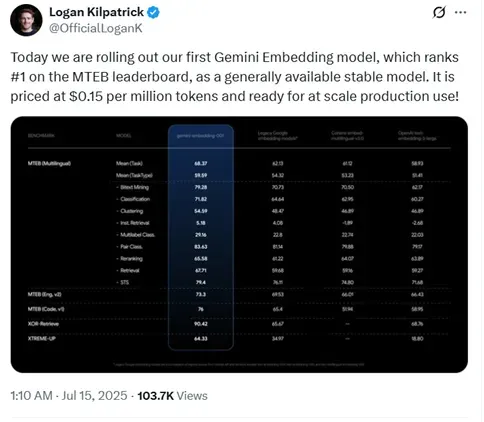
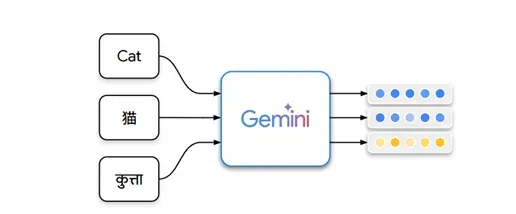
今天凌晨1点,谷歌发布了首个Gemini嵌入模型刷新了MTEB榜单记录成为第一,并且价格很便宜每100万token只要0.15美元,已经开放API。
根据谷歌在多文本嵌入基准测试平台MTEB上的测试结果显示,Gemini嵌入模型平均分达到了68.37,大幅度超过了OpenAI文本嵌入模型的58.93分。
在双语挖掘、分类、聚类、指令检索、多标签分类、配对分类、重排、检索、语义文本相似性等测试中,全部都非常出色成为目前最强嵌入模型。
免费体验地址:https://aistudio.google.com/prompts/new_chat
对于谷歌的新模型,网友表示,大多数人都低估了嵌入技术的强大之处,但它们却是更智能的人工智能工作流程的核心支柱。
搜索、聚类、个性化推荐,甚至将博客内容与用户意图进行匹配,所有这些应用都会因嵌入技术而得到改进。
凭借每100万token 0.15美元的价格,独立创作者和自由职业者终于也能使用这项技术了。这是一项重大举措。
这太棒了!我的很多学生都问过我最好的嵌入模型是什么,所以很高兴看到 Gemini 有了自己的嵌入模型。Gemini 模型很可能与这些嵌入模型配合得很好,而且成本也还不错。
多语言能力对于在全球范围内的应用至关重要,因为有大量人口的母语并非英语。我一直认为谷歌在最先进的自然语言处理方面具有优势。很高兴看到 Gemini 在 MTEB中也位居榜首,而且其成本效益也不错。
Gemini嵌入模型简单介绍
Gemini嵌入模型的架构设计基于 Gemini的双向Transformer 编码器。这种设计保留了Gemini的双向注意力机制,使得模型能够充分利用其预训练的语言理解能力。
Gemini嵌入模型以Gemini的底层32层Transformer为基础,这些层被冻结,以确保模型能够继承 Gemini 的强大语言理解能力在这些冻结的层之上,模型添加了一个池化层,用于将输入序列的每个token嵌入进行聚合,生成一个能够代表整个输入的单一嵌入向量。
为了实现这一点,模型采用了简单的均值池化策略,即对输入序列的所有 token 嵌入沿序列轴进行平均处理。这种池化方法不仅简单高效,而且在模型适应性方面表现出了良好的效果。
在池化层之后,模型通过一个随机初始化的线性投影层,将嵌入向量的维度调整为目标维度。这一设计使得模型能够灵活地输出不同维度的嵌入,例如,768 维、1536 维或 3072 维。为了支持这种多维度的嵌入输出,Gemini嵌入模型引入了MRL技术。
MRL 技术允许模型在训练过程中同时优化多个子维度的嵌入,例如,先优化前 768 维,再优化前 1536 维,最终优化完整的 3072 维。这种多维度训练策略不仅提高了模型的灵活性,还增强了其在不同任务中的适应性。
在训练过程中,Gemini 嵌入模型采用了噪声对比估计(NCE)损失函数,这是一种广泛应用于嵌入模型训练的技术。NCE 损失函数的核心思想是通过对比正样本和负样本来优化嵌入空间,使得语义相似的文本在嵌入空间中彼此接近,而语义不同的文本则彼此远离。
