到 34.1%,超越 Gemini-2.5-Pro Deep Research。
除此之外,他们还做了一个彩蛋,让Agent设计Agent,效果比人工设计的更牛~
 图片
图片
一个反常识
Agent多样性 > 疯狂采样
目前主流的推理时扩展方法是什么?
重复采样同一个最强模型,然后用多数投票选答案。
感觉也没毛病,但谷歌验证后,说:错了。
他们做了个实验:
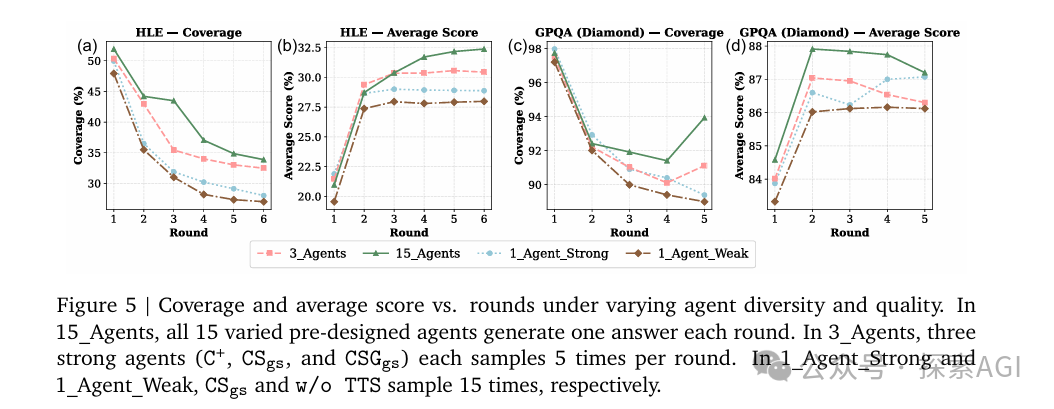
- 单Agent重复15次 vs 15个不同Agent各推理1次
- 在相同的推理成本下,15个不同Agent的准确率和覆盖率都明显更高
为什么呢?
因为不同Agent采用不同的工具使用策略(纯文本推理、代码执行、网页搜索、双工具混合等),能探索更广阔的解空间。而单Agent重复采样,本质上还是在同一个思维框架里打转。
 图片
图片
他们还对比了三种工具组合:
- Code_Text(只能用代码,不能搜索)
- Search_Text(只能搜索,不能用代码)
- Code_Search_Text(两者都能用)
结果,双工具Agent组的覆盖率和准确率都显著高于单工具组。
这说明什么?Code Interpreter 和 Search 不是互相替代的关系,而是互补的。
文本推理擅长语义和常识,代码擅长精确计算,搜索擅长获取最新知识。只有三者混合,才能发挥LLM的全部潜力。
TUMIX的核心机制
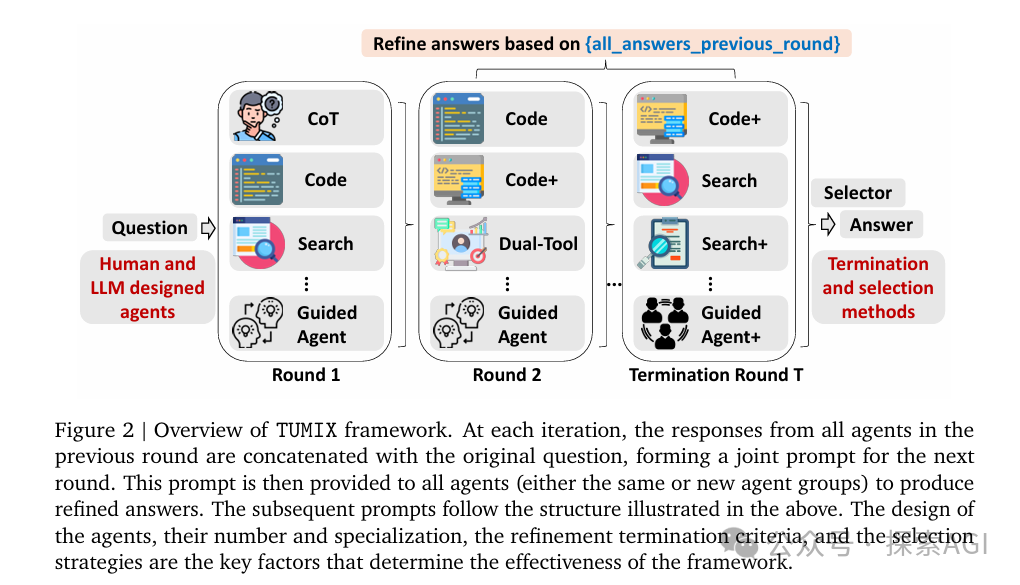
TUMIX的架构其实不复杂,核心就三步:
第一轮
15个不同Agent并行推理。
每个Agent有自己的工具使用策略(CoT、纯代码、搜索优先、代码搜索混合、引导式双工具等)
每个Agent最多可以调用工具5次,生成15个初步答案
第二轮及之后
答案共享 + 迭代优化:
把上一轮所有Agent的答案拼接到原问题后面,每个Agent基于原问题+其他Agent的答案生成新答案。
重复这个过程,直到LLM判断答案已收敛。
终止
LLM-as-Judge,用LLM自动判断何时停止迭代(最少2轮),最终通过多数投票选出答案
 图片
图片
这个设计既保留了多样性探索,又通过迭代优化提升了答案质量。
他们还发现了一个有趣的现象:随着迭代轮次增加,覆盖率(至少有一个Agent答对)会下降,但平均准确率会上升。
这说明Agent们在互相学习的过程中逐渐趋同,但也会误删掉一些正确答案。
所以,关键是找到那个点——既充分迭代优化,又不过度收敛。
最后
来看看TUMIX的实战表现:
在Gemini-2.5-Pro上,HLE从21.6%提升到32.3%,GPQA从84.6%提升到87.9%, AIME 24&25,从87.3%提升到96.7%。
对比其他Test-time Scaling方法(Self-MoA、Symbolic-MoE、DEI、SciMaster、GSA),TUMIX在相同推理成本下,平均准确率都有明显优势。
 图片
图片
LLM可以自动设计更强的Agent?
论文里还有个彩蛋:他们尝试让 Gemini-2.5-Pro 自己设计新的Agent。
做法很简单:
- 给LLM看现有的15个人工设计的Agent
- 让它生成更多样、更高质量的Agent
- 从生成的25个新Agent中筛选出表现最好的15个
结果呢?
混合了人工设计和LLM生成的Agent组,性能比纯人工设计的还要高1.2%。
LLM生成的Agent长什么样?比如:
- Plan-Verify-Refine:先规划、再执行(代码或搜索)、然后验证并优化
- SearchThenCode:强制先搜索、再用代码
- Debate-CrossExam:模拟提议者和怀疑者辩论,引导工具使用
这些策略和人工设计的完全不同,说明LLM已经具备了一定的Meta-Agent设计能力。
最后
OpenAI o1 和 DeepSeek R1 的路线是让单个模型深度思考,本质上还是在同一个推理框架内扩展。
TUMIX告诉我们,通过多样化的Agent和工具混合,可以用更低的成本达到更好的效果。
同时,LLM可以设计更强的Agent架构,这意味着,未来的AI系统可能会自己优化自己的工作流,而不需要人工调参。


