谷歌开源Gemma 3 270M闪亮登场!
只需几分钟即可完成微调,指令遵循和文本结构化能力更是惊艳,性能超越Qwen 2.5同级模型。
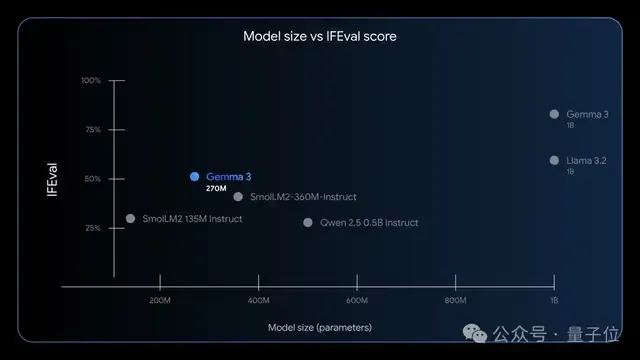
发布当天,网友也懵了:以为是270B,结果居然才0.27B。
此模型小巧又高效,可以直接在浏览器里本地运行,不用联网,也能生成有创意的内容,比如睡前故事。
不仅如此,还有人使用这款迷你模型构建了自己的OCR应用程序。上传一张图片或PDF文件,即可用LLM即时将其转换为结构化的Markdown格式。
值得一提的是,新模型只有4个注意力头,比Qwen 3 0.6B少12个,真是切实符合其轻量化的定位。
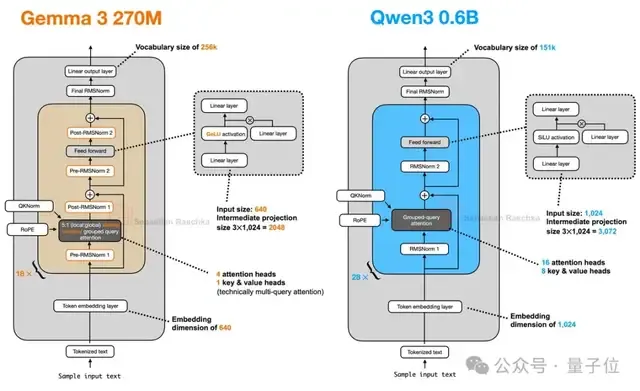
下面让我们一起看看这款迷你Gemma 3到底有哪些亮点?
就像你不会用大锤来挂相框,同样的原则也适用于利用人工智能。
Gemma 3 270M充分体现了这种“为工作选择合适工具” 的理念。
作为一款基础模型,它开箱即可精准遵循指令,而微调能彻底释放其真正实力。
经过专门优化,它在文本分类、数据提取等任务中,都能做到准确、快速且成本可控。
简单总结,新模型的核心功能可概括为以下4部分:
紧凑且高效的架构
这款新模型共包含2.7亿参数,其中1.7亿为嵌入层参数(由于庞大的词汇量),另外1亿为Transformer模块参数。
凭借25.6万token的庞大词汇量,该模型能够处理特定及罕见词汇,因此成为特定领域和语言中进一步微调的理想模型。
极致的能源效率
不仅如此,该模型的参数规模在终端运行毫无压力。
内部测试表明,在Pixel 9 Pro手机(SoC芯片)上运行INT4量化版时,25轮对话仅消耗0.75%电量,堪称能效最高的Gemma模型。
指令遵循
此次发布包含一个经过指令微调的模型及对应的预训练检查点,开箱即可精准遵循常规指令。
可用于生产的量化支持
此模型提供经过量化感知训练(QAT)的检查点,能让模型以INT4精度运行,且性能损耗微乎其微——这一点对于在资源受限设备上部署而言至关重要。
轻量化模型的强大威力在现实应用中已经得到了充分体现。
一个典型案例是2025年7月Adaptive ML与SK Telecom的合作,面对复杂的多语言内容审核挑战,他们选择了专门化策略:没有使用庞大的通用模型,而是对Gemma 3 4B模型进行了针对性微调。
结果令人惊艳,经过微调的专用Gemma模型不仅达到了目标任务的要求,甚至在特定任务上超越了许多体量更大的专有模型。
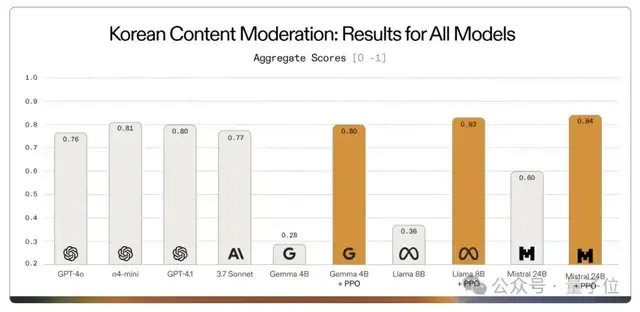
Gemma 3 270M旨在让开发者进一步采用这种方法,为明确界定的任务释放更高的效率。
那么,什么时候适合选择这款迷你版Gemma 3呢?
1、批量处理专业任务:此模型尤其适合处理情感分析、实体提取、查询路由、非结构化文本转结构化、创意写作及合规性检查等。
2、严格控制响应时间和成本:它能大幅降低甚至消除生产环境中的推理成本,同时为用户提供更快速的响应。
经过微调的270M模型可运行于轻量、低成本的基础设施,甚至能直接部署在终端设备上。
3、快速迭代和部署:Gemma 3 270M的小模型规模能够实现快速的微调实验,帮助你在数小时而非数天内找到适合你用例的完美配置。
4、确保用户隐私 :该模型可以完全在设备上运行,而无需将数据发送到云端。
5、多任务专业部署:这款迷你模型能帮你在预算范围内,构建并部署多个定制模型,并且每个模型都针对特定任务进行了专业训练。
下面想要快速上手Gemma 3 270M?超简单四步走起。
首先,你可以从Hugging Face、Ollama、Kaggle、LM Studio或Docker获取该模型。
接着用Vertex AI、llama.cpp、Gemma.cpp、LiteRT、Keras和MLX等工具进行测试。

然后使用Hugging Face、UnSloth或JAX等工具进行个性化微调。

最后,你可以将定制好的模型一键部署到本地环境或谷歌Cloud Run等任何环境。

参考链接:[1]https://x.com/rasbt/status/1956130338431713307 [2]https://x.com/osanseviero/status/1956024223773663291 [3]https://developers.googleblog.com/en/introducing-gemma-3-270m/