每个训练样本包括一个查询、一个正样本以及一个可选的硬负样本。模型通过计算查询向量与正样本向量之间的相似度,并将其与负样本向量的相似度进行对比,从而优化嵌入空间。
为了进一步提升模型的性能,Gemini 嵌入模型在训练过程中采用了多维度的 NCE 损失函数。通过 MRL 技术,模型能够同时优化多个子维度的嵌入,例如 768 维、1536 维和 3072 维。这种多维度训练策略不仅提高了模型的灵活性,还增强了其在不同任务中的适应性。
此外,Gemini 嵌入模型 在损失函数中引入了一个掩码机制,用于处理分类任务中目标数量较少的情况。这种掩码机制能够有效避免在计算损失时出现重复计算的问题,从而提高模型的训练效率。
训练数据
研究团队针对检索任务和分类任务分别设计了不同的合成数据生成策略。对于检索任务,团队扩展了先前的工作,采用 Gemini 生成合成查询,并通过 Gemini 自动评分器过滤低质量的示例。
首先利用 Gemini 生成与给定段落相关的查询,然后通过另一个 Gemini 模型对生成的查询进行评分,以确保其质量和相关性。通过这种方式,团队能够生成大量高质量的检索任务数据,从而提升模型在检索任务中的表现。
对于分类任务,团队则采用了更为复杂的多阶段提示策略。他们首先生成合成的用户画像、产品信息或电影评论等数据,然后在此基础上生成具体的分类任务数据。
例如,在生成情感分类数据时,团队会先生成一系列带有情感倾向的用户评论,再从中筛选出符合特定情感标签的样本。这种多阶段的生成策略不仅增加了数据的多样性,还能够根据需要调整数据的分布,从而更好地适应不同的分类任务。
为了提高训练数据的质量,研究团队利用 Gemini 对训练数据进行过滤。通过基于少数样本提示的数据质量评估,识别并移除低质量的样本。主要利用 Gemini 的语言理解能力,对数据集中的样本进行逐个评估,判断其是否符合预期的质量标准。
例如,在检索任务中Gemini 会评估查询与正样本之间的相关性,以及查询与负样本之间的不相关性。
如果某个样本的质量不符合要求,例如,查询与正样本之间的相关性过低,或者查询与负样本之间的不相关性过高,那么这个样本就会被标记为低质量样本并从训练数据中移除。
训练方法
Gemini嵌入模型的训练流程主要分为预微调和精调两大阶段。在预微调阶段,模型使用大量潜在噪声的对进行训练。这些数据对来自一个大规模的 Web 语料库,通过标题和段落对的形式作为输入和正样本对。
预微调阶段的主要目标是将 Gemini 的参数从自回归生成任务适应到编码任务。因此,这一阶段采用了较大的批量大小(如 8192),以提供更稳定的梯度,减少噪声的影响。预微调阶段的训练步数较多,通常达到100 万步。
在精调阶段,模型进一步在包含查询,目标,硬负样本三元组的多种任务特定数据集上进行训练。这些数据集涵盖了检索、分类、聚类、重排、语义文本相似性等多种任务类型。
精调阶段采用了较小的批量大小(如256),并且限制每个批次只包含来自同一任务的数据。这种策略使得模型能够更好地专注于特定任务的优化,从而提高其在不同任务中的性能。
为了进一步提升模型的泛化能力,Gemini嵌入模型还采用了 Model Soup 技术。Model Soup 是一种简单的参数平均技术,通过对多个不同超参数训练得到的模型检查点进行参数平均,能够显著提升模型的性能。


